diff --git a/Document/2023/0903/jincheol/.gitkeep b/Document/2023/0903/jincheol/.gitkeep
deleted file mode 100644
index e69de29..0000000
diff --git "a/Document/2023/0903/jincheol/[1\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(1-4\354\236\245).md" "b/Document/2023/0903/jincheol/[1\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(1-4\354\236\245).md"
new file mode 100644
index 0000000..09ac562
--- /dev/null
+++ "b/Document/2023/0903/jincheol/[1\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(1-4\354\236\245).md"
@@ -0,0 +1,235 @@
+# 1장 데이터베이스란 - 용도와 역할
+
+## 데이터베이스 기본기능
+
+### 데이터베이스 기본기능
+
+#### 1. 데이터의 검색과 갱신
+
+- 데이터베이스의 용도로써 가장 중요한 기능은 "검색" 이다.
+- 다시 말해 '원하는 데이터를 찾는다'는 것. (추출이라고도 함) EX) Google의 검색엔진.
+- 검색엔진은 방대한 데이터를 보존하는 DB에서 검색대상을 키워드로 히트한 데이터를 꺼내감.
+- 검색을 수행할 수단이 있다는 점이 DB에서 요구되는 가장 중요한 기능.
+
+ 넓은 의미에서 갱신은 등록/수정/제거
+
+- 등록,수정,제거 3가지 기능을 통틀어 '갱신'이라 일컫음.
+- 이렇게 넓은의미도 있지만, 좁은의미로서 '기존 데이터 수정'도 존재.
+- 데이터베이스에서 사용자가 수행하는 조작 : 검색과 갱신
+- 갱신 -> 등록,수정,제거의 하위단위로 재구성
+
+ 데이터 포맷에 유의한다
+
+- 데이터베이스를 조작할 떄 중요한 것은 데이터를 어떤 포맷(형식)으로 관리하는가, 검색이나 갱신에서 효율적인가 등의 문제 존재
+- 가령, 동성동명의 박XX 씨가 2명 존재하면 해당 2명은 다른 인물이기에 DB에서도 이 2명을 '다른 사람' 이라는 것을 알도록 관리해야함. (이러한 원칙을 고유성이라고함.)
+
+ 처리 성능에 유의한다
+
+- '어느 정도의 빠르기로 처리 가능한가'
+- 검색 성능을 어떻게 향상할 것인가 하는 주제는 영원한 숙제
+
+#### 2. 동시성 제어
+
+- 비지니스나 공공목적으로 이용하는 데이터베이스에는 불특정다수의 사용자가 동시에 접근하는 것이 보통.
+- 즉, 데이터베이스는 동시에 복수의 사용자로부터 검색/갱신 처리를 받음.
+- 이때 문제 되는 것이 '갱신의 무결성을 어느정도로 보장하는가?'
+
+ 동시성 제어 발생 가능 상황
+
+1. A : 파일보고 있음.. B : 파일 열 수 없음. (최초로 연 사람만이 읽을 수 있음)
+2. A : 파일보고 있음.. B : 오직 Read-Only만 가능
+3. A : 파일보고 있음.. B : 역시 파일 볼 수 있음 (데이터 반영은 "마지막"으로 수행된 동작 기준 적용)
+
+- B 입장에서는 '1'이 가장 행위 제한이 심하고 '3'이 가장 느슨.
+- 따라서 B 입장에서는 '3'이 가장 바람직한 상황
+
+- 그러나 A 입장에서는 '3'은 위험하고 의도하지 않은 상황.
+- 따라서, A의 바람직한 상황은 누구에게도 갱신을 방해받지 않는 '1'의 상황.
+
+- 데이터베이스를 복수의 사용자가 동시에 공유하고 이용하려면 '같은 데이터'를 갱신하는 상황에 대한 '제어'가 필요.
+- 어느 사용자는 OK , 다른 사용자는 NOT OK -> '트레이드오프 관계'
+- 이렇게 복수 사용자의 갱신을 조절하기 위한 기능을 데이터베이스의 중요한 두번째 기능인 '동시성 제어' 또는 '배타 제어'라고 함.
+
+#### 3. 장애 대응
+
+- 데이터베이스에 요구되는 세번째 중요 기능은 '장애애 강할 것'
+- 쉽게 말해 좀처럼 부서지기 어려우며 부서졌다 한들 복원 가능하다 라는 의미
+
+ 데이터 소실 문제 대책
+
+- 1. 데이터 다중화
+- 2. 백업
+
+#### 4. 보안
+
+- 데이터베이스에 보존된 데이터를 어떻게 숨길 것인가?
+- 사용자는 시스템 이용 시 데이터베이스의 존재를 의식할 일 거의 없음
+- 실제로 데이터베이스는 사용자로부터 가능한 보이지 않게 설계됨
+
+- 이유 1 : 사용자에게 가까운 기술이란 대다수가 클라이언트 기술 중심이라 서버의 기술은 그다지 의식되지 X
+- 여기서 클라이언트는 사용자가 직접 사용하는 단말기, 예를들면 PC, 태블릿, 스마트폰 등
+- 사용자로서 시스템 사용시 직접 조작하는 것은 어디까지나 클라이언트뿐이고 서버에 배치된 데이터베이스 등의 소프트웨어를 직접 조작하는 일은 없음
+
+- 이유 2 : 데이터베이스에 들어있는 데이터는 기밀성이 지극히 높아 일반에 공개할 수 없는 내용이 상당수 포함되어 있음.
+
+# 2장 관계형 데이터베이스란 - 가장 대표적인 데이터베이스
+
+## 관계형 데이터베이스란 무엇인가
+
+- 관계형 데이터베이스에서 말하는 '관계'란 단어는 보통 인간관계라든지 국제관계라고 할때 사용하는 관계란 단어와는 의미가 다름
+- 여기서 말하는 관계는 '2차원 표'를 표기할 때 사용하는 단어 EX) Excel, Google Docs 스프레드 시트
+- '데이터를 2차원 표를 사용해 관리하는 데이터베이스'
+
+## SQL 기초지식
+
+- SQL (Structured Query Language)
+- 4가지 기본 조작(검색,등록,갱신,제거)
+- SELECT, INSERT, UPDATE, DELETE
+
+### 테이블, 행, 열의 의미
+
+ 테이블
+
+- 2차원 표
+- 관계형 데이터베이스에서 데이터를 관리하기 위한 유일한 단위
+- 어떤 테이블에 어떤 데이터를 포함하는가는 시스템의 기능을 좌우하는 중요한 의미 내포
+- 테이블에 너무 많은 정보 -> 정보 정합성 유지 어려움
+- 데이터 너무 엄격하게 분산 -> 성능 저하
+
+### 관계형 데이터베이스를 다루기 위한 사전 지식
+
+ DBMS와 데이터베이스 차이
+
+- 데이터베이스라는 것은 기능이나 구조를 나타내는 '추상적인' 개념
+- DBMS는 그것을 실현하기 위해 작성된 구체적인 '소프트웨어'
+- 따라서 오라클,MySQL은 DBMS지 데이터베이스 X
+- 시스템 목적이나 규모에 따라 다르지만, 사용되는 소프트웨어은 크게 3가지로 나뉨 -> 1.운영체제 2.미들웨어 3.어플리케이션
+- DBMS는 '미들웨어'에 위치
+- 미들웨어(DB)는 OS에 설치하여 움직이는 걸 의미 (=OS에서 동작한다.)
+
+# 3장 데이터베이스에 얽힌 돈 이야기 - 초기비용과 운영 비용
+
+# P A S S
+
+# 4장 데이터베이스와 아키텍처 구성 - 견고하고 고속의 시스템을 구축하기 위해
+
+## 다중화에 대해 생각해보자
+
+- DB 2대 중 1대가 고장나도 다른 1대로 동작시켜 서비스 정지를 막을 수 있는데, 이것이 '다중화' 혹은 '고가용성'
+
+## 데이터베이스의 아키텍처
+
+ Stand-alone의 특징
+
+- 데이터베이스가 동작하는 머신이 LAN이나 인터넷 등의 네트워크에 접속하지 않고 '독립되어' 동작하는 구성
+- 이 구성에서는 데이터베이스의 미들웨어, 어플리케이션 소프트웨어가 같은 DB 서버에서 동작
+- 사용자는 직접 DB서버에 접근 필요.
+- 서버가 네트워크에 접속되지 않아서 물리적으로 떨어진 장소에서 접근도 불가능.
+- 나름의 장점은 구축이 간단해 소규모 작업이나 테스를 빠르게 할 수 있음
+- 성능이나 가용성 무시하면 노트북 사용해서도 만들 수 있음.
+- 보안이 높음. -> 직접 USB 메모리등을 사용하지 않는 이상 서버가 바이러스에 감염되거나 공격받는 일 X
+
+ 클라이언트/서버 특징
+
+- stand-alone 방식이 물리적으로 떨어진 곳에서는 접속할 수 없다는 것과 사용자가 동시 작업할 수 없는 두가지 단점을 극복할 방법으로서의 방안
+- 데이터베이스를 네트워크에 연결
+- 네트워크에 연결하면 복수 사용자가 물리적으로 떨어진 곳에서 데이터베이스 접근 가능해짐.
+- 데이터베이스 서버 1대에 복수 사용자의 단말이 접속하는 구성 -> 클라이언트/서버 구성
+- 단점은 인터넷에 직접 접속해 DB에 접속하므로 보안위험 + 불특정 다수의 사용자가 사용하는 클라이언트 어플리케이션 관리 비용
+- 불특정 다수의 사용자가 사용하는 클라이언트 어플리케이션 관리 비용이라는게..
+- 우리는 웹 페이지에 접속할 때 윈도우,맥,스마트폰 같은 클라이언트 환경 차이 의식 하지 않음
+- 하지만 클라이언트/서버는 개인이 이용하는 PC에 어플리케이션 설치해 동작하게 함 (Native App)
+- 하지만 인터넷을 통해 전 세계 불특정 다수의 사용자가 이용하는 어플리케이션은 '각종 환경'에 대응해 애플리케이션을 작성해야 하고 각각에 대한 버전 관리, 버그 수정 버전을 배포하는데 비현실적인 비용이 요구됨.
+
+ Web3 계층
+
+- 웹 서버 계층(Apache, Nginx), 어플리케이션 계층(Tomcat), 데이터베이스 계층(MySQL, MongoDB)
+- 클라이언트와 데이터베이스 계층 '사이에' 웹,어플리케이션 계층 추가된 형태
+- 웹서버는 HTTP 요청을 직접 받아서 그 처리를 뒷단의 어플리케이션 계층에 넘기고 해당 결과 클라에게 반환
+- 어플리케이션 계층은 비지니스 로직을 구현한 어플리케이션이 동작하는 층
+- 웹 서버로부터 연계된 요청처리, 필요 시 DB서버에 접속해서 데이터 추출 및 가공 결과 웹 서버로 반환.
+- 사용자로부터 직접적인 접속 요청을 받는 역할 : 웹 서버 계층
+- 비지니스 로직 구현 집중 : 어플리케이션 계층
+
+## DB 서버의 다중화 - 클러스터링
+
+ DB 서버의 다중화
+
+- 병렬화해서 대수를 증가시키는 웹 서버나 어플리케이션 서버와 비교하면 다중화에 대해 고민할 부분이 많음.
+- 이유는 DB 서버가 데이터를 보존하는 '영속 계층' 이기 때문.
+
+ DB와 다른 서버의 차이
+
+- 데이터베이스는 데이터를 장기간 보존하는 매체가 필요
+- 결국, DB서버의 아키텍처는 '저장소'와 묶어서 한 세트로 고민해야 함.
+
+ 가장 기본적인 다중화
+
+- DB 서버만을 다중화하고 저장소는 하나만 두는 구성
+- 이 경우 데이터가 보존되는 저장소가 1개라서 정합성 신경 X
+- Active - Active : 클러스터를 구성하는 컴포넌트를 동시에 가동.
+- Active - Stanby : 클러스터를 구성하는 컴포넌트 중 실제 가동하는 것은 Active, 남은 것이 대기(Standby).
+
+ Active - Active 구성의 장점
+
+- 1. 시스템 다운 시간이 짧음
+- 복수의 DB서버가 '동시'에 동작하고 있어 한 대가 다운되어 동작 불능이 되도 남은 서버가 처리 지속해 전체 정지 막음
+- 2. 성능 향상 가능
+- DB 서버가 증가하면 동시에 가동하는 CPU나 메모리도 증가하기 때문.
+- 단, 저장소가 병목(bottleNeck) 되기 때문에 생각한 만큼 성능 향상 꾀하지 못할 수 있음
+- Active - Standby 구성에서는 보통 스탠바이 상태 디비 서버는 사용되지 않다가 Active DB에서 장애가 발생할 때 사용.
+- 이때문에 전환 시차가 생기고 (보통 수십 초) 그 사이 시스템은 서비스 지속 불가능한 상태가 됨
+- Active - Stanby 구성에서 Stanby 서버가 Active서버가 고장났을 때 알 수 있는 이유는 일정 간격(보통 수 초 ~ 수십 초)으로 Active DB에 이상이 없는지를 조사하기 위한 통신 수행 ---> 'HeartBeat'
+
+ Active - Standby 구성 종류
+
+- 1. Cold-Standby : 평소에는 Standby DB가 동작하지 않다가 Active DB가 다운된 시점에 작동하는 구성.
+- 2. Hot-Standby : 평소에도 Standby DB가 작동하는 구성.
+- Hot 은 전환시간은 짧지만, 그만큼 비쌈 (Active - Acitve에 비하면 저렴)
+
+## DB서버와 데이터의 다중화 - 리플리케이션
+
+ 리플리케이션이란
+
+- DB서버와 저장소 세트를 '복수'로 준비하는 것.
+- DB서버 뿐만 아니라 데이터도 다중화 수행
+- Master / Slave 구조
+- Master 서버에 장애가 일어날 시 Slave로 요청을 보내서 페일오버(FailOver)가 가능해짐.
+- 따라서, 특정 장애가 발생해도 계속해서 서비스를 유지할 수 있는 특성인 HA(High Availability - 고가용성)가 보장된다.
+- Read / Write 수행 중 Read에 대한 요청이 많으면 Slave 서버에게 요청 분산해 부하 분산 가능
+- 매우 가용성이 높은 아키텍처
+- 재난 복구 계획으로 이용
+- '달걀을 한 바구니에 다 담지 않는' 전략
+
+ 리플리케이션이 주의점
+
+- 리플리케이션에서 중요한 점은 Active 측 저장소의 데이터는 항상 사용자로부터 갱신되므로 StandBy 측 데이터에도 갱신을 반영하여 최신화하지 않으면 Active 측과의 데이터 정합성 유지 불가능.
+- 쉽게 말해 StandBy 데이터가 점점 과거의 것이 됨.
+- 리플리케이션에서는 Active측 DB 서버에서 갱신된 데이터를 일정 주기로 StandBy 측 DB 서버에 써내려감.
+- StandBy 측의 갱신 주기를 얼마로 할 것인가와 성능 사이에 트레이드오프 관계 발생
+- StandBy 측 디비 서버에서도 기록이 성공한 것을 확인한 단게에서 Active 측의 갱신도 완료된 것으로 보는 형식이므로 데이터 보호의 관점에서는 바람직하지만 이 확인 처리를 어느 정도 생략하면 성능을 향상 시킬 수 있기 때문.
+
+## 성능을 추구하기 위한 다중화 - Shared Nothing
+
+ Shared Disk와 Shared Nothing
+
+- 앞서 Active - Active 구성의 디비는 저장소 부분이 병목되는 경우가 있다고 언급
+- 복수의 서버가 1대의 디스크(저장소)를 공유하기 때문
+- 이렇게 복수의 서버가 1대의 디스크를 사요하는 구성을 'Shared Disk'
+- 액티브 - 액티브 구성은 디비 서버를 늘려도 무한으로 처리율이 향상되지 않고 어딘가에서 한계점에 도달.
+- 저장소가 공유 자원이라 쉽게 늘리기 어렵고 디비 서버 대수가 증가할수록 디비 서버간의 '정보공유'를 위한 오버헤드가 크기 때문
+- 이 단점 극복 대책안이 'Shared Nothing'
+- 보통 엄청나게 큰 테이블을 잘개 쪼개고 (horizontal Partitioning) 쪼개진 테이블을 '독립된' DB서버에 저장하는 방식.
+- 따라서 가령, 쪼개진 A테이블을 Jincheol DB 서버에 다른 쪼개진 B테이블은 Jincheol2 DB 서버에 저장해 요청마다 해당 요청이 부합되는 테이블을 가진 DB서버로 요청을 분산시킨다.
+- 그래서 데이터가 많이 쌓이는 테이블은 이런식으로 샤딩을 적용해 각각의 독립된 DB서버로 구축해 트래픽을 분산시켜 주는것이 좋다.
+- Shared Nothing은 문자 그대로 아무것도 공유 X
+- 네트워크 이외의 자원을 모두 분리하는 방식
+- 서버와 저장소의 세트를 늘리면 병렬처리 때문에 선형적으로 성능이 향상되는 장점 존재
+- Shared Nothing 방식은 비용 대비 성능이 좋음
+- DB 서버를 횡으로 나열하기 때문에 구조가 간단하며 원칙적으로 DB 서버 수에 비례해서 저장소가 증가.
+- 단점은..!
+- 저장소를 공유하지 않는다는 겻은 결국 디비 서버가 동일한 1개의 데이터에 접근할 수 없다라는 것을 의미.
+- 고양시 데이터를 가진 디비 서버가 접근할 수 있는건 고양시 데이터뿐, 부천시 광명시 데이터는 접근 불가
+- 또한 시별 인구 데이터를 합산해서 경기도 인구 계산하려는 경우 각 테이블로부터의 JOIN 연산 요구됨
+
+## 끝 !
diff --git a/Document/2023/0910/jincheol/.gitkeep b/Document/2023/0910/jincheol/.gitkeep
deleted file mode 100644
index e69de29..0000000
diff --git "a/Document/2023/0910/jincheol/[2\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(5-7\354\236\245).md" "b/Document/2023/0910/jincheol/[2\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(5-7\354\236\245).md"
new file mode 100644
index 0000000..c3ed5c2
--- /dev/null
+++ "b/Document/2023/0910/jincheol/[2\354\243\274\354\260\250]_Jincheol_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(5-7\354\236\245).md"
@@ -0,0 +1,734 @@
+# 5장
+
+## MySQL과 커넥션 만들기
+
+### 커넥션이란
+
+로그인해서 프롬프트가 표시되었다는 것은 로그인전과 로그인 후로 사용자와 MySQL의 관계가 변했다는 것을 의미한다. 이는 사용자와 MySQL이 접속되었다 즉, 연결되었다는 뜻. 이 연결이라는 것을 시스템 세계에서는 커넥션이라고 부릅니다.
+
+### Prompt의 의미.
+
+Prompt라는 단어는 사람에게 무언가를 하라고 재촉할 때 사용하는 말이다. 따라서 'mysql >' 이란 MySQL 사용자를 향해서 '명령을 입력하라'고 재촉하는 것.
+
+## 데이터베이스에 전화 걸기
+
+### 커넥션의 이미지는 전화
+
+1. 상대방의 전화번호를 입력한다 -> 2. 전화를 건다. -> 3. 상대방이 전화를 받는다.
+
+이 3단계를 통해 만들어진 연결이 '커넥션'. 커넥션이 유지되는 동아에는 대화할 수 있다.
+말하자면 로그인이라는 행위는 상대방을 호출하는 행위와 같다.
+
+```java
+Your MySQL connection id is 11
+```
+
+MySQL은 동시에 여러 개의 커넥션을 유지하는 것이 가능 (동시에 복수의 사용자와 연결하는 것이 가능) 해서 이렇게 번호로 관리하지 않으면 어떤 커넥션이 어느 사용자를 위한 것인지를 모름.
