先用一張圖來表示在編碼流程中,會產生出的各種數據
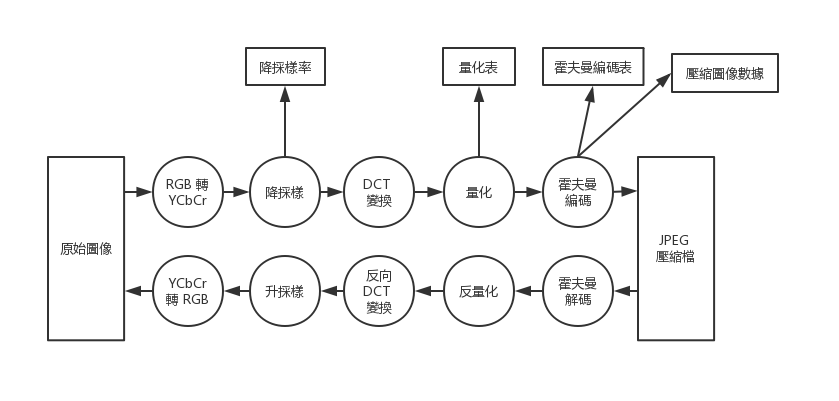
- 降採樣率:在降採樣時,可以選擇降採樣的程度
- 量化表:量化時,可以選擇量化程度
- 霍夫曼編碼表:根據圖像不同,霍夫曼編碼也不相同
- 壓縮圖像數據:壓縮後的像素數據,當然也必須記錄
我們在上一篇提到過,JPEG 支援多種算法,所以也必須記錄究竟選擇的是哪一種。
綜上所述,我們可以推估 JPEG 壓縮檔可能是由以下幾個區段組成的:
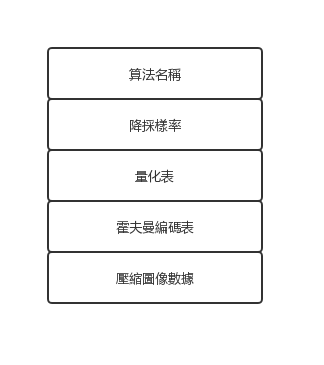
這跟現實很接近了,但仍有幾點不同
- JPEG 檔在開始跟結尾處,分別會有「檔案開始」跟「檔案結束」的標記
- 遵循 JFIF 規範的檔案,會多出一個區段 APP0,記錄 JFIF 的額外資訊
- 「採用何種算法」跟降採樣率放在同一個區段
- 壓縮圖像數據會前綴一個 SOS 區段,告知解碼器接下來該如何讀取
改良過後,再畫一次圖
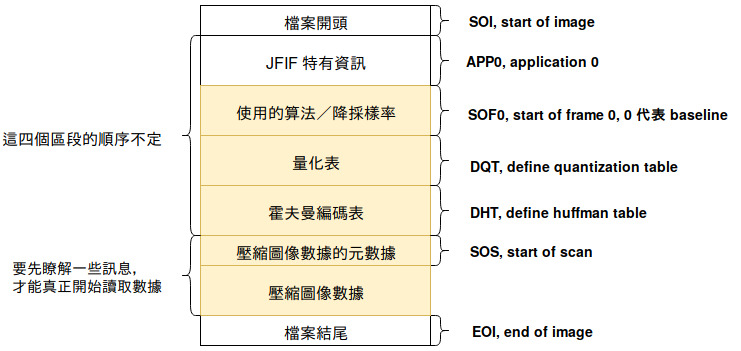
這次的新圖片終於將 baseline 會使用到的區段都列出來了。我在右側附註了各個區段的英文名稱,並且用鵝黃色標記出了含有解碼所需數據的區段。
很多網路資料都會特別解釋 APP0 ,但事實上解碼時並不需要這個區段的資訊。
我在 SOF0 區段標記了它的內容包含算法名稱,其實這並不太精確,一個 JPEG 圖檔中,一定會出現一個 SOF0, SOF1, SOF2, ... SOF16 其中一個區段,如果出現的是 SOF0 ,那就代表我們使用的是 baseline 。
另一件值得注意的事情是 DQT 跟 DHT 都可能不止一個。
所有的區段都會以 0xFF 開頭,緊接着的一個 byte 表示了它是哪一種區段。我們現在將這兩個 bytes 稱之爲標記碼,下表列出了本文中會解析的區段標記碼。
| 區段名稱 | 標記碼 | 有無數據 |
|---|---|---|
| SOI | 0xFFD8 | ❌ |
| EOI | 0xFFD9 | ❌ |
| DQT | 0xFFDB | ✅ |
| DHT | 0xFFC4 | ✅ |
| SOF0 | 0xFFC0 | ✅ |
| SOS | 0xFFDA | ✅ |
這些區段可以再加以細分爲
- 無數據區段:長度只有 2 bytes
- 有數據區段:在標記碼之後,會緊跟着 2 bytes ,表示整個區段扣除那 2 bytes 標記碼之後的長度。
剛好這裏第一次出現了 2 bytes 的數據,特別提醒,JPEG 以 big-endian 來儲存所有長度大於 1 byte 的數字,強烈建議您在寫程式的時候,實作一個讀取 2 bytes 的函式,很常用到,範例如下:
fn read_u16(reader: &mut BufReader<File>) -> u16 {
let mut c: [u8; 2] = [0; 2];
reader.read_exact(&mut c);
return (c[0] as u16) * 256 + (c[1] as u16);
}看完了標記碼的共通結構,您也許會覺得好奇,那在壓縮圖像數據中,難道不會也有 0xFF 嗎?
會的,但爲了避免解析標頭的麻煩,JPEG 規定在壓縮圖像數據中,任何 0xFF 的數據,都必須緊接著一個 0x00 的 byte ,因此如果只想解析標頭,直接跳過 0xFF00 即可。
配套程式碼的 marker.rs 解析了標記碼以及區段的長度,用以下指令
jpeg_tutorial XXX.jpg marker
可以執行該檔案的 marker_detector 函式,打印出 baseline 流程會使用到的檔頭。