+
+이 커넥션의 시작과 종료 사이에 다양한 교환을 하게 되는데, 그 교환과 시작의 종료까지의 단위를 '세션' 이라고 한다.
+커넥션과 세션은 매우 유사한 개념이라 같은 의미로 사용되는 경우도 많지만 정확하게는 커넥션이 확립된 후 세션이 만들어집니다.
+
+이 둘을 잘 구분하지 않는 이유는 기본적으로 커넥션과 세션은 1:1로 대응되어서 커넥션이 성립되면 동시에 암묵적으로 세션도 시작되고 세션을 끊으면 커넥션도 끊어지는 경우가 많기 때문이다.
+
+### 커넥션의 상태를 조사하는 명령
+
+거의 모든 DBMS는 커넥션의 상태나 수를 조사하기 위한 명령어를 준비해 두고 있다.
+
+```
+mysql> show status like 'Threads_connected';
++-------------------+-------+
+| Variable_name | Value |
++-------------------+-------+
+| Threads_connected | 15 |
++-------------------+-------+
+```
+
+### SQL과 관리 명령의 차이
+
+#### show status
+
+```
+mysql> show status like 'Uptime';
++---------------+---------+
+| Variable_name | Value |
++---------------+---------+
+| Uptime | 1430468 |
++---------------+---------+
+1 row in set (0.00 sec)
+```
+
+```
+mysql> show status like 'Queries';
++---------------+-------+
+| Variable_name | Value |
++---------------+-------+
+| Queries | 39266 |
++---------------+-------+
+1 row in set (0.00 sec)
+```
+
+# 6장 - SELECT 문으로 테이블 내용을 살펴보자
+
+```
+mysql> show databases;
++--------------------+
+| Database |
++--------------------+
+| article |
+| board-app |
+| bookMark |
+| book_store |
+| cafe |
+| delivery |
+| headfirst |
+| information_schema |
+| mysql |
+| nodejs |
+| performance_schema |
+| reallyou |
+| sbadge |
+| simple_board |
+| statistc |
+| sys |
+| test2 |
+| theater |
+| user |
+| world |
++--------------------+
+20 rows in set (0.00 sec)
+```
+
+```
+mysql> use world;
+Database changed
+mysql> show tables;
++-----------------+
+| Tables_in_world |
++-----------------+
+| city |
+| country |
+| countrylanguage |
++-----------------+
+3 rows in set (0.00 sec)
+```
+
+### 조건을 지정해서 출력해보자 1.
+
+```
+mysql> select * from city where countrycode = 'KOR';
++------+------------+-------------+---------------+------------+
+| ID | Name | CountryCode | District | Population |
++------+------------+-------------+---------------+------------+
+| 2331 | Seoul | KOR | Seoul | 9981619 |
+| 2332 | Pusan | KOR | Pusan | 3804522 |
+| 2333 | Inchon | KOR | Inchon | 2559424 |
+| 2334 | Taegu | KOR | Taegu | 2548568 |
+| 2335 | Taejon | KOR | Taejon | 1425835 |
+| 2336 | Kwangju | KOR | Kwangju | 1368341 |
+| 2337 | Ulsan | KOR | Kyongsangnam | 1084891 |
+| 2338 | Songnam | KOR | Kyonggi | 869094 |
+| 2339 | Puchon | KOR | Kyonggi | 779412 |
+| 2340 | Suwon | KOR | Kyonggi | 755550 |
+| 2341 | Anyang | KOR | Kyonggi | 591106 |
+| 2342 | Chonju | KOR | Chollabuk | 563153 |
+| 2343 | Chongju | KOR | Chungchongbuk | 531376 |
+| 2344 | Koyang | KOR | Kyonggi | 518282 |
+| 2345 | Ansan | KOR | Kyonggi | 510314 |
+| 2346 | Pohang | KOR | Kyongsangbuk | 508899 |
+| 2347 | Chang-won | KOR | Kyongsangnam | 481694 |
+| 2348 | Masan | KOR | Kyongsangnam | 441242 |
+| 2349 | Kwangmyong | KOR | Kyonggi | 350914 |
+| 2350 | Chonan | KOR | Chungchongnam | 330259 |
+| 2351 | Chinju | KOR | Kyongsangnam | 329886 |
+| 2352 | Iksan | KOR | Chollabuk | 322685 |
+| 2353 | Pyongtaek | KOR | Kyonggi | 312927 |
+| 2354 | Kumi | KOR | Kyongsangbuk | 311431 |
+| 2355 | Uijongbu | KOR | Kyonggi | 276111 |
+| 2356 | Kyongju | KOR | Kyongsangbuk | 272968 |
+| 2357 | Kunsan | KOR | Chollabuk | 266569 |
+| 2358 | Cheju | KOR | Cheju | 258511 |
+| 2359 | Kimhae | KOR | Kyongsangnam | 256370 |
+| 2360 | Sunchon | KOR | Chollanam | 249263 |
+| 2361 | Mokpo | KOR | Chollanam | 247452 |
+| 2362 | Yong-in | KOR | Kyonggi | 242643 |
+| 2363 | Wonju | KOR | Kang-won | 237460 |
+| 2364 | Kunpo | KOR | Kyonggi | 235233 |
+| 2365 | Chunchon | KOR | Kang-won | 234528 |
+| 2366 | Namyangju | KOR | Kyonggi | 229060 |
+| 2367 | Kangnung | KOR | Kang-won | 220403 |
+| 2368 | Chungju | KOR | Chungchongbuk | 205206 |
+| 2369 | Andong | KOR | Kyongsangbuk | 188443 |
+| 2370 | Yosu | KOR | Chollanam | 183596 |
+| 2371 | Kyongsan | KOR | Kyongsangbuk | 173746 |
+| 2372 | Paju | KOR | Kyonggi | 163379 |
+| 2373 | Yangsan | KOR | Kyongsangnam | 163351 |
+| 2374 | Ichon | KOR | Kyonggi | 155332 |
+| 2375 | Asan | KOR | Chungchongnam | 154663 |
+| 2376 | Koje | KOR | Kyongsangnam | 147562 |
+| 2377 | Kimchon | KOR | Kyongsangbuk | 147027 |
+| 2378 | Nonsan | KOR | Chungchongnam | 146619 |
+| 2379 | Kuri | KOR | Kyonggi | 142173 |
+| 2380 | Chong-up | KOR | Chollabuk | 139111 |
+| 2381 | Chechon | KOR | Chungchongbuk | 137070 |
+| 2382 | Sosan | KOR | Chungchongnam | 134746 |
+| 2383 | Shihung | KOR | Kyonggi | 133443 |
+| 2384 | Tong-yong | KOR | Kyongsangnam | 131717 |
+| 2385 | Kongju | KOR | Chungchongnam | 131229 |
+| 2386 | Yongju | KOR | Kyongsangbuk | 131097 |
+| 2387 | Chinhae | KOR | Kyongsangnam | 125997 |
+| 2388 | Sangju | KOR | Kyongsangbuk | 124116 |
+| 2389 | Poryong | KOR | Chungchongnam | 122604 |
+| 2390 | Kwang-yang | KOR | Chollanam | 122052 |
+| 2391 | Miryang | KOR | Kyongsangnam | 121501 |
+| 2392 | Hanam | KOR | Kyonggi | 115812 |
+| 2393 | Kimje | KOR | Chollabuk | 115427 |
+| 2394 | Yongchon | KOR | Kyongsangbuk | 113511 |
+| 2395 | Sachon | KOR | Kyongsangnam | 113494 |
+| 2396 | Uiwang | KOR | Kyonggi | 108788 |
+| 2397 | Naju | KOR | Chollanam | 107831 |
+| 2398 | Namwon | KOR | Chollabuk | 103544 |
+| 2399 | Tonghae | KOR | Kang-won | 95472 |
+| 2400 | Mun-gyong | KOR | Kyongsangbuk | 92239 |
++------+------------+-------------+---------------+------------+
+70 rows in set (0.02 sec)
+```
+
+### 조건을 지정해서 출력해보자 2.
+
+```
+mysql> select * from city where district = 'chollanam';
++------+------------+-------------+-----------+------------+
+| ID | Name | CountryCode | District | Population |
++------+------------+-------------+-----------+------------+
+| 2360 | Sunchon | KOR | Chollanam | 249263 |
+| 2361 | Mokpo | KOR | Chollanam | 247452 |
+| 2370 | Yosu | KOR | Chollanam | 183596 |
+| 2390 | Kwang-yang | KOR | Chollanam | 122052 |
+| 2397 | Naju | KOR | Chollanam | 107831 |
++------+------------+-------------+-----------+------------+
+5 rows in set (0.00 sec)
+```
+
+### 불필요한 열을 제거하고 표시해 보자.
+
+```
+
+mysql> select Name,Population from city where district = 'chollanam';
++------------+------------+
+| Name | Population |
++------------+------------+
+| Sunchon | 249263 |
+| Mokpo | 247452 |
+| Yosu | 183596 |
+| Kwang-yang | 122052 |
+| Naju | 107831 |
++------------+------------+
+5 rows in set (0.00 sec)
+
+```
+
+### 다양한 조건을 추가해 보자 1.
+
+```
+mysql> select Name,Population from city where district = 'chollanam' and population > 150000;
++---------+------------+
+| Name | Population |
++---------+------------+
+| Sunchon | 249263 |
+| Mokpo | 247452 |
+| Yosu | 183596 |
++---------+------------+
+3 rows in set (0.02 sec)
+```
+
+### 다양한 조건을 추가해 보자 2.
+
+```
+mysql> select distinct district from city where countrycode ='KOR';
++---------------+
+| district |
++---------------+
+| Seoul |
+| Pusan |
+| Inchon |
+| Taegu |
+| Taejon |
+| Kwangju |
+| Kyongsangnam |
+| Kyonggi |
+| Chollabuk |
+| Chungchongbuk |
+| Kyongsangbuk |
+| Chungchongnam |
+| Cheju |
+| Chollanam |
+| Kang-won |
++---------------+
+15 rows in set (0.01 sec)
+```
+
+# 7장 - SELECT 문을 응용해보자
+
+### order by
+
+```
+
+mysql> select * from city where countrycode = 'KOR' order by population;
++------+------------+-------------+---------------+------------+
+| ID | Name | CountryCode | District | Population |
++------+------------+-------------+---------------+------------+
+| 2400 | Mun-gyong | KOR | Kyongsangbuk | 92239 |
+| 2399 | Tonghae | KOR | Kang-won | 95472 |
+| 2398 | Namwon | KOR | Chollabuk | 103544 |
+| 2397 | Naju | KOR | Chollanam | 107831 |
+| 2396 | Uiwang | KOR | Kyonggi | 108788 |
+| 2395 | Sachon | KOR | Kyongsangnam | 113494 |
+| 2394 | Yongchon | KOR | Kyongsangbuk | 113511 |
+| 2393 | Kimje | KOR | Chollabuk | 115427 |
+| 2392 | Hanam | KOR | Kyonggi | 115812 |
+| 2391 | Miryang | KOR | Kyongsangnam | 121501 |
+| 2390 | Kwang-yang | KOR | Chollanam | 122052 |
+| 2389 | Poryong | KOR | Chungchongnam | 122604 |
+| 2388 | Sangju | KOR | Kyongsangbuk | 124116 |
+| 2387 | Chinhae | KOR | Kyongsangnam | 125997 |
+| 2386 | Yongju | KOR | Kyongsangbuk | 131097 |
+| 2385 | Kongju | KOR | Chungchongnam | 131229 |
+| 2384 | Tong-yong | KOR | Kyongsangnam | 131717 |
+| 2383 | Shihung | KOR | Kyonggi | 133443 |
+| 2382 | Sosan | KOR | Chungchongnam | 134746 |
+| 2381 | Chechon | KOR | Chungchongbuk | 137070 |
+| 2380 | Chong-up | KOR | Chollabuk | 139111 |
+| 2379 | Kuri | KOR | Kyonggi | 142173 |
+| 2378 | Nonsan | KOR | Chungchongnam | 146619 |
+| 2377 | Kimchon | KOR | Kyongsangbuk | 147027 |
+| 2376 | Koje | KOR | Kyongsangnam | 147562 |
+| 2375 | Asan | KOR | Chungchongnam | 154663 |
+| 2374 | Ichon | KOR | Kyonggi | 155332 |
+| 2373 | Yangsan | KOR | Kyongsangnam | 163351 |
+| 2372 | Paju | KOR | Kyonggi | 163379 |
+| 2371 | Kyongsan | KOR | Kyongsangbuk | 173746 |
+| 2370 | Yosu | KOR | Chollanam | 183596 |
+| 2369 | Andong | KOR | Kyongsangbuk | 188443 |
+| 2368 | Chungju | KOR | Chungchongbuk | 205206 |
+| 2367 | Kangnung | KOR | Kang-won | 220403 |
+| 2366 | Namyangju | KOR | Kyonggi | 229060 |
+| 2365 | Chunchon | KOR | Kang-won | 234528 |
+| 2364 | Kunpo | KOR | Kyonggi | 235233 |
+| 2363 | Wonju | KOR | Kang-won | 237460 |
+| 2362 | Yong-in | KOR | Kyonggi | 242643 |
+| 2361 | Mokpo | KOR | Chollanam | 247452 |
+| 2360 | Sunchon | KOR | Chollanam | 249263 |
+| 2359 | Kimhae | KOR | Kyongsangnam | 256370 |
+| 2358 | Cheju | KOR | Cheju | 258511 |
+| 2357 | Kunsan | KOR | Chollabuk | 266569 |
+| 2356 | Kyongju | KOR | Kyongsangbuk | 272968 |
+| 2355 | Uijongbu | KOR | Kyonggi | 276111 |
+| 2354 | Kumi | KOR | Kyongsangbuk | 311431 |
+| 2353 | Pyongtaek | KOR | Kyonggi | 312927 |
+| 2352 | Iksan | KOR | Chollabuk | 322685 |
+| 2351 | Chinju | KOR | Kyongsangnam | 329886 |
+| 2350 | Chonan | KOR | Chungchongnam | 330259 |
+| 2349 | Kwangmyong | KOR | Kyonggi | 350914 |
+| 2348 | Masan | KOR | Kyongsangnam | 441242 |
+| 2347 | Chang-won | KOR | Kyongsangnam | 481694 |
+| 2346 | Pohang | KOR | Kyongsangbuk | 508899 |
+| 2345 | Ansan | KOR | Kyonggi | 510314 |
+| 2344 | Koyang | KOR | Kyonggi | 518282 |
+| 2343 | Chongju | KOR | Chungchongbuk | 531376 |
+| 2342 | Chonju | KOR | Chollabuk | 563153 |
+| 2341 | Anyang | KOR | Kyonggi | 591106 |
+| 2340 | Suwon | KOR | Kyonggi | 755550 |
+| 2339 | Puchon | KOR | Kyonggi | 779412 |
+| 2338 | Songnam | KOR | Kyonggi | 869094 |
+| 2337 | Ulsan | KOR | Kyongsangnam | 1084891 |
+| 2336 | Kwangju | KOR | Kwangju | 1368341 |
+| 2335 | Taejon | KOR | Taejon | 1425835 |
+| 2334 | Taegu | KOR | Taegu | 2548568 |
+| 2333 | Inchon | KOR | Inchon | 2559424 |
+| 2332 | Pusan | KOR | Pusan | 3804522 |
+| 2331 | Seoul | KOR | Seoul | 9981619 |
++------+------------+-------------+---------------+------------+
+70 rows in set (0.01 sec)
+```
+
+### 테이블을 집약해 보자
+
+```
+mysql> select count(*) from city where countrycode = 'KOR';
++----------+
+| count(*) |
++----------+
+| 70 |
++----------+
+1 row in set (0.00 sec)
+```
+
+```
+mysql> select min(population), max(population), sum(population), avg(population) from city where countrycode='KOR';
++-----------------+-----------------+-----------------+-----------------+
+| min(population) | max(population) | sum(population) | avg(population) |
++-----------------+-----------------+-----------------+-----------------+
+| 92239 | 9981619 | 38999893 | 557141.3286 |
++-----------------+-----------------+-----------------+-----------------+
+1 row in set (0.01 sec)
+```
+
+```
+mysql> select name from city where district = 'Chollabuk' and countrycode = 'KOR';
++----------+
+| name |
++----------+
+| Chonju |
+| Iksan |
+| Kunsan |
+| Chong-up |
+| Kimje |
+| Namwon |
++----------+
+6 rows in set (0.01 sec)
+
+```
+
+#### group_concat
+
+```
+
+mysql> select group_concat(name) from city where countrycode = 'KOR' and district = 'Chollabuk';
++-------------------------------------------+
+| group_concat(name) |
++-------------------------------------------+
+| Chonju,Iksan,Kunsan,Chong-up,Kimje,Namwon |
++-------------------------------------------+
+1 row in set (0.00 sec)
+```
+
+#### count(\*) , group by
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' group by district;
++---------------+----------+
+| district | count(*) |
++---------------+----------+
+| Cheju | 1 |
+| Chollabuk | 6 |
+| Chollanam | 5 |
+| Chungchongbuk | 3 |
+| Chungchongnam | 6 |
+| Inchon | 1 |
+| Kang-won | 4 |
+| Kwangju | 1 |
+| Kyonggi | 18 |
+| Kyongsangbuk | 10 |
+| Kyongsangnam | 11 |
+| Pusan | 1 |
+| Seoul | 1 |
+| Taegu | 1 |
+| Taejon | 1 |
++---------------+----------+
+15 rows in set (0.00 sec)
+```
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' group by district having count(*)=6;
++---------------+----------+
+| district | count(*) |
++---------------+----------+
+| Chollabuk | 6 |
+| Chungchongnam | 6 |
++---------------+----------+
+2 rows in set (0.00 sec)
+```
+
+## SELECT 문의 응용조작을 배워보자
+
+### 검색결과 정렬
+
+#### order by
+
+주의점 : order by 사용할 땐 정확하게 순서를 매길 수 컬럼을 지정해줘야함 가령, district와 같은 컬럼을 지정해줬는데 해당 컬럼의 갯수가 복수개면 무작위한 순서로 order by됨. (각각의 컬럼이 유니크하면 상관 X)
+
+그래서 order by 순으로 지정해주고 싶으면 위의 경우 district,name 식으로 유니크한 name 컬럼을 동반시켜줘야함.
+
+```
+
+mysql> select * from city where countrycode = 'KOR' order by population desc;
++------+------------+-------------+---------------+------------+
+| ID | Name | CountryCode | District | Population |
++------+------------+-------------+---------------+------------+
+| 2331 | Seoul | KOR | Seoul | 9981619 |
+| 2332 | Pusan | KOR | Pusan | 3804522 |
+| 2333 | Inchon | KOR | Inchon | 2559424 |
+| 2334 | Taegu | KOR | Taegu | 2548568 |
+| 2335 | Taejon | KOR | Taejon | 1425835 |
+| 2336 | Kwangju | KOR | Kwangju | 1368341 |
+| 2337 | Ulsan | KOR | Kyongsangnam | 1084891 |
+| 2338 | Songnam | KOR | Kyonggi | 869094 |
+| 2339 | Puchon | KOR | Kyonggi | 779412 |
+| 2340 | Suwon | KOR | Kyonggi | 755550 |
+| 2341 | Anyang | KOR | Kyonggi | 591106 |
+| 2342 | Chonju | KOR | Chollabuk | 563153 |
+| 2343 | Chongju | KOR | Chungchongbuk | 531376 |
+| 2344 | Koyang | KOR | Kyonggi | 518282 |
+| 2345 | Ansan | KOR | Kyonggi | 510314 |
+| 2346 | Pohang | KOR | Kyongsangbuk | 508899 |
+| 2347 | Chang-won | KOR | Kyongsangnam | 481694 |
+| 2348 | Masan | KOR | Kyongsangnam | 441242 |
+| 2349 | Kwangmyong | KOR | Kyonggi | 350914 |
+| 2350 | Chonan | KOR | Chungchongnam | 330259 |
+| 2351 | Chinju | KOR | Kyongsangnam | 329886 |
+| 2352 | Iksan | KOR | Chollabuk | 322685 |
+| 2353 | Pyongtaek | KOR | Kyonggi | 312927 |
+| 2354 | Kumi | KOR | Kyongsangbuk | 311431 |
+| 2355 | Uijongbu | KOR | Kyonggi | 276111 |
+| 2356 | Kyongju | KOR | Kyongsangbuk | 272968 |
+| 2357 | Kunsan | KOR | Chollabuk | 266569 |
+| 2358 | Cheju | KOR | Cheju | 258511 |
+| 2359 | Kimhae | KOR | Kyongsangnam | 256370 |
+| 2360 | Sunchon | KOR | Chollanam | 249263 |
+| 2361 | Mokpo | KOR | Chollanam | 247452 |
+| 2362 | Yong-in | KOR | Kyonggi | 242643 |
+| 2363 | Wonju | KOR | Kang-won | 237460 |
+| 2364 | Kunpo | KOR | Kyonggi | 235233 |
+| 2365 | Chunchon | KOR | Kang-won | 234528 |
+| 2366 | Namyangju | KOR | Kyonggi | 229060 |
+| 2367 | Kangnung | KOR | Kang-won | 220403 |
+| 2368 | Chungju | KOR | Chungchongbuk | 205206 |
+| 2369 | Andong | KOR | Kyongsangbuk | 188443 |
+| 2370 | Yosu | KOR | Chollanam | 183596 |
+| 2371 | Kyongsan | KOR | Kyongsangbuk | 173746 |
+| 2372 | Paju | KOR | Kyonggi | 163379 |
+| 2373 | Yangsan | KOR | Kyongsangnam | 163351 |
+| 2374 | Ichon | KOR | Kyonggi | 155332 |
+| 2375 | Asan | KOR | Chungchongnam | 154663 |
+| 2376 | Koje | KOR | Kyongsangnam | 147562 |
+| 2377 | Kimchon | KOR | Kyongsangbuk | 147027 |
+| 2378 | Nonsan | KOR | Chungchongnam | 146619 |
+| 2379 | Kuri | KOR | Kyonggi | 142173 |
+| 2380 | Chong-up | KOR | Chollabuk | 139111 |
+| 2381 | Chechon | KOR | Chungchongbuk | 137070 |
+| 2382 | Sosan | KOR | Chungchongnam | 134746 |
+| 2383 | Shihung | KOR | Kyonggi | 133443 |
+| 2384 | Tong-yong | KOR | Kyongsangnam | 131717 |
+| 2385 | Kongju | KOR | Chungchongnam | 131229 |
+| 2386 | Yongju | KOR | Kyongsangbuk | 131097 |
+| 2387 | Chinhae | KOR | Kyongsangnam | 125997 |
+| 2388 | Sangju | KOR | Kyongsangbuk | 124116 |
+| 2389 | Poryong | KOR | Chungchongnam | 122604 |
+| 2390 | Kwang-yang | KOR | Chollanam | 122052 |
+| 2391 | Miryang | KOR | Kyongsangnam | 121501 |
+| 2392 | Hanam | KOR | Kyonggi | 115812 |
+| 2393 | Kimje | KOR | Chollabuk | 115427 |
+| 2394 | Yongchon | KOR | Kyongsangbuk | 113511 |
+| 2395 | Sachon | KOR | Kyongsangnam | 113494 |
+| 2396 | Uiwang | KOR | Kyonggi | 108788 |
+| 2397 | Naju | KOR | Chollanam | 107831 |
+| 2398 | Namwon | KOR | Chollabuk | 103544 |
+| 2399 | Tonghae | KOR | Kang-won | 95472 |
+| 2400 | Mun-gyong | KOR | Kyongsangbuk | 92239 |
++------+------------+-------------+---------------+------------+
+70 rows in set (0.00 sec)
+```
+
+## 테이블을 요약하는 함수
+
+함수는 크게 2종류
+
+- 1. 복수 행(이나 행의 값)에 대해 집계를 수행하는 함수
+- 2. 단일 행의 값에 대해 조작이나 계산을 수행하는 함수
+
+COUNT 함수는 전자에 해당하는데, 이런 집계용 함수를 집약함수(집계함수) 라고 부름.
+
+[대표 집약함수]
+
+- COUNT : 테이블 행수를 알려주는 함수
+- SUM : 테이블의 수치 데이터를 합계하는 함수
+- AVG : 테이블의 수치 데이터 평균을 구하는 함수
+- MAX: 테이블의 임의열 데이터 중 최대값을 구하는 함수
+- MIN : 테이블의 임의열 데이터 중 최소값을 구하는 함수
+
+이러한 집약함수는 기본적으로 NULL을 제외. COUNT 함수만은 COUNT(\*) 로 표기하여 NULL 포함 !!
+
+또한 SUM,AVG 함수 제외 집약함수는 수치 데이터 외에도 이용 가능.
+다만 문자 표현하는 내부 코드에 의존하므로 이용할 수 있는 예는 한정됨.
+EX) 도시명 최대값 : Y로 시작하는 Yosu(여수), 최소값은 A로 시작하는 Andong.
+
+```
+
+mysql> select max(name) from city where countrycode = 'KOR';
++-----------+
+| max(name) |
++-----------+
+| Yosu |
++-----------+
+1 row in set (0.01 sec)
+```
+
+## 문자열을 집약하는 GROUP_COUNT
+
+GROUP_COUNT 함수는 '문자열'에 대한 집계를 '문자열의 결합'으로 수행.
+따라서 콤마로 구분되는 매우 긴 데이터를 결과로 돌려줌.
+
+#### DISTINCT로 중복 회피
+
+```
+mysql> select group_concat(district) from city where countrycode = 'KOR';
+
+| Seoul,Pusan,Inchon,Taegu,Taejon,Kwangju,Kyongsangnam,Kyonggi,Kyonggi,Kyonggi,Kyonggi,Chollabuk,Chungchongbuk,Kyonggi,Kyonggi,Kyongsangbuk,Kyongsangnam,Kyongsangnam,Kyonggi,Chungchongnam,Kyongsangnam,Chollabuk,Kyonggi,Kyongsangbuk,Kyonggi,Kyongsangbuk,Chollabuk,Cheju,Kyongsangnam,Chollanam,Chollanam,Kyonggi,Kang-won,Kyonggi,Kang-won,Kyonggi,Kang-won,Chungchongbuk,Kyongsangbuk,Chollanam,Kyongsangbuk,Kyonggi,Kyongsangnam,Kyonggi,Chungchongnam,Kyongsangnam,Kyongsangbuk,Chungchongnam,Kyonggi,Chollabuk,Chungchongbuk,Chungchongnam,Kyonggi,Kyongsangnam,Chungchongnam,Kyongsangbuk,Kyongsangnam,Kyongsangbuk,Chungchongnam,Chollanam,Kyongsangnam,Kyonggi,Chollabuk,Kyongsangbuk,Kyongsangnam,Kyonggi,Chollanam,Chollabuk,Kang-won,Kyongsangbuk |
+```
+
+--> 행정구역을 단순히 GROUP_CONCAT 수행한다면 경상남도는 결과 값에 따라 여러 번 나오게된다.
+
+#### DISTINCT 사용 시
+
+```
+mysql> select group_concat(DISTINCT district) from city where countrycode = 'KOR';
++------------------------------------------------------------------------------------------------------------------------------------------+
+| group_concat(DISTINCT district) |
++------------------------------------------------------------------------------------------------------------------------------------------+
+| Cheju,Chollabuk,Chollanam,Chungchongbuk,Chungchongnam,Inchon,Kang-won,Kwangju,Kyonggi,Kyongsangbuk,Kyongsangnam,Pusan,Seoul,Taegu,Taejon |
++------------------------------------------------------------------------------------------------------------------------------------------+
+1 row in set (0.01 sec)
+
+```
+
+## 데이터를 그룹으로 나누는 GROUP BY
+
+- 대상이 되는 데이터를 그룹으로 나눠서 집약!
+- 그룹으로 나눌 떄는 나누는 키가 되는 열을 지정
+- GROUP BY로 지정한 열을 집약 키나 그룹화 키로 부르며 이들은 ORDER BY 처럼 복수 열을 콤마로 구분해 지정 가능
+
+- 행정구역 별로 그룹을 지어서 카운트를 나타냄 !
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' GROUP BY district;
++---------------+----------+
+| district | count(*) |
++---------------+----------+
+| Cheju | 1 |
+| Chollabuk | 6 |
+| Chollanam | 5 |
+| Chungchongbuk | 3 |
+| Chungchongnam | 6 |
+| Inchon | 1 |
+| Kang-won | 4 |
+| Kwangju | 1 |
+| Kyonggi | 18 |
+| Kyongsangbuk | 10 |
+| Kyongsangnam | 11 |
+| Pusan | 1 |
+| Seoul | 1 |
+| Taegu | 1 |
+| Taejon | 1 |
++---------------+----------+
+15 rows in set (0.01 sec)
+```
+
+### 나눈 그룹에 조건 추가
+
+- and count(\*)로 조건 추가!
+- COUNT 같은 집약함수를 작성할 수 있는 경우는 SELECT와 ORDER BY, HAVING 뿐이다.
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' and count(*) =4 GROUP BY district;
+ERROR 1111 (HY000): Invalid use of group function
+```
+
+### order by + group by
+
+- 행정 구역을 기준으로 그룹핑 한 것을 오름차순으로 정리 !
+- 여기서 오름차순으로 정렬하려면 count(\*)가 district 보다 먼저 나와야함.
+- district 가 먼저 나오면 지명 맨 앞글자 알파벳순으로 정렬됨.
+
+```
+mysql> SELECT district, count(*) FROM city WHERE countrycode = 'KOR' GROUP BY district ORDER BY count(*), district;
++---------------+----------+
+| district | count(*) |
++---------------+----------+
+| Cheju | 1 |
+| Inchon | 1 |
+| Kwangju | 1 |
+| Pusan | 1 |
+| Seoul | 1 |
+| Taegu | 1 |
+| Taejon | 1 |
+| Chungchongbuk | 3 |
+| Kang-won | 4 |
+| Chollanam | 5 |
+| Chollabuk | 6 |
+| Chungchongnam | 6 |
+| Kyongsangbuk | 10 |
+| Kyongsangnam | 11 |
+| Kyonggi | 18 |
++---------------+----------+
+15 rows in set (0.00 sec)
+```
+
+## 집약한 결과에 조건 지정
+
+그룹마다 집약한 값을 조건으로 선택하고 싶다면 'HAVING' 뒤에 조건을 추가
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' GROUP BY district having count(*)=6;
++---------------+----------+
+| district | count(*) |
++---------------+----------+
+| Chollabuk | 6 |
+| Chungchongnam | 6 |
++---------------+----------+
+2 rows in set (0.00 sec)
+```
+
+## order by + group by + count(\*)
+
+```
+mysql> select district, count(*) from city where countrycode = 'KOR' GROUP BY district having count(*)>6 order by count(*) asc;
++--------------+----------+
+| district | count(*) |
++--------------+----------+
+| Kyongsangbuk | 10 |
+| Kyongsangnam | 11 |
+| Kyonggi | 18 |
++--------------+----------+
+3 rows in set (0.00 sec)
+```
+
+## 순서 !!
+
+SELECT -> FROM -> WHERE -> GROUP BY -> HAVING -> ORDER BY !!!
+
+---
+
+## LEETCODE 문제
+
+1. https://leetcode.com/problems/project-employees-i/description/
+
+#### My Answer
+
+```
+SELECT p.project_id, ROUND(AVG(e.experience_years), 2) AS average_years
+FROM Employee e
+INNER JOIN Project p ON e.employee_id = p.employee_id
+GROUP BY p.project_id;
+```
+
+- 주요점 1 : ROUND는 반올림 함수 , EX) ROUND( , 2) 이면 소수점 셋째자리에서 반올림 수행 후 둘째 자리까지 표현하라는 의미.
+- 주요점 2: FROM 으로 기준 테이블 잡고 JOIN 수행 전치사 ON을 붙여 조인할 컬럼 지정
+
+2. https://leetcode.com/problems/tree-node/submissions/
+
+```
+select id,
+ CASE
+ when p_id IS NULL THEN 'Root'
+ when id NOT IN (SELECT DISTINCT p_id from Tree where p_id is not null) THEN 'Leaf'
+ else 'Inner'
+
+ END AS type
+
+from Tree
+
+```
+
+- 주요점 1 : CASE ~ WEHN 구절 사용시 select 하고 컬럼 지정후 ',' 붙이고 CASE 들어가야함
+- 주요점 2 : p_id 를 DISTINCT로 필터링한 결과에 id값이 존재하지 않으면 그것은 자식 노드가 없는 leaf 노드 (is not null 꼭 체크!!!! 널값 체킹 안해주면 다 else로 빠져서 Inner로 처리됨)
+- 주요점 3 : 케이스문 다 끝나면 END 로 마무리 짓기.
diff --git a/Document/2023/0917/jincheol/.gitkeep b/Document/2023/0917/jincheol/.gitkeep
deleted file mode 100644
index e69de29..0000000
diff --git "a/Document/2023/0917/jincheol/[3\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(7-8\354\236\245).md" "b/Document/2023/0917/jincheol/[3\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(7-8\354\236\245).md"
new file mode 100644
index 0000000..49e2082
--- /dev/null
+++ "b/Document/2023/0917/jincheol/[3\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(7-8\354\236\245).md"
@@ -0,0 +1,717 @@
+# 7장 - 트랜잭션과 동시성 제어
+
+## 트랜잭션
+
+- 단일한 논리적인 작업 단위
+- 논리적인 이유로 여러 SQL문들을 단일작업으로 묶어서 나눠질 수 없게 만드는 것이 transaction이다.
+- transaction의 SQL문들 중에 일부만 성공해서 DB에 반영되는 일은 일어나지 않는다.
+
+```java
+mysql> use TransactionTest
+Reading table information for completion of table and column names
+You can turn off this feature to get a quicker startup with -A
+
+Database changed
+mysql> show tables;
++---------------------------+
+| Tables_in_TransactionTest |
++---------------------------+
+| account |
++---------------------------+
+1 row in set (0.00 sec)
+
+mysql> START TRANSACTION;
+Query OK, 0 rows affected (0.00 sec)
+
+mysql> UPDATE account SET balance = balance - 20000 where name = "철수";
+Query OK, 1 row affected (0.01 sec)
+Rows matched: 1 Changed: 1 Warnings: 0
+
+mysql> UPDATE account SET balance = balance + 20000 where name = "영희";
+Query OK, 1 row affected (0.00 sec)
+Rows matched: 1 Changed: 1 Warnings: 0
+
+mysql> COMMIT;
+Query OK, 0 rows affected (0.00 sec)
+
+mysql>
+```
+
+### COMMIT
+
+- 지금까지 작업한 내용을 DB에 영구적으로 저장하는 것
+- transaction을 종료한다.
+
+### 결과
+
+```java
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 1 | 220000 | 영희 |
+| 2 | 980000 | 철수 |
++----+---------+--------+
+2 rows in set (0.01 sec)
+```
+
+## ROLLBACK
+
+- 지금까지 작업들을 모두 취소하고 transaction 이전 상태로 되돌린다.
+- transaction을 종료한다.
+
+```java
+
+mysql> START TRANSACTION;
+Query OK, 0 rows affected (0.01 sec)
+
+mysql> UPDATE account SET balance = balance - 200000 where name = "철수";
+Query OK, 1 row affected (0.00 sec)
+Rows matched: 1 Changed: 1 Warnings: 0
+
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 1 | 220000 | 영희 |
+| 2 | 780000 | 철수 |
++----+---------+--------+
+2 rows in set (0.01 sec)
+
+mysql> ROLLBACK;
+Query OK, 0 rows affected (0.00 sec)
+
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 1 | 220000 | 영희 |
+| 2 | 980000 | 철수 |
++----+---------+--------+
+2 rows in set (0.00 sec)
+```
+
+## AUTOCOMMIT
+
+- 각각의 SQL문을 자동으로 transaction 처리 해주는 개념
+- SQL문이 성공적으로 실행되면 자동으로 commit 한다.
+- 실행 중에 문제가 있었다면 알아서 ROLLBACK 한다.
+- MYSQL에서는 default로 autocommit이 enabled 되어 있다.
+- 다른 DBMS에서도 대부분 같은 기능을 제공한다.
+
+ AUTOCOMMIT 활성화 여부 확인
+1 == True
+
+```java
+
+mysql> SELECT @@AUTOCOMMIT;
++--------------+
+| @@AUTOCOMMIT |
++--------------+
+| 1 |
++--------------+
+1 row in set (0.01 sec)
+
+```
+
+- AUTOCOMMIT이 활성화 되어있는 상태에서 SQL문 수행 시 자동적으로 COMMIT.
+
+```java
+mysql> INSERT INTO account (balance, name) VALUES (400000, '호식');
+Query OK, 1 row affected (0.03 sec)
+
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 1 | 220000 | 영희 |
+| 2 | 980000 | 철수 |
+| 3 | 400000 | 호식 |
++----+---------+--------+
+3 rows in set (0.00 sec)
+```
+
+### AUTOCOMMIT이 비활성화 된다면?
+
+```java
+mysql> SET AUTOCOMMIT=0;
+Query OK, 0 rows affected (0.00 sec)
+
+mysql> DELETE FROM account where balance <= 900000;
+Query OK, 2 rows affected (0.04 sec)
+
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 2 | 980000 | 철수 |
++----+---------+--------+
+1 row in set (0.00 sec)
+```
+
+AUTOCOMMIT을 OFF 한 후에 DELETE 수행했기에 ROLLBACK 수행 시 다시 이전 상태로 돌아갈 수 있다.
+
+```java
+mysql> ROLLBACK;
+Query OK, 0 rows affected (0.01 sec)
+
+mysql> select * from account;
++----+---------+--------+
+| id | balance | name |
++----+---------+--------+
+| 1 | 220000 | 영희 |
+| 2 | 980000 | 철수 |
+| 3 | 400000 | 호식 |
++----+---------+--------+
+3 rows in set (0.09 sec)
+```
+
+그렇다면, 다음과 같은 의문이 들 수 있다
+위에서 본 서로 예금을 주고 받는 쿼리 역시 AUTOCMMIT이 되는 것 아니야 ?
+하지만, MySQL에서는 START TRANSACTION 실행과 동시에 AUTOCOMMIT은 '비'활성화된다.
+그래서, 트랜잭션을 시작한 후에는 자동적으로 COMMIT이 되지않고, 비로소 COMMIT이라는 명령을 내려야 DB에 반영된다.
+
+그리고 COMMIT/ROLLBACK과 함께 트래잭션 종료 시, "원래" AUTOCOMMIT 상태로 돌아간다.
+그래서 START TRANSACTION 수행 이전에 오토커밋이 활성화 되어있다면, 트랜잭션 종료시 기존의 활성화된 상태로 돌아간다.
+
+## 일반적인 트랜잭션 사용 패턴
+
+1. Transaction 시작(begin) 한다.
+2. 데이터를 읽거나 쓰는 등의 SQL문들을 포함해서 로직을 수행한다.
+3. 일련의 과정들이 문제없이 동작했다면 transaction을 commit 한다.
+4. 중간에 문제 발생 시 ROLLBACK.
+
+### pseudocode로 알아보는 트래잭션 예시
+
+```java
+
+public void transfer (String fromld, String told, int amont) {
+
+ try {
+
+ Connection connection = ...; // get DB connection.
+ connection.setAutoCommit(false); // AUTOCOMMIT 속성을 false로 지정 == 'START TRANSACTION' 💫
+ ...
+ ... // 비지니스 로직 구현
+
+ connection.commit(); // 로직 성공적으로 수행 시 커밋 수행
+
+ } catch (Exception e) {
+
+ ...
+ connection.rollback(); // 예외 발생 시 ROLLBACK 처리.
+
+ } finally {
+
+ connection.setAutoCommit(true); // 커밋이 됬든 롤백이 됬든 ROLLBACK 속성은 true로 변경. 이유 : 해당 커넥션은 일회용이 아닌 재사용되므로 원래가지고 있던 기존의 상태로 변경 필요. 따라서, '단일' SQL문을 실행해도 바로바로 COMMIT이 됨.
+
+ }
+}
+```
+
+하지만 지금은 트랜잭션 처리 로직과 비지니스 로직이 짜장면 아니, 짬뽕되어 있음.
+
+따라서 스프링 부트로 개발 시 , @Transactional 이라는 어노테이션 사용 시 트랜잭션과 관련된 부가적인 코드는 숨길 수 있음.
+
+따라서 실제 이체와 관련된 코드는 다음과 같이 작성됨.
+
+```java
+
+public void transfer(String fromId, String toId, int amount) {
+
+ ... //update at fromId
+
+ ... // update at toId
+
+}
+
+```
+
+## ACID
+
+### Atomicity
+
+- 위에서 살펴본 이체의 경우 모든 SQL 로직이 순리대로 돌아가야 의미가 있는 작업이 됨.
+- 따라서 기면 기고 아니면 아닌 정책
+- 모두 성공하거나 모두 실패하거나
+- 원자성
+- ALL OR NOTING
+- 살라면 사고 아니면 마이소!
+- transaciton은 논리적으로 쪼갤 수 없는 단위이기에 내부의 SQL문들이 '모두' 성공해야 한다.
+- 중간에 실패가 발생하면 지금까지 수행된 모든 작업을 취소해 마치 아무일도 없었던 것처럼 rollback.
+- 그럼 DBMS가 담당하는 부분과 개발자가 담당하는 부분의 경계는>
+
+#### commit 실행 시 DB에 영구적으로 저장하는 것 -> DBMS
+
+#### rollback 실행 시 이전 상태로 되돌리는 것도 -> DBMS
+
+#### commit / rollback '실행시점' 결정 -> 개발자 ! 즉, 트랜잭션의 단위를 얼마만큼의 SQL문의 단위 집합으로 정의를 내릴 것이냐 + 어떤 문제가 발생 시 rollback을 수행할 것이냐
+
+문제가 발생한다고 하더라도 무조건 롤백 수행이 아닌 다른 로직으로 처리해 해당 로직을 처리할 수도 있기에 그렇다.
+
+### Consistency
+
+가령, CREATE TABLE account ( ... , balacne INT, check(balance>=0) ) 과 같이 특정 계좌에 대한 최소금액은 0원 이상이 되어야 한다는 조건을 걸었다고 가정하자.
+
+해당 조건 아래, 특정 개인이 이체를 수행 후 자신의 계좌가 0원 미만으로 떨어진는 SQL문을 실행한다면 해당 SQL문은 데이터베이스의 일관성을 깨뜨리는 행위가 된다.
+
+따라서, 해당 transaction은 해당 쿼리문을 실행시키지 않고 ROLLBACK을 수행한다.
+
+- transaction DB 상태를 consistent 상태에서 또 다른 consistent 상태로 바꿔줘야 한다.
+- constraints, trigger 등을 통해 DB에 정의된 rules을 transaction이 위반했다면 롤백을 해야한다.
+- transaciton이 DB에 정의된 rule을 위반했는지 DBMS가 commit 전에 확인하고 알려준다.
+- 하지만, DBMS에만 100프로 의존할 수 없으므로 DB에 정의된 룰 이외에도 어플리케이션 관점에서 트랜잭션이 consistent하게 동작하는지 개발자가 챙겨야 한다.
+
+### Isolation
+
+현재 철수의 계좌에는 100만원이 있다.
+
+영희가 철수에게 20만원을 입금하였고 해당 입금을 수행하기위해 현재 잔액인 100만원을 읽어왔다. 하지만 하필 동시다발적으로 철수가 본인 계좌에 현금 30만원을 입금하였다.
+따라서 30만원에 대한 트랜잭션이 우선적으로 발생해 현재 철수의 현재 계좌 잔액에 대한 read가 수행되고 영희가 보낸 20만원은 입금되기 이전이므로 입금 전의 금액인 100만원을 읽어온다.
+
+그러고 본인이 입금한 30만원의 금액만 추가된 금액 130만원에 대한 write 연산이 수행되고 commit 후 해당 트랜잭션은 끝을 맺는다.
+
+하지만 우리에겐 영희가 20만원을 입금하는 트랜잭션이 수행중임을 잊으면 안된다. 영희는 최초에 100만원에 대한 read를 수행했기에 현재 30만원이 입금되기 전의 계좌 잔액으로 인식한다.
+
+따라서, 100만원에 20만원을 더한 120만원을 write 한다.그러고 나서 해당 트랜잭션이 종료되고 철수가 입금한 30만원에 대한 입금액은 사라지게 되는 이상한 현상이 발생한다.
+
+즉, 여러 트랜잭션이 동시다발적으로 이루어짐에 따라 발생하는 기이한 현상 중 하나이다.
+
+- 여러 트랜잭션들이 동시에 실행됨에도 불구하고 마치 각각의 트랜잭션들이 혼자 실행되는 것처럼 동작하게 만든다
+- DBMS는 여러 종류의 isolation level을 제공한다.
+- 개발자는 isolation level 중에 어떤 레벨로 트랜잭션을 처리할지 설정할 수 있다.
+- concurrecny control(동시성 제어)의 주된 목표가 isolation 이다.
+
+### Durability
+
+특정 쿼리 commit 후 해당 트랜잭션은 DB에 영구적으로 저장된다.
+
+여기서 영구적이라는것은 전원이 나간다거나 혹은 DB에 Crash가 발생해 DB 서버가 죽어버림에도 불구하고 commit된 트랜잭션은 한 번 데이터베이스에 기록됬으므로 DB에 여전히 남아있다라는 의미이다.
+
+- 일반적으로 비휘발성 메모리에 저장됨
+- 기본적으로 트랜잭션의 지속성은 DBMS가 보장
+
+# 트랜잭션들이 동시에 실행될 때 발생 가능한 이상 현상들 (Isolation Level)
+
+x = 10 , y = 20 이 있다고 하자.
+
+Transaction 1 : x에 y를 더한다
+Transaction 2 : y를 70으로 바꾼다.
+
+### [ 문제 가능성 지점 ] - Dirty Read
+
+1. Transaction1을 수행하기 위해 read(x) => 10
+2. 그리고 y를 더하기 위해 y값을 읽어야 하는데 해당 타이밍에 Transaciton 2가 끼어들어 Write(y=70) 수행.
+3. y = 70 으로 업데이트 됨.
+4. Transaction 1 이 재수행 되어서 read(y) => 70
+5. write(x=80) (10+70)
+6. x = 80 , y = 70
+7. T1 commit 후 종료.
+
+그런데,
+
+T2에 대한 문제가 생겨 ABORT 됨. 따라서 롤백이 수행되어 y=20 으로 변경됨
+
+여기서 문제는 T1에 대한 80의 결과는 T2가 y를 70으로 변경했기 때문에 나올 수 있었던 결과이다.
+그런데 T2가 롤백을 해버렸기 때문에 70의 값은 유효한 값이 아니다.
+
+따라서, 연장선상의 관점에서 T1에서 기록된 80 역시 정상적인 값이 아니게 된다.
+
+이러한 현상을 Dirty Read 라고함.
+==> commit되지 않은 변화를 읽음
+
+### [ 문제 가능성 지점 2 ] - Non-Repeatable Read
+
+x = 10 이다.
+
+T1 : x를 두 번 읽는다.
+T2 : x에 40을 더한다.
+
+1. T1이 실행되어 read(x) => 10
+2. T2가 실행되고 40을 더해주기 위해 read(x)를 우선적으로 수행하고 40을 더하는 write(x=50)을 수행한다.
+3. T2 commit
+4. T1이 read(x) => 50 수행.
+
+여기서 문제의 지점은 "같은" T1 안에서 "같은" 데이터를 읽었음에도 불구하고 서로 다른 값을 읽게되는 것.
+트랜잭션의 고립성의 속성은 여러 트랜잭션이 동시다발적으로 수행됨에도 불구하고 각각의 트랜잭션들이 마치 "혼자서" 수행되는 것처럼 동작해야 한다는 것인데, 그러면 T1은 같은 데이터를 두번 세번 아니 백번을 읽어도 같은 값을 읽어야 한다.
+
+==> Non-Repeatable Read == Fuzzy Read (반복할 수 없는 읽기)
+
+### [ 문제 가능성 지점 3 ] - Phantom read
+
+Tuple t1 (..., v=10)
+Tuple t2 (..., v=50) 이 있다.
+
+T1 : v가 10인 데이터를 두 번 읽는다.
+T2 : t2의 v를 10으로 바꾼다.
+
+1. v가 10인 튜플을 읽는다 : read(v=10) => t1
+2. T2가 실행되어 t2의 v값을 10으로 바꾸는 write(t2,v=10) 수행 => t2(..., v=10)
+3. T2 COMMIT 수행
+4. T1은 두 번 읽는 것이기에 v=10인 튜플을 읽으려고 시도.
+5. read(v=10) => t1,t2 둘 다 반환 후 COMMIT
+
+여기서 문제점은 동일한 조건으로 두 번을 읽었는데 각각의 결과가 t1, (t1,t2)로 다름.
+따라서 하나의 트랜잭션 안에서 "같은" 조건을 수행했음에도 불구하고 고립성의 가치에 부합하지 못하는 "다른"결과가 나옴
+
+===> Phantom read (없던 데이터가 생김)
+
+결론적으로, Dirty Read, 반복할 수 없는 읽기, Phantom Read는 피할 수 있어야 한다.
+하지만 그렇게되면 제약사항이 많아져 동시 처리 가능한 트랜잭션 수가 줄어들어 결국 DB의 전체 처리량이 하락한다.
+
+그러므로 일부 이상한 현상은 허용하는 몇 가지 레벨을 만들어 사용자가 필요에 따라 적절하게 선택할 수 있게함.
+
+---
+
+## Isolation Level
+
+1. Read uncommited => 세가지 모두 허용
+
+- 좋게 말하면 가장 자유로운 레벨이기에 동시성 수준이 좋아 전체 처리량을 좋음 반대로는 위에서 언급한 사례들이 가장 빈번하게 나올 수 있는 수준
+
+2. Read committed (커밋된 데이터만 읽음) => Dirty Read (X), 반복할 수 없는 읽기(O), Phantom Read(O)
+
+3. Repeatable read -> Dirty Read (X), 반복할 수 없는 읽기(X), Phantom Read(O)
+
+4. Serialize -> Dirty Read (X), 반복할 수 없는 읽기(X), Phantom Read(X)
+
+- 시리얼라이즈는 위에서 언급한 3가지 상황에 추가적으로 어떠한 이상한 상황이 발생하지 않는 레벨을 뜻함.
+
+세가지 현상을 정의하고 어떤 현상을 허용하는지에 따라 각각의 고립성 수준이 구분된다.
+어플리케이션 설게자는 고립성 수준을 통해 전체 처리량과 데이터 일관성 사이에서 어느 정도 trad-off 를 고려해야 한다.
+
+---
+
+지금까지 언급한 3가지의 이상 징후는 1992년도 11월에 발표된 SQL 표준에서 정의된 내용 (Information technology - Database languaes - SQL) 이다.
+
+하지만 해당 표준 내용을 비판하는 논문이 95년도에 발표되는 해당 내용은 다음과 같다.
+
+1. 세 가지 이상 현상의 정의가 모호하다.
+2. 이상 현상은 세가지 이외에도 더 있다.
+3. 상업적인 DBMS에서 사용하는 방법을 반영해서 고립성 수준을 구분하지 않았다.
+
+---
+
+## 95년도에 발간된 논문에서 정의한 이상한 현상
+
+### [ 이상 현상 1]
+
+x = 0 이다.
+
+T1: x를 10으로 바꾼다.
+T2: x를 100으로 바꾼다.
+
+1. T1 먼저 수행 시 write(x=10) 수행
+2. x= 10 으로 변경
+3. T2가 write(x=100) 수행 시 x= 100으로 변경.
+4. T1 abort가 되어서 롤백이 되면 x = 0 으로 바꿔줘야 하는데 이렇게 되면 3번에서 수행된것이 무용지물 되기에 롤백 작업 수행을 안했다고 가정.
+5. 그러던 중 T2 역시 abort가 되면 이전의 값으로 변경해야 하는데 그 값은 10.
+6. 하지만 10 역시 4번에서 abort가 된 값이기에 10으로 돌려놓으면 안된다.
+
+이처럼 두개의 트랜잭션이 "write" 수행하고 롤백을 하는 상황에서 이상한 현상이 발생하는 것을 => Dirty Write.
+--> 커밋이 안된 데이터를 write 할 때 발생 가능.
+
+추가적으로 T2에서 write(x=100)이 COMMIT이 된 후 T1이 abort가 되어 x=0으로 돌려놓게 되면 T2의 wirte(x=100)이 COMMIT까지 됬음에도 사라지게 된다.
+
+따라서 롤백시 정상적인 recovery는 매우 중요하기 때문에 모든 고립성 수준에서 Dirty Write를 허용하면 안된다.
+
+### [ 이상 현상 2]
+
+x = 50이다.
+
+T1 : x에 50을 더한다.
+T2 : x에 150을 더한다.
+
+1. T1 수행하여 read(x) => 50
+2. T2가 수행되어 x를 읽는다 (50), 150을 더해 write(x=200)
+3. x=200으로 업데이트되고 COMMIT 수행
+4. 이어 T1은 사전에 읽은 x의 값 50에 50을 더해 write(x=100)수행 후 COMMIT
+
+해당 과정의 문제는 T2의 COMMIT 결과가 완전히 사라지는 형국임.
+만약 T1,T2가 차례를 지켜 실행되었가면 x의 결괏괎은 250 이었을 것.
+하지만 겹쳐 진행되다 보니 T2의 작업이 아예 사라짐
+===> Lost Udpate
+
+은행 계좌 이체로 비유 시 50만원을 입금하고
+
+### [ 이상 현상 3]
+
+이상 현상1에서 특정 transaction의 abort가 발생되어 ROLLBACK이 발생하면 중간에 특정 transaction이 바꿔놓은 값을 읽게된 다른 transaction은 유효하지 않은 데이터를 읽게된 형국을 살펴보았다.
+
+하지만, 꼭 ROLLBACK을 수행하지 않아도 Dirty Read가 되는 상황을 살펴보겠다.
+
+x = 50 , y = 50
+
+T1 : x가 y에 40을 이체한다.
+T2 : x와 y를 읽는다.
+
+1. T1이 사직되어 read(x=50) 수행.
+2. x에서 40을 빼고 write(x=10) 수행.
+3. x=10 으로 변화시켜줌.
+4. T2가 수행되어 read(x=10) 수행
+5. 연이어 read(y=50) 수행
+6. T2 COMMIT 후 종료
+7. T1은 x에서 40 뺀 값을 y에 더하기 위해 read(y=50) 수행.
+8. 40을 더해 write(y=90) 수행 후 COMMIT.
+
+겉보기엔 문제가 없는 것 처럼 보인다. 하지만 자세히 살펴보면 x=10, y=90이라는 결괏값을 합치면 100이지만 T2에서 읽은 값들을 합치면 60이 되는 즉, 데이터 정합성이 깨지는 데이터 불일치가 발생
+
+COMMIT되지 않은 데이터를 읽을 때 이상현상1에서는 롤백이 수반되어야지만 문제가 발생하는 것처럼 얘기했지만 지금같은 경우엔 롤백이 발생하지 않더라도 Dirty Read라고 주장한다.
+
+### [ 이상 현상 3-2]
+
+1. T2이 read(x=50) 수행.
+2. T1이 read(x=50) 수행.
+3. T1을 지속적으로 수행하기 위해 x = 50에서 40을 빼고 write(x=10) 수행
+4. x = 10 으롭 변경
+5. y에 40을 더해주기 위해 우선적으로 y값 읽음 read(y=50)
+6. 50+40을 수행해 write(y=90) 수행
+7. y=90 으로 변경
+8. T1 COMMIT 수행
+9. T2의 나머지 수행동작인 read(y=90) 수행
+
+문제점은 디비 상 x,y값의 합은 100인데 T2가 각각 읽게된 값의 합은 140된다. (데이터 불일치)
+==> Read Skew (inconsistent한 데이터 읽기)
+
+## SNAPSHOT ISOLATION
+
+앞서 95년도에서 발표한 내용 중 3번의 내용이 "상업적인 DBMS에서 사용하는 방법을 반영해서 고립성 수준을 구분하지 않았다." 라는 점이었는데 논문에서는 대안으로 소개한 ISOLATION LEVEL이 있다. (SNAPSHOT ISOLATION)
+
+기존에 발표한 논문에서는 이상현상들을 사전에 정의하고 해당 이상 현상들에 대한 허용 유무에 따라 고립성 수준에 따른 정도를 구분했다면, SNAPSHOT ISOLATION은 Concurrency Contorl이 어떻게 구현될지에 대한 정의를 바탕으로 정의된 ISOLATION LEVEL 이다.
+
+즉, 고립성 수준을 "어떻게 구현" 할 것인지에 따라 결정됨.
+
+### [ 예제 ]
+
+x = 50, y = 50 이다.
+
+T1 : x가 y에 40을 이체한다.
+T2 : y에 100을 입금한다.
+
+1. T1 시작 -> read(x=50)
+2. 해당 트랜잭션의 고립성 수준은 스냅샷을 통해서 구현하는데 스냅샷을 찍는 시점은 해당 트랙재션이 "시작"하는 지점이다.
+3. 따라서, T1이 read(x=50)을 읽는 첫 트랜잭션이 시작되는 시점에서의 x=50을 스냅샷에 기록한다.
+4. T1은 x에서 40을 뺀 10을 DB에 바로 기록하는것이 아닌 사전에 찍어놓은 스냅샷에 기록.
+5. 따라서 스냅샷에는 x=10이 기록되어있고 DB에서는 아직 변화되지 않은 50의 값이 기록되어 있다.
+6. T2가 시작되어 read(y=50) 수행 => x와 마찬가지로 y=50의 값을 스냅샷에 기록.
+7. 100 입금 후 write(y=150)을 수행 후 스냅샷에 기록 : y=150
+8. T2가 COMMIT 하는 순간 y=150이라는 값이 DB에 적용
+9. 따라서 이 이후 y의 값을 읽어야만 하는 트랜잭션들은 150의 값을 읽게 된다.
+10. T1의 남은 연산 (y에 40을 더해주는 것)을 수행하기 위해 read(y) 수행
+
+11번으로 들어가기전에 ! 여기서 T1이 읽게 되는 값은 150일까? NO!!!
+그 이유는 T1이 최초에 스냅샷을 찍은 시점은 y=50이었기에 최초의 시점을 기준으로 해당 값을 읽게됨.
+
+11. 따라서 y=50에 40을 더해 write(y=90) 수행
+12. T1의 스냅샷에 y=90 기록
+
+그러고나서 T1이 커밋을 하려고하는데 y에 대해 동일하게 write한 흔적이 존재.
+따라서 T1을 커밋하게 되면 y=90으로 DB의 값도 변경이 되고 T2가 수행한 y에 대한 업데이트는 무용지물이 됨.
+
+하지만, 스냅샷 고립수준에서는 같은 데이터에 대해서 중복 쓰기가 발생했을 때 "먼저" 커밋된 트랜잭션만 인정해주어 뒤에 커밋을 시도하려는 트랜잭션에 대해서는 Abort 처리.
+
+따라서, T1에 기록된 스냅샷의 기록은 모두 폐기된다.
+
+이렇게 동작하는 것을 MVCC(= Multiversion concurrency control)의 한 종류라고 한다.
+
+정리하자면 해당 고립의 큰 특징 두 가지는
+
+- 트랜잭션 시작 전에 commit된 데이터만 보임
+ -> T1이 y값을 읽을 때 T2에 의해 150이 되었음에도 불구하고 T1의 시작 시점 시 y의 값은 50이었기에 y=50이라고 읽음
+
+- First - commiter WIN !
+ -> 같은 데이터에 대해 write conflict가 발생 시 먼저 커밋된 트랜잭션이 승리자 그 뒤의 충돌되는 커밋은 삭제됨
+
+## 실무에서 사용되는 RDBMS에서의 고립성 수준 정의
+
+- MySQL (innoDB) -> 표준에서 정의한 고립성 수준과 동일하게 정의 (Serializable, Repeatable Read, Read Committed, Read Uncommitted)
+
+- Oracle -> Read Committed, Serializable(SNAPSHOT ISOLATION)
+
+- SQL SEVER -> 표준SQL에서 정의한 고립성 수준을 택함 (Dirty Read, Non-Repeatable Read, Phantom)
+
+- PostgreSQL -> Serializable, Repeatable Read(SNAPSHOT), Read Committed, Read Uncommitted
+
+# LOCK을 활용한 Concurrency Control 구현하기
+
+실제로 데이터를 읽고 쓰는 일은 파일처리 등과 같이 복잡한 로직이 함께 끼어있을 수 도 있으며 또한 같은 데이터에 read/write 동작이 동시적으로 수행된다면 예상치 못한 동작을 유발할 수 있다.
+
+다음과 같은 상황을 가정하자.
+
+#### [situation 1.]
+
+x = 10이다.
+
+T1 : x를 20으로 바꾼다.
+T2 : x를 90으로 바꾼다.
+
+1. T1이 작업을 수행하기 위해선 write_lock(x)을 수행해야 한다.
+2. 동시에 T2가 수행 시작. -> write_lock(x) 시도. 하지만 이미 x에 대한 락은 T1이 쥐고 있기에 T2는 기다려야 한다.
+3. T1은 write(x=20) 수행하고 DB에서 x의 값은 20으로 바뀐다.
+4. T1은 자신의 업무가 끝났기에 unlock(x) 수행
+5. 기다리던 T2가 반납된 락의 티켓을 거머쥐고 write(x=90) 수행
+6. x = 90으로 기록됨
+7. T2는 unlocK(x) 수행
+
+#### [situation 2.]
+
+x= 10.
+
+T1 : x를 20으로 바꾼다
+T2 : x를 읽는다
+
+1. T1이 write_lock(x) 수행
+2. T2는 x를 읽기 위해 read_loc(x) 수행 그렇지만 이미 T1이 티켓을 가지고 있기에 T2는 기다려야함.
+3. T1은 write(x=20)
+4. x = 20
+5. unlock(x)
+6. T2가 티켓 쥐고 read_lock(x)
+7. read(x) => 20
+8. unlock(x)
+
+여기까지 정리하면,
+
+write_lock(exclusive lock)은 read/write 할 때 사용 핵심은 exclusive하다라는 특징
+즉, write_lock에 대한 티켓을 특정 트랜잭션이 거머쥐면 다른 트랜잭션은 해당 데이터에 대해서 Read/Write 수행 불가
+
+read-lock(shared lock)은 read 할 때 사용. write 할 땐 read-lock 사용 X. 해당 락은 다른 트랜잭션이 같은 데이터를 동시에 read하는 것을 허용 대신에 내가 읽고 있을 때 다른 트랜잭션의 write 시도는 차단 !
+
+#### [situation 3.]
+
+x = 10
+T1 : x를 20으로 바꾼다
+T2 : x를 읽는다.
+
+1. T2가 먼저 시작되어 read_lock(x) 수행
+2. T1이 시작돼 write_lock(x)를 시도하지만 이미 락이 걸려있기에 T1은 대기.
+3. T2가 read(x=10) 수행 후 unlock(x)
+4. T1이 write_lock(x) 획득
+5. write(x=20) 수행 후 unlock(x)
+
+#### [situation 4.]
+
+x = 10
+T1 : x를 읽는다.
+T2 : x를 읽는다.
+
+1. T2가 먼저 시작되어 read_lock(x) 수행
+2. T1이 시작되어 read_lock(x) 수행
+3. read_lock 같은 경우에 같은 트랜잭션이 같은 데이터에 대해서 단순 "읽기" 수행을 하는 경우라면 허용
+4. T1도 read_lcok 획득
+5. T1:read(x=10), T2:read(x=10) 둘 다 수행 가능
+
+### 프로그래머스 문제 (https://school.programmers.co.kr/learn/courses/30/lessons/59413)
+
+정답
+
+```
+SELECT HOUR, COUNT(ANIMAL_ID) AS 'COUNT'
+FROM (
+ SELECT 0 AS HOUR UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4
+ UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9
+ UNION SELECT 10 UNION SELECT 11 UNION SELECT 12 UNION SELECT 13 UNION SELECT 14
+ UNION SELECT 15 UNION SELECT 16 UNION SELECT 17 UNION SELECT 18 UNION SELECT 19
+ UNION SELECT 20 UNION SELECT 21 UNION SELECT 22 UNION SELECT 23 UNION SELECT 24
+) AS hours
+LEFT JOIN ANIMAL_OUTS ON EXTRACT(HOUR FROM DATETIME) = hours.HOUR
+GROUP BY hours.HOUR
+ORDER BY hours.HOUR ASC;
+
+```
+
+우선 처음엔 아래와 같이 해당 시간대만 추출해서 해당 시간대에 아이디가 있으면 집계시켜줌.
+
+```
+SELECT EXTRACT(HOUR FROM DATETIME) AS 'HOUR', COUNT(ANIMAL_ID) AS 'COUNT'
+FROM ANIMAL_OUTS
+GROUP BY HOUR
+ORDER BY HOUR ASC;
+
+```
+
+근데 이렇게 하면 시간대(0-24시간)에 없는 것들은 집계가 안됨
+
+따라서 임시 테이블 즉, 0-24시간을 다 담고 있는 테이블을 만들어야함.
+
+```
+FROM (
+ SELECT 0 AS HOUR UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4
+ UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9
+ UNION SELECT 10 UNION SELECT 11 UNION SELECT 12 UNION SELECT 13 UNION SELECT 14
+ UNION SELECT 15 UNION SELECT 16 UNION SELECT 17 UNION SELECT 18 UNION SELECT 19
+ UNION SELECT 20 UNION SELECT 21 UNION SELECT 22 UNION SELECT 23 UNION SELECT 24
+) AS hours
+```
+
+위와같이 입력 시
+
+```
+HOUR
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+```
+
+다음과 같은 테이블이 생성됨.
+
+그러고 나서, hours 테이블을 기준으로 ANIMAL_OUT와 조인 수행. 왼쪽 조인은 ANIMAL_OUT에서 추출한 시간대와 hours 테이블을 조인 (단 여기서 일치하는 값이 없으면 NULL)
+
+- EXTRACT(HOUR FROM DATETIME)은 ANIMAL_OUTS 테이블의 DATETIME 열에서 시간을 추출
+
+중요한 점은
+
+왼쪽 조인(LEFT JOIN)을 사용할 때, 조인 기준 열에 맞지 않는 경우 (즉, 일치하는 행이 없는 경우) 결과로 NULL 값이 나옵니다. 이때 COUNT 함수를 사용하여 집계를 수행하면 NULL 값은 집계되지 않고, 대신 0으로 표시됩니다.
+
+그 다음,
+
+GROUP BY hours.HOUR를 수행해 결과를 시간대(hours.HOUR)로 그룹화합니다. 이렇게 하면 동일한 시간대의 모든 행이 하나의 그룹으로 집계됩니다.
+
+### 문제 2. https://school.programmers.co.kr/learn/courses/30/lessons/131123
+
+정답
+
+```
+SELECT FOOD_TYPE, REST_ID, REST_NAME, FAVORITES
+FROM REST_INFO
+WHERE (FOOD_TYPE, FAVORITES) IN (
+ SELECT FOOD_TYPE, MAX(FAVORITES)
+ FROM REST_INFO
+ GROUP BY FOOD_TYPE
+)
+ORDER BY FOOD_TYPE DESC;
+
+```
+
+풀이
+
+핵심은 IN 의 서브쿼리를 통해 목표 대상을 추출하는 것.
+
+서브쿼리는 음식 종류(FOOD_TYPE)별로 가장 많은 즐겨찾기수(FAVORITES)를 찾아낸다.
+
+그리고 서브쿼리에 나온 결과를 기반으로 REST_INFO의 테이블 중 FOOD_TYPE과 FAVORITES를 추출한다.
+
+만약 GROUP BY FOOD_TYPE 없이 단순히 SELECT FOOD_TYPE, MAX(FAVORITES) FROM REST_INFO라고만 한다면, 데이터의 모든 행을 하나의 그룹으로 간주하고 그 중 가장 큰 즐겨찾기수를 찾게 됩니다. 이것은 모든 음식 종류를 무시하고 전체 데이터 중에서 가장 큰 즐겨찾기수를 반환하게 됩니다.
+
+그러나 GROUP BY FOOD_TYPE을 사용하면 데이터를 음식 종류(FOOD_TYPE)별로 그룹화하고, 각 그룹 내에서 MAX(FAVORITES)를 계산하여 각 음식 종류별로 가장 큰 즐겨찾기수를 찾습니다. 결과적으로 각 음식 종류에 대한 최대 즐겨찾기수가 찾기 가능.
diff --git a/Document/2023/0924/jincheol/.gitkeep b/Document/2023/0924/jincheol/.gitkeep
deleted file mode 100644
index e69de29..0000000
diff --git "a/Document/2023/0924/jincheol/[4\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(9-10\354\236\245).md" "b/Document/2023/0924/jincheol/[4\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(9-10\354\236\245).md"
new file mode 100644
index 0000000..cf3b236
--- /dev/null
+++ "b/Document/2023/0924/jincheol/[4\354\243\274\354\260\250]_Jinchoel_\353\215\260\354\235\264\355\204\260\353\262\240\354\235\264\354\212\244 \354\262\253\352\261\270\354\235\214(9-10\354\236\245).md"
@@ -0,0 +1,477 @@
+# 9장 백업과 복구
+
+## 회복의 개요
+
+- 여러 응용프로그램이 주기억 장치 버퍼 내의 동일한 데이터베이스 항목을 갱신한 후에 디스크에 기록함으로써 성능을 향항시키는 것이 중요
+- 버퍼의 내용을 디스크에 기록하는 것을 가능하면 최대한 줄이는 것이 일반적
+ 예: 버퍼가 꽉 찼을 때 또는 트랜잭션이 완료됬을 때 버퍼의 내용이 디스크에 기록될 수 있음
+- 트랜잭션이 버퍼에는 갱신 사항을 반영했지만 버퍼의 내용이 디스크에 기록되기 전에 고장 발발 가능
+- 따라서 고장 발생 전 " 트랜잭션이 완료 명령을 수행했다면 (이미 끝난 작업) " 회복 모듈은 이 트랜잭션의 갱신 사항을 재수행(REDO)하여 트랜잭션의 갱신이 지속성을 갖도록 해야함
+- 고장이 발생하기 전에 트랜잭션이 완료 명령을 수행하지 못했다면 원자성을 보장하기 위해 트랜잭션이 데이터베이스에 반영했을 가능성이 있는 갱신 사항을 취소(UNDO) 해야함.
+
+### 재해적 고장과 비재해적 고장
+
+1. 재해적 고장
+
+- 디스크가 손상을 입어서 데이터베이스를 읽을 수 없는 고장
+- 재해적 고장으로부터의 회복은 데이터베이스를 백업해 놓은 자기 테이프를 기반으로 함
+
+2. 비재해적 고장
+
+- 그 이외의 고장
+- 대부분의 회복 알고리즘들은 비재해적 고장에 적용됨
+- 로그를 기반으로 한 즉시 갱신, 로그를 기반으로 한 지연 갱신, 그림자 페이징 등 여러 알고리즘
+- 대부분의 상용 DBMS에서 로그를 기반으로 한 즉시 갱신 방식 사용
+
+### 로그를 사용한 즉시 갱신
+
+- 즉신 갱신에서는 트랜잭션이 데이터베이스를 갱신한 사항이 주기억 장치의 버퍼에 유지되다가 트랜잭션이 완료되기 "전"이라도 디스크의 데이터베이스에 기록될 수 있음
+- 데이터베이스에는 완료된 트랜잭션의 수행 결과뿐만 아니라 철회된 트랜잭션의 수행 결과도 반영될 수 있음
+- 트랜잭션의 원자성과 지속성을 보장하기 위해 DBMS는 로그(log) 라고 부르는 특별한 파일을 유지함
+- 데이터베이스의 항목에 영향을 미치는 모든 트랜잭션의 연산들에 대해서 로그 레코드를 기록함
+- 각 로그 레코드는 로그 순서 번호 (LSN : Log Sequence Number)로 식별됨
+
+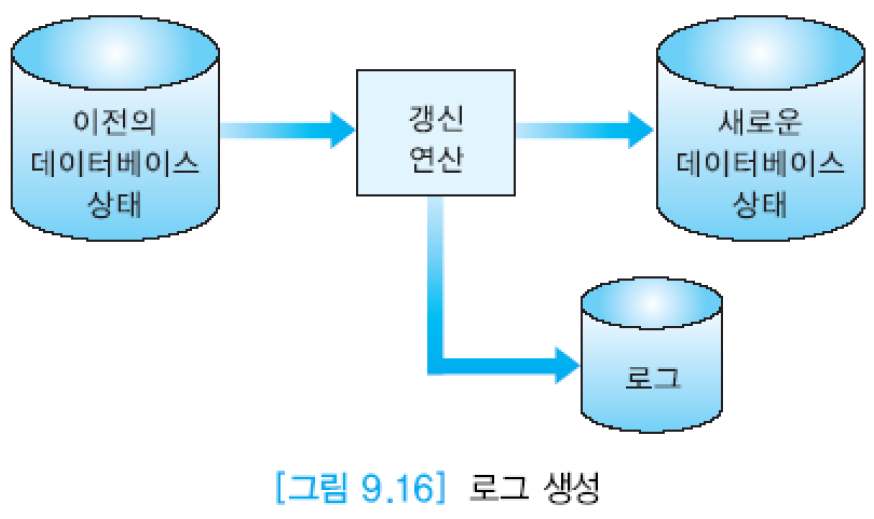 +
+- 주기억 장치 내의 로그 버퍼에 로그 레코드들을 기록하고 로그 버퍼가 꽉 찰 때 디스크에 기록.
+- 로그는 데이터베이스 회복에 필수적이기에 일반적으로 안전 저장 장치(데이터의 손실이 발생하지 않게 여러 개의 비소멸 저장장치로 구성된 저장장치)에 저장됨
+- 이중 로그 (Dual Logging): 로그를 두 개의 디스크에 중복해서 저장하는 것
+- 각 로그 레코드가 어떤 트랜잭션에 속한 것인가를 식별하기 위해서 각 로그 레코드마다 트랜잭션 ID를 포함시킴
+- 동일한 트랜잭션에 속하는 로그 레코드들을 연결 리스트로 유지함
+
+ [로그 레코드 유형]
+
+- [Trans-ID, start] (start는 Log Type)
+ -> 한 트랜잭션이 생성될 떄 기록되는 로그 레코드
+
+- [Trans-ID, X, old_value, new_value] -> 업데이트 트랜잭션
+ -> 주어진 Trans_ID를 갖는 트랜잭션이 데이터 항목 X를 이전값(old_value)에서 새값(new_value)로 수정했음을 나타내는 로그 레코드
+
+- [Trans-ID, commit]
+ -> 주어진 Trans_ID를 갖는 트랜잭션이 데이터베이스에 대한 갱신을 모두 성공적으로 완료하였음을 나타내는 로그 레코드
+
+- [Trans-ID, abort]
+ -> 주어진 Trans-ID를 갖는 트랜잭션이 철회되었음을 나타내는 로그 레코드
+
+### 트랜잭션의 완료점 (Commit Point)
+
+- 한 트랜잭션의 데이터베이스 갱신 연산이 모두 끝나고 데이터베이스 갱신 사항이 "로그에 기록되었을 때"
+- DBMS의 회복 모듈을 로그를 검사하여 로그에 [Trans-ID, start] 로그 레코드와 [Trans-ID, commit] 로그 레코드가 모두 존재하는 트랜잭션들은 재수행
+- [Trans-ID, start] 로그 레코드는 로그에 존재하지만 [Trans-ID, commit] 로그 레코드가 존재하지 않는 트랜잭션들은 취소
+
+
+
+- 주기억 장치 내의 로그 버퍼에 로그 레코드들을 기록하고 로그 버퍼가 꽉 찰 때 디스크에 기록.
+- 로그는 데이터베이스 회복에 필수적이기에 일반적으로 안전 저장 장치(데이터의 손실이 발생하지 않게 여러 개의 비소멸 저장장치로 구성된 저장장치)에 저장됨
+- 이중 로그 (Dual Logging): 로그를 두 개의 디스크에 중복해서 저장하는 것
+- 각 로그 레코드가 어떤 트랜잭션에 속한 것인가를 식별하기 위해서 각 로그 레코드마다 트랜잭션 ID를 포함시킴
+- 동일한 트랜잭션에 속하는 로그 레코드들을 연결 리스트로 유지함
+
+ [로그 레코드 유형]
+
+- [Trans-ID, start] (start는 Log Type)
+ -> 한 트랜잭션이 생성될 떄 기록되는 로그 레코드
+
+- [Trans-ID, X, old_value, new_value] -> 업데이트 트랜잭션
+ -> 주어진 Trans_ID를 갖는 트랜잭션이 데이터 항목 X를 이전값(old_value)에서 새값(new_value)로 수정했음을 나타내는 로그 레코드
+
+- [Trans-ID, commit]
+ -> 주어진 Trans_ID를 갖는 트랜잭션이 데이터베이스에 대한 갱신을 모두 성공적으로 완료하였음을 나타내는 로그 레코드
+
+- [Trans-ID, abort]
+ -> 주어진 Trans-ID를 갖는 트랜잭션이 철회되었음을 나타내는 로그 레코드
+
+### 트랜잭션의 완료점 (Commit Point)
+
+- 한 트랜잭션의 데이터베이스 갱신 연산이 모두 끝나고 데이터베이스 갱신 사항이 "로그에 기록되었을 때"
+- DBMS의 회복 모듈을 로그를 검사하여 로그에 [Trans-ID, start] 로그 레코드와 [Trans-ID, commit] 로그 레코드가 모두 존재하는 트랜잭션들은 재수행
+- [Trans-ID, start] 로그 레코드는 로그에 존재하지만 [Trans-ID, commit] 로그 레코드가 존재하지 않는 트랜잭션들은 취소
+
+ +
+## 로그 먼저 쓰기 (WAL : Write-Ahead Logging)
+
+- 트랜잭션이 데이터베이스를 갱신하며 주기억 장치의 데이터페이스 버퍼에 갱신 사항을 기록하고, 로그 버퍼에는 이에 대응되는 로그 레코드를 기록함 (디스크와 무관)
+- 데이터베이스 버퍼가 로그 버퍼보다 먼저 "디스크"에 기록되는 경우에는 먼저 기록되고 시스템이 다운되면, 로그 레코드가 없어서 이전값을 알 수 없으므로 트랜잭션의 취소가 불가능함. 따라서 데이터베이스 버퍼보다 "로그 버퍼" 를 먼저 디스크에 기록해야 함.
+
+## 체크포인트(checkpoint) 필요성
+
+- 시스템이 다운된 시점으로부터 오래 전에 완료된 트랜잭션들이 데이터베이스를 갱신한 사항은 이미 디스크에 반여되었을 가능성이 큼
+- DBMS가 로그를 사용하더라도 어떤 트랜잭션의 갱신 사항이 주기억 장치 버퍼로부터 디스크에 기록되었는가를 구분할 수 없음 (기록은 했지만 내가 디스크에 어떤 어떤 로그 레코드들을 기록했지?)
+- 따라서 DBMS는 회복시 재수행할 트랜잭션의 수를 줄이기 위해 주기적으로 체크포인트 수행
+
+## 체크포인트 전략
+
+- 체크포인트 시점에는 주기억 장치의 버퍼 내용이 디스크에 "강제"로 기록되므로 체크포인트를 수행하면 디스크 상에서 로그와 데이터베이스의 내용이 일치하게 됨
+- 체크포인트 작업이 끝나면 로그에 [checkpoint] 로그 레코드가 기록됨.
+- 일반적으로 10-20분 마다 한 번씩 수행함
+
+## 체크포인트를 할 때 수행되는 작업
+
+- 수행 중인 트랜잭션들을 일시적으로 중지시킴. 회복 알고리즘에 따라서는 이 작업이 필요하지 않을 수 있음 (= fuzzy checkpoint 즉, 중지하지 않고 체크포인트 뜰 수 있음)
+- 주기억 장치의 로그 버퍼를 디스크에 강제로 출력
+- 주기억 장치의 데이터베이스 버퍼를 디스크에 강제로 출력
+- [checkpoint] 로그 레코드를 로그 버퍼에 기록한 후 디스크에 강제로 출력
+- 체크 포인트 시점에 수행 중이던 트랜잭션들의 ID도 [checkpoint] 로그 레코드에 함께 기록
+- 일시적으로 중지된 트랜잭션의 수행 재개
+
+
+
+## 로그 먼저 쓰기 (WAL : Write-Ahead Logging)
+
+- 트랜잭션이 데이터베이스를 갱신하며 주기억 장치의 데이터페이스 버퍼에 갱신 사항을 기록하고, 로그 버퍼에는 이에 대응되는 로그 레코드를 기록함 (디스크와 무관)
+- 데이터베이스 버퍼가 로그 버퍼보다 먼저 "디스크"에 기록되는 경우에는 먼저 기록되고 시스템이 다운되면, 로그 레코드가 없어서 이전값을 알 수 없으므로 트랜잭션의 취소가 불가능함. 따라서 데이터베이스 버퍼보다 "로그 버퍼" 를 먼저 디스크에 기록해야 함.
+
+## 체크포인트(checkpoint) 필요성
+
+- 시스템이 다운된 시점으로부터 오래 전에 완료된 트랜잭션들이 데이터베이스를 갱신한 사항은 이미 디스크에 반여되었을 가능성이 큼
+- DBMS가 로그를 사용하더라도 어떤 트랜잭션의 갱신 사항이 주기억 장치 버퍼로부터 디스크에 기록되었는가를 구분할 수 없음 (기록은 했지만 내가 디스크에 어떤 어떤 로그 레코드들을 기록했지?)
+- 따라서 DBMS는 회복시 재수행할 트랜잭션의 수를 줄이기 위해 주기적으로 체크포인트 수행
+
+## 체크포인트 전략
+
+- 체크포인트 시점에는 주기억 장치의 버퍼 내용이 디스크에 "강제"로 기록되므로 체크포인트를 수행하면 디스크 상에서 로그와 데이터베이스의 내용이 일치하게 됨
+- 체크포인트 작업이 끝나면 로그에 [checkpoint] 로그 레코드가 기록됨.
+- 일반적으로 10-20분 마다 한 번씩 수행함
+
+## 체크포인트를 할 때 수행되는 작업
+
+- 수행 중인 트랜잭션들을 일시적으로 중지시킴. 회복 알고리즘에 따라서는 이 작업이 필요하지 않을 수 있음 (= fuzzy checkpoint 즉, 중지하지 않고 체크포인트 뜰 수 있음)
+- 주기억 장치의 로그 버퍼를 디스크에 강제로 출력
+- 주기억 장치의 데이터베이스 버퍼를 디스크에 강제로 출력
+- [checkpoint] 로그 레코드를 로그 버퍼에 기록한 후 디스크에 강제로 출력
+- 체크 포인트 시점에 수행 중이던 트랜잭션들의 ID도 [checkpoint] 로그 레코드에 함께 기록
+- 일시적으로 중지된 트랜잭션의 수행 재개
+
+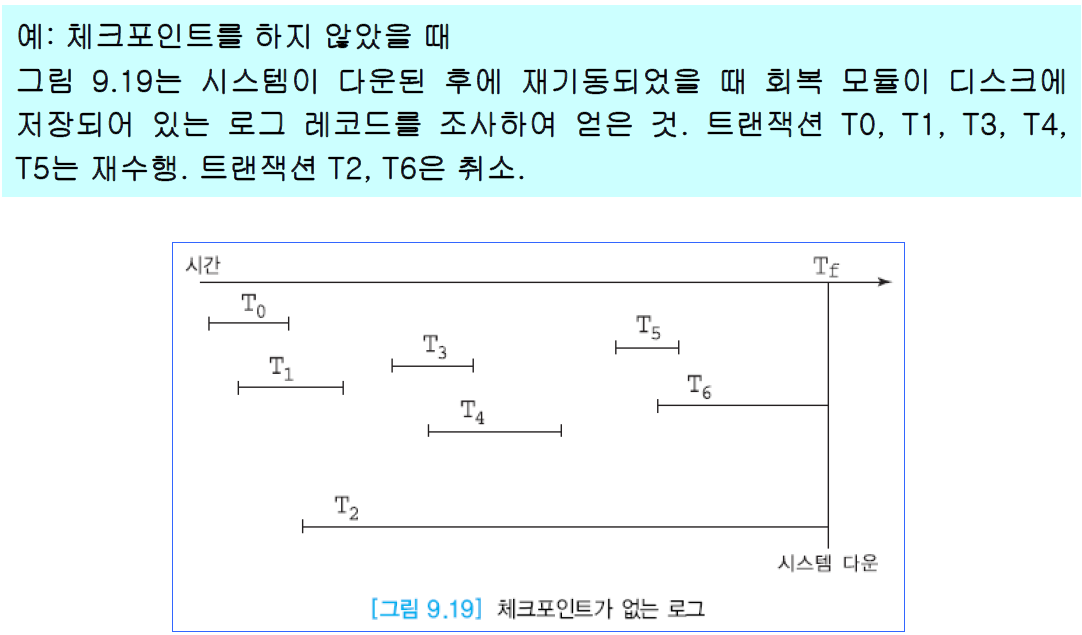 +
+
+
+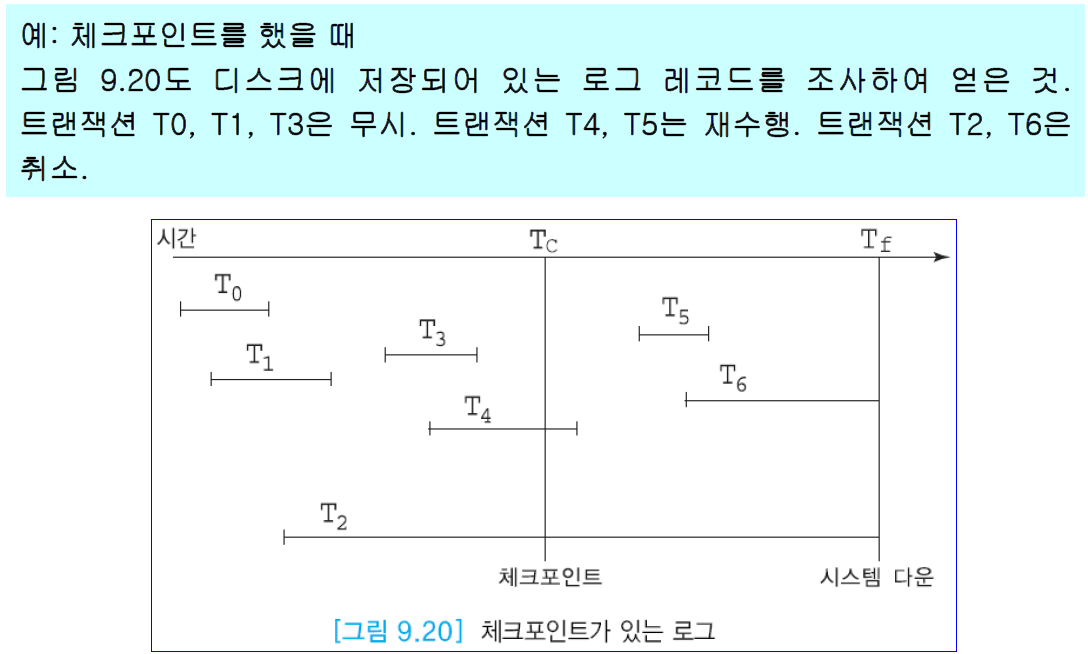 +
+## 데이터베이스 백업과 재해적 고장으로부터의 회복
+
+- 아주 드물지만, 데이터베이스가 저장되어 있는 디스크의 헤드 등이 고장나서 데이터베이스를 읽을 수 없는 경우 발생
+- 이런 경우 데이터베이스를 회복하는 한 가지 방법은 주기적으로 자기테이프에 전체 데이터베이스와 로그를 백업하고, 자기 테이브를 별도의 공간에 안전하게 보관
+- 사용자들에게 데이터베이스 사용을 계속 허용하면서, 지난 번 백업 이후에 갱신된 내용만 백업을 하는 점진적인 백업(incremental backup)이 바람직.
+
+---
+
+# 10장 - 성능을 생각하자
+
+# 실행계획과 옵티마이저
+
+프로 등산가가 경로를 정할 때, 최종적으로 산꼭대기(데이터)에 이르는 것이 목적이라고 한다면 등산자가 선택할 수 있는 경로는 여러 개가 있지만, 그중에서 가장 체력 소모가 적고 충분히 안전한 경로를 선택한 뒤 등산을 시작할 것이다.
+
+이와 동일하게 SQL문에 필요한 데이터를 얻는 방법은 복수 개가 있을 수 있으므로 데이터베이스는 어떤 계획으로 데이터에 도달할지 결정해야 한다.
+
+이 계획을 실행계획 또는 엑세스 플랜이라고 하며 실행계획을 결정하는 내부 프로그램을 "옵티마이저"라고 한다.
+
+즉, SQL 실행문에 대해서 "어떻게" 그 데이터에 대한 조회/삭제/업데이트 등의 작업을 수행할지에 대한 방법론에 관한 것이다.
+
+## 옵티마이저가 참조하는 통계정보
+
+통계정보란 옵티마이저가 실행계획을 세울 때 참조하는 정보이다. 통계정보에 포함되는 대표적인 데이터는 다음과 같다.
+
+1. 테이블의 행수.열수
+2. 각 열의 길이와 데이터형
+3. 테이블의 크기
+4. 열에 대한 기본키나 NOT NULL 제약의 정보
+5. 열 값의 분산과 편향
+
+즉 앞서 등산에 대한 비유의 과정에서 위의 항목들은 '산의 지도나 일기예보'에 해당하는 것이다.
+
+해당 정보들이 상세하면 할수록 최적의 등산 경로를 찾을 수 있는 것이다.
+
+## 풀 스캔과 레인지 스캔
+
+```
+Database changed
+mysql> EXPLAIN select * from City;
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+| 1 | SIMPLE | City | ALL | NULL | NULL | NULL | NULL | 4046 | |
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+1 row in set (0.00 sec)
+```
+
+- type : ALL -> 테이블에 대한 엑세스 방법을 나타냄
+
+테이블로의 액세스 방법은 풀 스캔과 레인지 스캔 2가지가 존재한다. 풀 스캔은 테이블에 포함된 레코드를 처음부터 끝까지 전부 읽어 들이는 방법으로, 테이블 풀 스캔이라고 한다. 레인지 스캔은 테이블의 일부 레코드에만 엑세스하는 방법.
+
+해당 테이블의 경우 ALL이 선택되었기 떄문에 처음부터 마지막까지 모든 페이지 엑세스 수행.
+
+```
+mysql> EXPLAIN select * from City WHERE id between 2391 and 2400;
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+| 1 | SIMPLE | City | range | PRIMARY | PRIMARY | 4 | NULL | 10 | Using where |
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+1 row in set (0.03 sec)
+```
+
+- type이 range로 변경되었으며 읽어들인 rows 수도 10으로 바뀌었다.
+
+## 인덱스의 중요성
+
+- possible_keys와 key열을 살펴보자
+- 레인지 스캔을 하려면 인덱스가 꼭 필요하다.
+
+인덱스가 없으면 어떤 단어가 서적의 몇 페이지에 있는 알 수 없어 책 전체를 훑어야 한다.
+
+따라서, possible_keys와 key열에 있는 'PRIMARY'란 단어는 인덱스를 사용함을 나타낸다.
+기본키의 인덱스라는 것을 의미하며 어떤 DBMS에서도 기본키를 구성하는 열에는 반드시 인덱스가 저장되어 있다.
+
+```
+
+mysql> show index FRom City;
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| city | 0 | PRIMARY | 1 | ID | A | 4046 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | CountryCode | 1 | CountryCode | A | 505 | NULL | NULL | | BTREE | | | NO |
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+2 rows in set (0.02 sec)
+```
+
+- Key_name이 인덱스 열의 이름이다.
+- 위의 예에서는 City 테이블에 PRIMAR, CountryCode Y라는 인덱스가 2개 있다는 걸 의미한다.
+
+City 테이블은 ID 열이 키본키라서 이 열에는 반드시 인덱스가 존재한다. 바꿔 말하면 City 테이블의 다른 열에는 인덱스가 없으므로 가령 ID 이외의 열을 WHERE 구에서 범위 축소 조건으로 이용한다고 해도 레인지 스캔 X
+
+```
+mysql> EXPLAIN select * from City WHERE population between 20000 and 40000;
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+| 1 | SIMPLE | City | ALL | NULL | NULL | NULL | NULL | 4046 | Using where |
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+1 row in set (0.01 sec)
+```
+
+위처럼 인구 수에 대한 실행계획을 살펴보았을 떄 타입이 ALL로 되어있기에 전체 테이블을 샅샅이 훑고 결과를 반환 한다는 것을 알 수 있다.
+
+## 인덱스는 SQL에서 만든다
+
+풀 스캔 문제를 해결하기 위해 인덱스를 생성해 보자.
+
+```
+mysql> create index ind_population on city(population);
+Query OK, 0 rows affected (0.30 sec)
+Records: 0 Duplicates: 0 Warnings: 0
+
+mysql> show index from city;
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| city | 0 | PRIMARY | 1 | ID | A | 4046 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | CountryCode | 1 | CountryCode | A | 505 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | ind_population | 1 | Population | A | 4046 | NULL | NULL | | BTREE | | | NO |
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+3 rows in set (0.01 sec)
+```
+
+ind_population 이라는 인덱스가 생성된 걸 확인할 수 있다.
+따라서 실행계획을 살펴봤을 때 테이블 풀스캔에서 레인지 스캔으로 변경된 걸 살펴볼 수 있다.
+
+```
+mysql> EXPLAIN select * from City WHERE population between 20000 and 40000;
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+| 1 | SIMPLE | City | range | ind_population | ind_population | 4 | NULL | 19 | Using index condition |
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+1 row in set (0.03 sec)
+```
+
+여기서 중요한 점은 단지 인덱스를 생성했을 뿐, 내가 만든 인덱스를 사용하라고 지정하지 않는다.
+그럼에도 불구하고 DBMS는 풀 스캔보다 인덱스를 사용하는 쪽이 빠르다고 판단해 자동으로 인덱스를 사용하는 실행계획으로 바꾸었다.
+
+추가적으로 특정 테이블안에서 특정 컬럼들간의 조합이 각 튜플들을 UNIQUE하게 식별하는 경우 (EX: team_id + backnumber)
+인덱스는 create UNIQUE INDEX team_id_backnumber_idx ON Player(team_id, backnumber)와 같이 생성 가능
+
+-> 이렇게 2개 이상의 에트리뷰트로 구성된 인덱스를 multicolumn index 혹은 composite index라고 칭한다.
+-> 그리고 중요한 점 중에 하나가 더 있는데, create index (a,b)와 같이 할 경우, 즉 2개의 애트리뷰트에 대해서 인덱스를 설정하면 a를 기준으로 정렬이 된다. a의 값이 동일한 로우가 있다면 그 다음 b로 넘어가서 정렬.
+
+그러므로, composite index를 설정하려면 인덱스 애트리뷰트 순서에 유의 !
+
+## 인덱스의 구조
+
+SQL 쿼리 성능을 빠르게 하는 가장 베이직한 방법은 인덱스 설정이다. 인덱스 활용도가 높은 이유는 다음과 같다.
+
+1. SQL문 변경 필요 X
+2. 테이블의 데이터에 영향 X
+3. 일정한 (때론 극적인) 효과 기대 O
+
+즉, 한마디로 비용 대비 성능이 높음.
+
+이러한 인덱스의 구조는 B-tree구조.
+
+비트리는 관계형 데이터베이스에서 튜닝의 기본이 되는 인덱스이다.
+
+## 트리 구조의 우위성
+
+비트리는 반드시 데이터를 정렬된 상태로 유지한다. 데이터가 순서를 유지하고 있다는 것은 비트리의 핵심이다.
+
+
+
+## 데이터베이스 백업과 재해적 고장으로부터의 회복
+
+- 아주 드물지만, 데이터베이스가 저장되어 있는 디스크의 헤드 등이 고장나서 데이터베이스를 읽을 수 없는 경우 발생
+- 이런 경우 데이터베이스를 회복하는 한 가지 방법은 주기적으로 자기테이프에 전체 데이터베이스와 로그를 백업하고, 자기 테이브를 별도의 공간에 안전하게 보관
+- 사용자들에게 데이터베이스 사용을 계속 허용하면서, 지난 번 백업 이후에 갱신된 내용만 백업을 하는 점진적인 백업(incremental backup)이 바람직.
+
+---
+
+# 10장 - 성능을 생각하자
+
+# 실행계획과 옵티마이저
+
+프로 등산가가 경로를 정할 때, 최종적으로 산꼭대기(데이터)에 이르는 것이 목적이라고 한다면 등산자가 선택할 수 있는 경로는 여러 개가 있지만, 그중에서 가장 체력 소모가 적고 충분히 안전한 경로를 선택한 뒤 등산을 시작할 것이다.
+
+이와 동일하게 SQL문에 필요한 데이터를 얻는 방법은 복수 개가 있을 수 있으므로 데이터베이스는 어떤 계획으로 데이터에 도달할지 결정해야 한다.
+
+이 계획을 실행계획 또는 엑세스 플랜이라고 하며 실행계획을 결정하는 내부 프로그램을 "옵티마이저"라고 한다.
+
+즉, SQL 실행문에 대해서 "어떻게" 그 데이터에 대한 조회/삭제/업데이트 등의 작업을 수행할지에 대한 방법론에 관한 것이다.
+
+## 옵티마이저가 참조하는 통계정보
+
+통계정보란 옵티마이저가 실행계획을 세울 때 참조하는 정보이다. 통계정보에 포함되는 대표적인 데이터는 다음과 같다.
+
+1. 테이블의 행수.열수
+2. 각 열의 길이와 데이터형
+3. 테이블의 크기
+4. 열에 대한 기본키나 NOT NULL 제약의 정보
+5. 열 값의 분산과 편향
+
+즉 앞서 등산에 대한 비유의 과정에서 위의 항목들은 '산의 지도나 일기예보'에 해당하는 것이다.
+
+해당 정보들이 상세하면 할수록 최적의 등산 경로를 찾을 수 있는 것이다.
+
+## 풀 스캔과 레인지 스캔
+
+```
+Database changed
+mysql> EXPLAIN select * from City;
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+| 1 | SIMPLE | City | ALL | NULL | NULL | NULL | NULL | 4046 | |
++------+-------------+-------+------+---------------+------+---------+------+------+-------+
+1 row in set (0.00 sec)
+```
+
+- type : ALL -> 테이블에 대한 엑세스 방법을 나타냄
+
+테이블로의 액세스 방법은 풀 스캔과 레인지 스캔 2가지가 존재한다. 풀 스캔은 테이블에 포함된 레코드를 처음부터 끝까지 전부 읽어 들이는 방법으로, 테이블 풀 스캔이라고 한다. 레인지 스캔은 테이블의 일부 레코드에만 엑세스하는 방법.
+
+해당 테이블의 경우 ALL이 선택되었기 떄문에 처음부터 마지막까지 모든 페이지 엑세스 수행.
+
+```
+mysql> EXPLAIN select * from City WHERE id between 2391 and 2400;
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+| 1 | SIMPLE | City | range | PRIMARY | PRIMARY | 4 | NULL | 10 | Using where |
++------+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
+1 row in set (0.03 sec)
+```
+
+- type이 range로 변경되었으며 읽어들인 rows 수도 10으로 바뀌었다.
+
+## 인덱스의 중요성
+
+- possible_keys와 key열을 살펴보자
+- 레인지 스캔을 하려면 인덱스가 꼭 필요하다.
+
+인덱스가 없으면 어떤 단어가 서적의 몇 페이지에 있는 알 수 없어 책 전체를 훑어야 한다.
+
+따라서, possible_keys와 key열에 있는 'PRIMARY'란 단어는 인덱스를 사용함을 나타낸다.
+기본키의 인덱스라는 것을 의미하며 어떤 DBMS에서도 기본키를 구성하는 열에는 반드시 인덱스가 저장되어 있다.
+
+```
+
+mysql> show index FRom City;
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| city | 0 | PRIMARY | 1 | ID | A | 4046 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | CountryCode | 1 | CountryCode | A | 505 | NULL | NULL | | BTREE | | | NO |
++-------+------------+-------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+2 rows in set (0.02 sec)
+```
+
+- Key_name이 인덱스 열의 이름이다.
+- 위의 예에서는 City 테이블에 PRIMAR, CountryCode Y라는 인덱스가 2개 있다는 걸 의미한다.
+
+City 테이블은 ID 열이 키본키라서 이 열에는 반드시 인덱스가 존재한다. 바꿔 말하면 City 테이블의 다른 열에는 인덱스가 없으므로 가령 ID 이외의 열을 WHERE 구에서 범위 축소 조건으로 이용한다고 해도 레인지 스캔 X
+
+```
+mysql> EXPLAIN select * from City WHERE population between 20000 and 40000;
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+| 1 | SIMPLE | City | ALL | NULL | NULL | NULL | NULL | 4046 | Using where |
++------+-------------+-------+------+---------------+------+---------+------+------+-------------+
+1 row in set (0.01 sec)
+```
+
+위처럼 인구 수에 대한 실행계획을 살펴보았을 떄 타입이 ALL로 되어있기에 전체 테이블을 샅샅이 훑고 결과를 반환 한다는 것을 알 수 있다.
+
+## 인덱스는 SQL에서 만든다
+
+풀 스캔 문제를 해결하기 위해 인덱스를 생성해 보자.
+
+```
+mysql> create index ind_population on city(population);
+Query OK, 0 rows affected (0.30 sec)
+Records: 0 Duplicates: 0 Warnings: 0
+
+mysql> show index from city;
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Ignored |
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+| city | 0 | PRIMARY | 1 | ID | A | 4046 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | CountryCode | 1 | CountryCode | A | 505 | NULL | NULL | | BTREE | | | NO |
+| city | 1 | ind_population | 1 | Population | A | 4046 | NULL | NULL | | BTREE | | | NO |
++-------+------------+----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
+3 rows in set (0.01 sec)
+```
+
+ind_population 이라는 인덱스가 생성된 걸 확인할 수 있다.
+따라서 실행계획을 살펴봤을 때 테이블 풀스캔에서 레인지 스캔으로 변경된 걸 살펴볼 수 있다.
+
+```
+mysql> EXPLAIN select * from City WHERE population between 20000 and 40000;
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+| 1 | SIMPLE | City | range | ind_population | ind_population | 4 | NULL | 19 | Using index condition |
++------+-------------+-------+-------+----------------+----------------+---------+------+------+-----------------------+
+1 row in set (0.03 sec)
+```
+
+여기서 중요한 점은 단지 인덱스를 생성했을 뿐, 내가 만든 인덱스를 사용하라고 지정하지 않는다.
+그럼에도 불구하고 DBMS는 풀 스캔보다 인덱스를 사용하는 쪽이 빠르다고 판단해 자동으로 인덱스를 사용하는 실행계획으로 바꾸었다.
+
+추가적으로 특정 테이블안에서 특정 컬럼들간의 조합이 각 튜플들을 UNIQUE하게 식별하는 경우 (EX: team_id + backnumber)
+인덱스는 create UNIQUE INDEX team_id_backnumber_idx ON Player(team_id, backnumber)와 같이 생성 가능
+
+-> 이렇게 2개 이상의 에트리뷰트로 구성된 인덱스를 multicolumn index 혹은 composite index라고 칭한다.
+-> 그리고 중요한 점 중에 하나가 더 있는데, create index (a,b)와 같이 할 경우, 즉 2개의 애트리뷰트에 대해서 인덱스를 설정하면 a를 기준으로 정렬이 된다. a의 값이 동일한 로우가 있다면 그 다음 b로 넘어가서 정렬.
+
+그러므로, composite index를 설정하려면 인덱스 애트리뷰트 순서에 유의 !
+
+## 인덱스의 구조
+
+SQL 쿼리 성능을 빠르게 하는 가장 베이직한 방법은 인덱스 설정이다. 인덱스 활용도가 높은 이유는 다음과 같다.
+
+1. SQL문 변경 필요 X
+2. 테이블의 데이터에 영향 X
+3. 일정한 (때론 극적인) 효과 기대 O
+
+즉, 한마디로 비용 대비 성능이 높음.
+
+이러한 인덱스의 구조는 B-tree구조.
+
+비트리는 관계형 데이터베이스에서 튜닝의 기본이 되는 인덱스이다.
+
+## 트리 구조의 우위성
+
+비트리는 반드시 데이터를 정렬된 상태로 유지한다. 데이터가 순서를 유지하고 있다는 것은 비트리의 핵심이다.
+
+ +
+## 왜 B-tree는 빠른가
+
+비트리의 장점 한가지는 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다인데, 이를 균일성이라고 한다.
+
+예를들어 고양이란 값이 존재하는 페이지를 찾을때도, '말'이란 값이 존재하는 페이지를 찾을 떄도 동일한 시간안에 찾을 수 있다라는 것이다.
+
+이와 반대되는 개념이 선형탐색.
+
+비트리는 트리 중에서도 특히 값에 따른 성능 불균형이 작도록 고안됨.
+
+이는 비트리가 균형트리이기 떄문인데, 균형 트리는 루트로부터 리프까지의 거리가 일정한 트리 구조를 뜻하는 것이다.
+
+하지만 비트리 역시 테이블에 대한 데이터 갱신이 반복되면 서서히 균형이 깨지기에 정기적으로 인덱스 재구성(Rebuild) 수행이 요구시됨.
+
+## SQL 뒤편에서 일어나는 일 - 정렬
+
+```
+mysql> explain select population, count(*) from city group by population;
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4046 | Using temporary; Using filesort |
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+1 row in set (0.02 sec)
+```
+
+type : ALL -> 풀 스캔, key : NULL -> 인덱스 사용 X
+
+주목 지점은 Extra열의 Using temporary; Using filesort -> 정렬을 위한 임시 영역에 파일 처리 했음을 뜻함.
+
+즉, HDD에 저장소가 사용되었고 이는 성능 문제 야기 원인 .
+
+```
+
+mysql> create index ind_population on city(population);
+Query OK, 0 rows affected (0.23 sec)
+Records: 0 Duplicates: 0 Warnings: 0
+
+mysql> explain select population, count(*) from city group by population;
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+| 1 | SIMPLE | city | index | NULL | ind_population | 4 | NULL | 4046 | Using index |
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+1 row in set (0.01 sec)
+```
+
+인덱스 재생성 후 Extra를 살펴보면 Using index임을 알 수 있다.
+이처럼 Group by 구의 키로 지정한 열에 인덱스 존재 시, 필요한 정렬 처리 건너뛸 수 있음
+
+ 정렬 연산이 요구되는 연산
+
+- Group by
+- 집약 함수 (COUNT/SUM/AVG)
+- 집합 연산 (UNION/INTERSECT/EXCEPT)
+
+다음과 같은 연산 수행 시 정렬의 키가 되는 열이 필요하므로 해당 키 열에 인덱스가 존재하면 옵티마이저가 이용해서 정렬을 건너뛴다.
+
+## 인덱스 작성이 역효과가 나는 예
+
+인덱스는 테이블에 새로운 데이터 추가 혹은 기존 데이터 갱신 / 제거 시, 자동으로 인덱스 자신도 갱신 수행
+이것 자체는 우수한 기능이지만 그 대가로 인덱스가 존재하지 않는 떄와 비교 하면 매번 인덱스 갱신도 부수적으로 발생 하기에 오버헤드 여지를 주는 것.
+
+ 의도한 것과 다른 인덱스가 사용된다
+
+한 개의 테이블에 복수의 인덱스를 설정할 경우에 파생될 수 있는 문제점.
+
+사용할 수 있는 인덱스 후보가 많으면 옵티마이저도 헤메게 될 뿐더러 인덱스 역시 백업 대상이기에 백업 시 소요시간이 요구된다.
+
+## 인덱스 생성 기준
+
+- 1. 크기가 큰 테이블만 생성
+
+- 2. 기본키 제약이나 유일성 제약이 부여된 열에는 불필요.
+
+-> 기본키에는 어차피 인덱스가 기존에 존재하며 유일성 재약이 붙어있는 열도 마찬가지
+
+이 2가지 제약이 붙어 있는 열에 암묵적으로 인덱스가 작성된 것은 값의 중복 체크를 하려면 데이터를 정렬해야 하는데 인덱스를 작성해 정렬하는 것이 편리.
+
+- 3. Cardinality가 높은 열에 생성
+
+카디널리티는 상대적인 개념으로서 가령 사람의 주민번호 경우 중복이 될 여지가 적기에( = unique한 값의 갯수가 많다.) 카디널리티가 높고, 이름의 경우 동명이인이 있을 수 있기에 주민번호에 비해 "상대적"으로 카디널리티가 낮다.
+
+커디널리티가 높은 순으로 필터링 하여 조회하기에 높은 순에서 낮은 순으로 구성하는 것이 좋다. ( = 낮은 열에 인덱스 효과를 기대할 수 없는 것은 인덱스 트리를 따라가는 조작이 증가 )
+
+- 테이블 조인을 위해 연결고리로 자주 사용되는 컬럼
+
+조인 쿼리에 사용되는 컬럼의 경우 풀스캔을 타게 되면 조인의 수가 늘어날 수록 풀스캔하는 데이터 수가 많아지므로 병목현상의 대표적인 원인이 된다.
+
+### [외않돼? 타임] 인덱스를 만들었는데 인덱스를 참조하질 않아요 (USE INDEX)
+
+특정 테이블에 index를 걸었더라도 해당 index가 작동하지 않을 수도 있다. 이유는 여러가지겠지만 Mysql이 내부적으로 가장 빠르거나 합리적인 탐색법을 사용하기 때문이다. 그럴 경우엔 Hint 기능을 써서 USE INDEX를 사용해서 인덱스를 강제로 작동시키게 할 수 있다. -> 이렇게 하는 이유는 근본적으로는 인덱스 갯수가 여러개이기 때문.
+
+```
+SELECT *
+FROM IMAGE USE INDEX(USER_ADD_ID)
+WHERE add_id = '2bf-ad7c-1b24'
+```
+
+참고 - 힌트(Hint)기능을 쓰는 이유는 옵티마이저(Optimizer)가 항상 최적의 실행 경로를 만들어 내기는 불가능하기 때문에 개발자가 최적의 경로를 지정해주는 것을 말한다. 옵티마이저 힌트와 인덱스 힌트로 나뉘며 무분별한 힌트의 사용은 성능의 저하를 초래한다
+
+ref :https://stir.tistory.com/236
+
+### 추가 - 클러스터링 인덱스 vs 논-클러스터링 인덱스 (=세컨더리 인덱스)
+
+#### 1. 클러스터링 인덱스 ( 실제 데이터와 "같은" 무리의 인덱스 )
+
+- 테이블의 "PK"에 적용되는 인덱스이다
+- PK값이 비슷한 레코드끼리 묶어 저장하는 것을 클러스터링 인덱스라고 한다.
+- PK값에 의해 해당 레코드의 물리적인 저장 위치가 결정 (PK값이 바뀌면 해당 레코드의 물리적인 저장 위치도 변경됨)
+- PK 값을 기준으로 정렬된 상태를 유지한다.
+
+
+
+## 왜 B-tree는 빠른가
+
+비트리의 장점 한가지는 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다인데, 이를 균일성이라고 한다.
+
+예를들어 고양이란 값이 존재하는 페이지를 찾을때도, '말'이란 값이 존재하는 페이지를 찾을 떄도 동일한 시간안에 찾을 수 있다라는 것이다.
+
+이와 반대되는 개념이 선형탐색.
+
+비트리는 트리 중에서도 특히 값에 따른 성능 불균형이 작도록 고안됨.
+
+이는 비트리가 균형트리이기 떄문인데, 균형 트리는 루트로부터 리프까지의 거리가 일정한 트리 구조를 뜻하는 것이다.
+
+하지만 비트리 역시 테이블에 대한 데이터 갱신이 반복되면 서서히 균형이 깨지기에 정기적으로 인덱스 재구성(Rebuild) 수행이 요구시됨.
+
+## SQL 뒤편에서 일어나는 일 - 정렬
+
+```
+mysql> explain select population, count(*) from city group by population;
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4046 | Using temporary; Using filesort |
++------+-------------+-------+------+---------------+------+---------+------+------+---------------------------------+
+1 row in set (0.02 sec)
+```
+
+type : ALL -> 풀 스캔, key : NULL -> 인덱스 사용 X
+
+주목 지점은 Extra열의 Using temporary; Using filesort -> 정렬을 위한 임시 영역에 파일 처리 했음을 뜻함.
+
+즉, HDD에 저장소가 사용되었고 이는 성능 문제 야기 원인 .
+
+```
+
+mysql> create index ind_population on city(population);
+Query OK, 0 rows affected (0.23 sec)
+Records: 0 Duplicates: 0 Warnings: 0
+
+mysql> explain select population, count(*) from city group by population;
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+| 1 | SIMPLE | city | index | NULL | ind_population | 4 | NULL | 4046 | Using index |
++------+-------------+-------+-------+---------------+----------------+---------+------+------+-------------+
+1 row in set (0.01 sec)
+```
+
+인덱스 재생성 후 Extra를 살펴보면 Using index임을 알 수 있다.
+이처럼 Group by 구의 키로 지정한 열에 인덱스 존재 시, 필요한 정렬 처리 건너뛸 수 있음
+
+ 정렬 연산이 요구되는 연산
+
+- Group by
+- 집약 함수 (COUNT/SUM/AVG)
+- 집합 연산 (UNION/INTERSECT/EXCEPT)
+
+다음과 같은 연산 수행 시 정렬의 키가 되는 열이 필요하므로 해당 키 열에 인덱스가 존재하면 옵티마이저가 이용해서 정렬을 건너뛴다.
+
+## 인덱스 작성이 역효과가 나는 예
+
+인덱스는 테이블에 새로운 데이터 추가 혹은 기존 데이터 갱신 / 제거 시, 자동으로 인덱스 자신도 갱신 수행
+이것 자체는 우수한 기능이지만 그 대가로 인덱스가 존재하지 않는 떄와 비교 하면 매번 인덱스 갱신도 부수적으로 발생 하기에 오버헤드 여지를 주는 것.
+
+ 의도한 것과 다른 인덱스가 사용된다
+
+한 개의 테이블에 복수의 인덱스를 설정할 경우에 파생될 수 있는 문제점.
+
+사용할 수 있는 인덱스 후보가 많으면 옵티마이저도 헤메게 될 뿐더러 인덱스 역시 백업 대상이기에 백업 시 소요시간이 요구된다.
+
+## 인덱스 생성 기준
+
+- 1. 크기가 큰 테이블만 생성
+
+- 2. 기본키 제약이나 유일성 제약이 부여된 열에는 불필요.
+
+-> 기본키에는 어차피 인덱스가 기존에 존재하며 유일성 재약이 붙어있는 열도 마찬가지
+
+이 2가지 제약이 붙어 있는 열에 암묵적으로 인덱스가 작성된 것은 값의 중복 체크를 하려면 데이터를 정렬해야 하는데 인덱스를 작성해 정렬하는 것이 편리.
+
+- 3. Cardinality가 높은 열에 생성
+
+카디널리티는 상대적인 개념으로서 가령 사람의 주민번호 경우 중복이 될 여지가 적기에( = unique한 값의 갯수가 많다.) 카디널리티가 높고, 이름의 경우 동명이인이 있을 수 있기에 주민번호에 비해 "상대적"으로 카디널리티가 낮다.
+
+커디널리티가 높은 순으로 필터링 하여 조회하기에 높은 순에서 낮은 순으로 구성하는 것이 좋다. ( = 낮은 열에 인덱스 효과를 기대할 수 없는 것은 인덱스 트리를 따라가는 조작이 증가 )
+
+- 테이블 조인을 위해 연결고리로 자주 사용되는 컬럼
+
+조인 쿼리에 사용되는 컬럼의 경우 풀스캔을 타게 되면 조인의 수가 늘어날 수록 풀스캔하는 데이터 수가 많아지므로 병목현상의 대표적인 원인이 된다.
+
+### [외않돼? 타임] 인덱스를 만들었는데 인덱스를 참조하질 않아요 (USE INDEX)
+
+특정 테이블에 index를 걸었더라도 해당 index가 작동하지 않을 수도 있다. 이유는 여러가지겠지만 Mysql이 내부적으로 가장 빠르거나 합리적인 탐색법을 사용하기 때문이다. 그럴 경우엔 Hint 기능을 써서 USE INDEX를 사용해서 인덱스를 강제로 작동시키게 할 수 있다. -> 이렇게 하는 이유는 근본적으로는 인덱스 갯수가 여러개이기 때문.
+
+```
+SELECT *
+FROM IMAGE USE INDEX(USER_ADD_ID)
+WHERE add_id = '2bf-ad7c-1b24'
+```
+
+참고 - 힌트(Hint)기능을 쓰는 이유는 옵티마이저(Optimizer)가 항상 최적의 실행 경로를 만들어 내기는 불가능하기 때문에 개발자가 최적의 경로를 지정해주는 것을 말한다. 옵티마이저 힌트와 인덱스 힌트로 나뉘며 무분별한 힌트의 사용은 성능의 저하를 초래한다
+
+ref :https://stir.tistory.com/236
+
+### 추가 - 클러스터링 인덱스 vs 논-클러스터링 인덱스 (=세컨더리 인덱스)
+
+#### 1. 클러스터링 인덱스 ( 실제 데이터와 "같은" 무리의 인덱스 )
+
+- 테이블의 "PK"에 적용되는 인덱스이다
+- PK값이 비슷한 레코드끼리 묶어 저장하는 것을 클러스터링 인덱스라고 한다.
+- PK값에 의해 해당 레코드의 물리적인 저장 위치가 결정 (PK값이 바뀌면 해당 레코드의 물리적인 저장 위치도 변경됨)
+- PK 값을 기준으로 정렬된 상태를 유지한다.
+
+ +
+- B - Tree 구조로 이루어짐
+- idx-1, idx-2 ... 는 데이터페이지의 주소값을 가리킴
+- 루트페이지와 리프페이지로 구성되며 루트페이지는 리프페이지의 주소가, 리프페이지에는 "실제 데이터" 를 담고 있다.
+ 인덱스의 정보를 담고 있는 것이 아닌 모든 컬럼에 대한 실제 데이터를 담고 있다. 따라서, 따라서리프페이지 == 데이터페이지이다.
+
+ 특징
+
+1. 실제 데이터가 정렬 따라서, 테이블 당 1개만 존재 가능
+2. 리프페이지 == 데이터페이지
+3. 다음 제약조건 시 자동생성 (PRIMARY KEY , UNIQUE + NOT NULL) , 둘 다 있으면 PRI 우선
+
+ 주의 사항
+
+1. PK는 AUTO_INCREMENT보다는 업무적인 컬럼으로 생성 (가능한 경우)
+
+- InnoDB의 PK는 클러스터링 키로 사용되며 이 값에 의해 레코드의 위치가 결정된다.
+- PK는 대부분 검색에서 빈번하게 사용되므로 PK의 크기가 조금 크더라도 업무적으로 해당 레코드를 대표할 수 있다면 그 컬럼을 PK로 선택하는 것이 좋다.
+
+2. PK는 반드시 명시할 것
+
+- 가능하면 AUTO_INCREMENT를 사용하더라도 PK를 꼭 만들자.
+- PK가 없고 NOT NULL + Unique 인덱스도 없으면 InnoDB 내부적으로 일련 번호 컬럼을 추가한다.
+- 이렇게 자동으로 생성된 컬럼은 사용자에게 보이지도 않고, 사용자가 전혀 접근할 수도 없으므로 의미가 없는 값이 된다.
+
+3. AUTO_INCREMENT 컬럼을 인조 식별자로 사용할 경우
+
+- PK의 크기가 커도 세컨더리 인덱스가 거의 필요 없다면 그대로 PK를 사용하는 것이 좋다.
+- 세컨더리 인덱스도 필요하고 PK의 크기가 크다면 AUTO_INCREMENT 컬럼을 추가하고, 이를 PK로 지정하면 된다.
+- 이렇게 업무 상의 의미를 지닌 PK를 대체하기 위해 AUTO_INCREMENT과 같은 방식을 사용하여 인위적으로 추가된 PK를 인조 식별자라고 부른다.
+
+#### 2. 논-클러스터링 인덱스 ( 실제 데이터와 "다른" 무리의 인덱스 )
+
+테이블 생성 시 UNIQUE 제약조건을 걸게되면 자동적으로 논-클러스터링 인덱스가 생성되며 개념적으로 후보키에만 부여할 수 있는 인덱스다. (후보키 : 고유 식별 번호, 주민번호와 같이 각 데이터를 인식할 수 있는 최소한의 고유 식별 속성 집합)
+
+
+
+- B - Tree 구조로 이루어짐
+- idx-1, idx-2 ... 는 데이터페이지의 주소값을 가리킴
+- 루트페이지와 리프페이지로 구성되며 루트페이지는 리프페이지의 주소가, 리프페이지에는 "실제 데이터" 를 담고 있다.
+ 인덱스의 정보를 담고 있는 것이 아닌 모든 컬럼에 대한 실제 데이터를 담고 있다. 따라서, 따라서리프페이지 == 데이터페이지이다.
+
+ 특징
+
+1. 실제 데이터가 정렬 따라서, 테이블 당 1개만 존재 가능
+2. 리프페이지 == 데이터페이지
+3. 다음 제약조건 시 자동생성 (PRIMARY KEY , UNIQUE + NOT NULL) , 둘 다 있으면 PRI 우선
+
+ 주의 사항
+
+1. PK는 AUTO_INCREMENT보다는 업무적인 컬럼으로 생성 (가능한 경우)
+
+- InnoDB의 PK는 클러스터링 키로 사용되며 이 값에 의해 레코드의 위치가 결정된다.
+- PK는 대부분 검색에서 빈번하게 사용되므로 PK의 크기가 조금 크더라도 업무적으로 해당 레코드를 대표할 수 있다면 그 컬럼을 PK로 선택하는 것이 좋다.
+
+2. PK는 반드시 명시할 것
+
+- 가능하면 AUTO_INCREMENT를 사용하더라도 PK를 꼭 만들자.
+- PK가 없고 NOT NULL + Unique 인덱스도 없으면 InnoDB 내부적으로 일련 번호 컬럼을 추가한다.
+- 이렇게 자동으로 생성된 컬럼은 사용자에게 보이지도 않고, 사용자가 전혀 접근할 수도 없으므로 의미가 없는 값이 된다.
+
+3. AUTO_INCREMENT 컬럼을 인조 식별자로 사용할 경우
+
+- PK의 크기가 커도 세컨더리 인덱스가 거의 필요 없다면 그대로 PK를 사용하는 것이 좋다.
+- 세컨더리 인덱스도 필요하고 PK의 크기가 크다면 AUTO_INCREMENT 컬럼을 추가하고, 이를 PK로 지정하면 된다.
+- 이렇게 업무 상의 의미를 지닌 PK를 대체하기 위해 AUTO_INCREMENT과 같은 방식을 사용하여 인위적으로 추가된 PK를 인조 식별자라고 부른다.
+
+#### 2. 논-클러스터링 인덱스 ( 실제 데이터와 "다른" 무리의 인덱스 )
+
+테이블 생성 시 UNIQUE 제약조건을 걸게되면 자동적으로 논-클러스터링 인덱스가 생성되며 개념적으로 후보키에만 부여할 수 있는 인덱스다. (후보키 : 고유 식별 번호, 주민번호와 같이 각 데이터를 인식할 수 있는 최소한의 고유 식별 속성 집합)
+
+ +
+- 데이터 페이지 (실제 데이터가 저장된 곳) -> 어떠한 정렬 / 변경도 이뤄지지 않음
+- 데이터 페이지 == 리프 페이지 였던 클러스터링 인덱스와는 달리 별도의 인덱스 페이지 생성 (B-tree 구조는 동일)
+- 따라서, 이처럼 추가공간이 요구되기에 세컨더리 인덱스를 남용하면 공간 낭비와 부하로 이뤄질 수 있다.
+- d-1, d-2는 데이터 위치에 대한 주소값을 가지고 있음
+ -> RID(Row Identifier) 라고 한다.
+- 클러스터형 보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 더 낫다.
+- 각 데이터에 대해서 고유 값 (unique) 들이 있는 목록에 생성 할 수 있는 인덱스다. (unique key)
+
+ 특징
+
+1. 실제 데이터 페이지는 어떠한 변경도 없이 그대로 존재
+2. 별도의 인덱스 페이지 생성 -> 추가 공간 필요
+3. 테이블 당 여러개 존재
+4. 리프페이지에 실제 데이터 페이지 "주소"를 담고 있음
+5. 직접 index 생성 시 논-클러스터링 인덱스가 생성됨
+
+#### 3. 클러스터 + 보조(세컨더리) 인덱스
+
+
+
+- 데이터 페이지 (실제 데이터가 저장된 곳) -> 어떠한 정렬 / 변경도 이뤄지지 않음
+- 데이터 페이지 == 리프 페이지 였던 클러스터링 인덱스와는 달리 별도의 인덱스 페이지 생성 (B-tree 구조는 동일)
+- 따라서, 이처럼 추가공간이 요구되기에 세컨더리 인덱스를 남용하면 공간 낭비와 부하로 이뤄질 수 있다.
+- d-1, d-2는 데이터 위치에 대한 주소값을 가지고 있음
+ -> RID(Row Identifier) 라고 한다.
+- 클러스터형 보다 검색 속도는 더 느리지만 데이터의 입력/수정/삭제는 더 낫다.
+- 각 데이터에 대해서 고유 값 (unique) 들이 있는 목록에 생성 할 수 있는 인덱스다. (unique key)
+
+ 특징
+
+1. 실제 데이터 페이지는 어떠한 변경도 없이 그대로 존재
+2. 별도의 인덱스 페이지 생성 -> 추가 공간 필요
+3. 테이블 당 여러개 존재
+4. 리프페이지에 실제 데이터 페이지 "주소"를 담고 있음
+5. 직접 index 생성 시 논-클러스터링 인덱스가 생성됨
+
+#### 3. 클러스터 + 보조(세컨더리) 인덱스
+
+ +
+클러스터 인덱스 페이지에 보조 인덱스 페이지가 따로 만들어져 연결됨을 볼 수 있다.
+가령 위에서 '임'재범을 찾게된다면 보조 인덱스 페이지에서 임재범 LJB를 따라가다가 다시 클러스터 인덱스 루트 페이지로가 LJB로 검색하며 찾아들어가게 된다.
+
+여기서 주의깊게 쳐다봐야 할 지점은 기존에 보조 인덱스의 경우에는 인덱스 페이지를 만들어 데이터페이지를 가리키는 RID를 사용했지만 클러스터 + 보조 인덱스 구조에서는 RID가 아닌 클러스터 인덱스의 "실제" 값(PK)을 가지고 찾아들어간다.
+
+이렇게 하면 주솟값으로 바로 점프를 하지 못하고 루트 페이지도 읽어야 하고 데이터페이지도 동시에 읽어야 하는데 왜 그럴까?
+
+정답은 RID로 데이터를 저장하면 삽입 삭제 시 인덱스 페이지가 완전히 뒤집어져야 하기 때문이다. 데이터를 추가하게 되면 데이터가 정렬되어야 하기 때문에 RID가 바뀔 것이고 모든 데이터에 연쇄 반응을 일으킨다. 더불어 보조 인덱스 페이지가 바뀌면 클러스터 인덱스 페이지도 바꿔줘야 한다.
+
+즉, 검색으로 얻는 이득 보다, 삽입 삭제시 잃는 성능이 더 크기 때문에 RID말고 PK를 저장하게 구성 된 것이다.
+
+#### [MySQL의 특이점]
+
+일반적인 DBMS에서 세컨더리 인덱스를 생성하면 리프 노드(Leaf node)에는 그 데이터가 있는 실제 물리 주소를 가지고 있다가 해당 인덱스가 사용되면 바로 데이터를 가져온다.
+
+하지만 MySQL에서의 세컨더리 인덱스는 "프리머리 키 값" 을 저장하게 되어 있습니다. 그래서 쿼리 실행시 세컨더리 인덱스를 사용하게 되면 해당 인덱스에 저장되어 있는 프리머리 키값을 찾아간다.
+
+즉, 세컨더리 인덱스 -> 프리머리 키 -> 찾고자 하는 데이터
+
+모든 세컨더리 인덱스가 프리머리 키를 가지고 있기 때문에 인덱스만으로 처리될 수 있는 경우가 많이 있습니다.
+
+#### 인덱스 적용 기준 (추천)
+
+1. 카디널리티가 높은 ( = 중복도가 낮은) 컬럼
+2. WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼 (WHERE 절에 사용되는 열 (WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있음)
+
+- 조건절이 없다면 인덱스가 사용되지 않기 때문.
+- ORDER BY 사용할 땐 클러스터 인덱스가 자동 정렬이 되어 있기에 유리
+
+3. INSERT / UPDATE / DELETE 가 자주 발생하지 않는 컬럼
+4. 규모가 작지 않은 테이블
+
+#### 인덱스 적용 기준 (비추천)
+
+1. 대용량 데이터가 자주 입력되는 경우
+ 클러스터형 인덱스의 경우 빈번한 페이징이 일어나기 때문에 부하가 생긴다.
+ 따라서 인덱스가 필요한 경우 primary(클러스터) 대신 unique만 설정하는 게 좋을 수 있다.
+
+2. 데이터 중복도가 높은 열은 인덱스 효과가 없다.
+ 성별 처럼 중복도가 높은 열에는 쓰나마나.
+ 따라서 일반 보조 인덱스보다 unique 보조 인덱스가 빠르다.
+
+3. 자주 사용되지 않으면 성능 저하를 초래할 수 있음. (INSERT만 주구장창 하는 시스템이라면, 사용해보지도 못하고 데이터 입력에 걸리는 작업량만 많아진다)
+
+ref : https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%EC%9D%B8%EB%8D%B1%EC%8A%A4index-%ED%95%B5%EC%8B%AC-%EC%84%A4%EA%B3%84-%EC%82%AC%EC%9A%A9-%EB%AC%B8%EB%B2%95-%F0%9F%92%AF-%EC%B4%9D%EC%A0%95%EB%A6%AC
+https://www.youtube.com/watch?v=IMDH4iAQ6zM
diff --git "a/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md" "b/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md"
new file mode 100644
index 0000000..9cc937b
--- /dev/null
+++ "b/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md"
@@ -0,0 +1,3 @@
+## SQL 레벨업 1-2장 요약
+
+- https://spiral-sturgeon-2b1.notion.site/SQL-5cb8055329e14f30b62ba86f6df82fde?pvs=4
\ No newline at end of file
diff --git "a/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md" "b/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md"
new file mode 100644
index 0000000..9488c1b
--- /dev/null
+++ "b/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md"
@@ -0,0 +1 @@
+### https://spiral-sturgeon-2b1.notion.site/SQL-5cb8055329e14f30b62ba86f6df82fde?pvs=4
\ No newline at end of file
+
+클러스터 인덱스 페이지에 보조 인덱스 페이지가 따로 만들어져 연결됨을 볼 수 있다.
+가령 위에서 '임'재범을 찾게된다면 보조 인덱스 페이지에서 임재범 LJB를 따라가다가 다시 클러스터 인덱스 루트 페이지로가 LJB로 검색하며 찾아들어가게 된다.
+
+여기서 주의깊게 쳐다봐야 할 지점은 기존에 보조 인덱스의 경우에는 인덱스 페이지를 만들어 데이터페이지를 가리키는 RID를 사용했지만 클러스터 + 보조 인덱스 구조에서는 RID가 아닌 클러스터 인덱스의 "실제" 값(PK)을 가지고 찾아들어간다.
+
+이렇게 하면 주솟값으로 바로 점프를 하지 못하고 루트 페이지도 읽어야 하고 데이터페이지도 동시에 읽어야 하는데 왜 그럴까?
+
+정답은 RID로 데이터를 저장하면 삽입 삭제 시 인덱스 페이지가 완전히 뒤집어져야 하기 때문이다. 데이터를 추가하게 되면 데이터가 정렬되어야 하기 때문에 RID가 바뀔 것이고 모든 데이터에 연쇄 반응을 일으킨다. 더불어 보조 인덱스 페이지가 바뀌면 클러스터 인덱스 페이지도 바꿔줘야 한다.
+
+즉, 검색으로 얻는 이득 보다, 삽입 삭제시 잃는 성능이 더 크기 때문에 RID말고 PK를 저장하게 구성 된 것이다.
+
+#### [MySQL의 특이점]
+
+일반적인 DBMS에서 세컨더리 인덱스를 생성하면 리프 노드(Leaf node)에는 그 데이터가 있는 실제 물리 주소를 가지고 있다가 해당 인덱스가 사용되면 바로 데이터를 가져온다.
+
+하지만 MySQL에서의 세컨더리 인덱스는 "프리머리 키 값" 을 저장하게 되어 있습니다. 그래서 쿼리 실행시 세컨더리 인덱스를 사용하게 되면 해당 인덱스에 저장되어 있는 프리머리 키값을 찾아간다.
+
+즉, 세컨더리 인덱스 -> 프리머리 키 -> 찾고자 하는 데이터
+
+모든 세컨더리 인덱스가 프리머리 키를 가지고 있기 때문에 인덱스만으로 처리될 수 있는 경우가 많이 있습니다.
+
+#### 인덱스 적용 기준 (추천)
+
+1. 카디널리티가 높은 ( = 중복도가 낮은) 컬럼
+2. WHERE, JOIN, ORDER BY 절에 자주 사용되는 컬럼 (WHERE 절에 사용되는 열 (WHERE 절에 사용되는 열이라도 자주 사용해야 가치가 있음)
+
+- 조건절이 없다면 인덱스가 사용되지 않기 때문.
+- ORDER BY 사용할 땐 클러스터 인덱스가 자동 정렬이 되어 있기에 유리
+
+3. INSERT / UPDATE / DELETE 가 자주 발생하지 않는 컬럼
+4. 규모가 작지 않은 테이블
+
+#### 인덱스 적용 기준 (비추천)
+
+1. 대용량 데이터가 자주 입력되는 경우
+ 클러스터형 인덱스의 경우 빈번한 페이징이 일어나기 때문에 부하가 생긴다.
+ 따라서 인덱스가 필요한 경우 primary(클러스터) 대신 unique만 설정하는 게 좋을 수 있다.
+
+2. 데이터 중복도가 높은 열은 인덱스 효과가 없다.
+ 성별 처럼 중복도가 높은 열에는 쓰나마나.
+ 따라서 일반 보조 인덱스보다 unique 보조 인덱스가 빠르다.
+
+3. 자주 사용되지 않으면 성능 저하를 초래할 수 있음. (INSERT만 주구장창 하는 시스템이라면, 사용해보지도 못하고 데이터 입력에 걸리는 작업량만 많아진다)
+
+ref : https://inpa.tistory.com/entry/MYSQL-%F0%9F%93%9A-%EC%9D%B8%EB%8D%B1%EC%8A%A4index-%ED%95%B5%EC%8B%AC-%EC%84%A4%EA%B3%84-%EC%82%AC%EC%9A%A9-%EB%AC%B8%EB%B2%95-%F0%9F%92%AF-%EC%B4%9D%EC%A0%95%EB%A6%AC
+https://www.youtube.com/watch?v=IMDH4iAQ6zM
diff --git "a/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md" "b/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md"
new file mode 100644
index 0000000..9cc937b
--- /dev/null
+++ "b/Document/2023/1105/jincheol/SQL\353\240\210\353\262\250\354\227\205_1-2\354\236\245.md"
@@ -0,0 +1,3 @@
+## SQL 레벨업 1-2장 요약
+
+- https://spiral-sturgeon-2b1.notion.site/SQL-5cb8055329e14f30b62ba86f6df82fde?pvs=4
\ No newline at end of file
diff --git "a/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md" "b/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md"
new file mode 100644
index 0000000..9488c1b
--- /dev/null
+++ "b/Document/2023/1126/jincheol/SQL\353\240\210\353\262\250\354\227\205_5-6\354\236\245.md"
@@ -0,0 +1 @@
+### https://spiral-sturgeon-2b1.notion.site/SQL-5cb8055329e14f30b62ba86f6df82fde?pvs=4
\ No newline at end of file