A live, syntax-aware vector index over your repo — in ~100 lines of plain async Python.
Point it at a directory, search it in natural language, and it re-embeds only what changes as you edit.
Star us ❤️ →






You declare the transformation in native Python and your own types — target_state = transformation(source_state). The heavy lifting (incremental processing, change tracking, managed targets) runs in a Rust engine underneath, so a one-line edit re-embeds one chunk, not the repo.
query: "where do we embed chunks?"
[0.582] examples/code_embedding/main.py (L66-L83)
@coco.fn
async def process_chunk(chunk, filename, id_gen, table):
embedding = await coco.use_context(EMBEDDER).embed(chunk.text)
...Walk a repo → detect language → split along the syntax tree with Tree-sitter → embed each chunk → upsert into Postgres (pgvector). With live=True, the source keeps watching and the index stays fresh as you code.
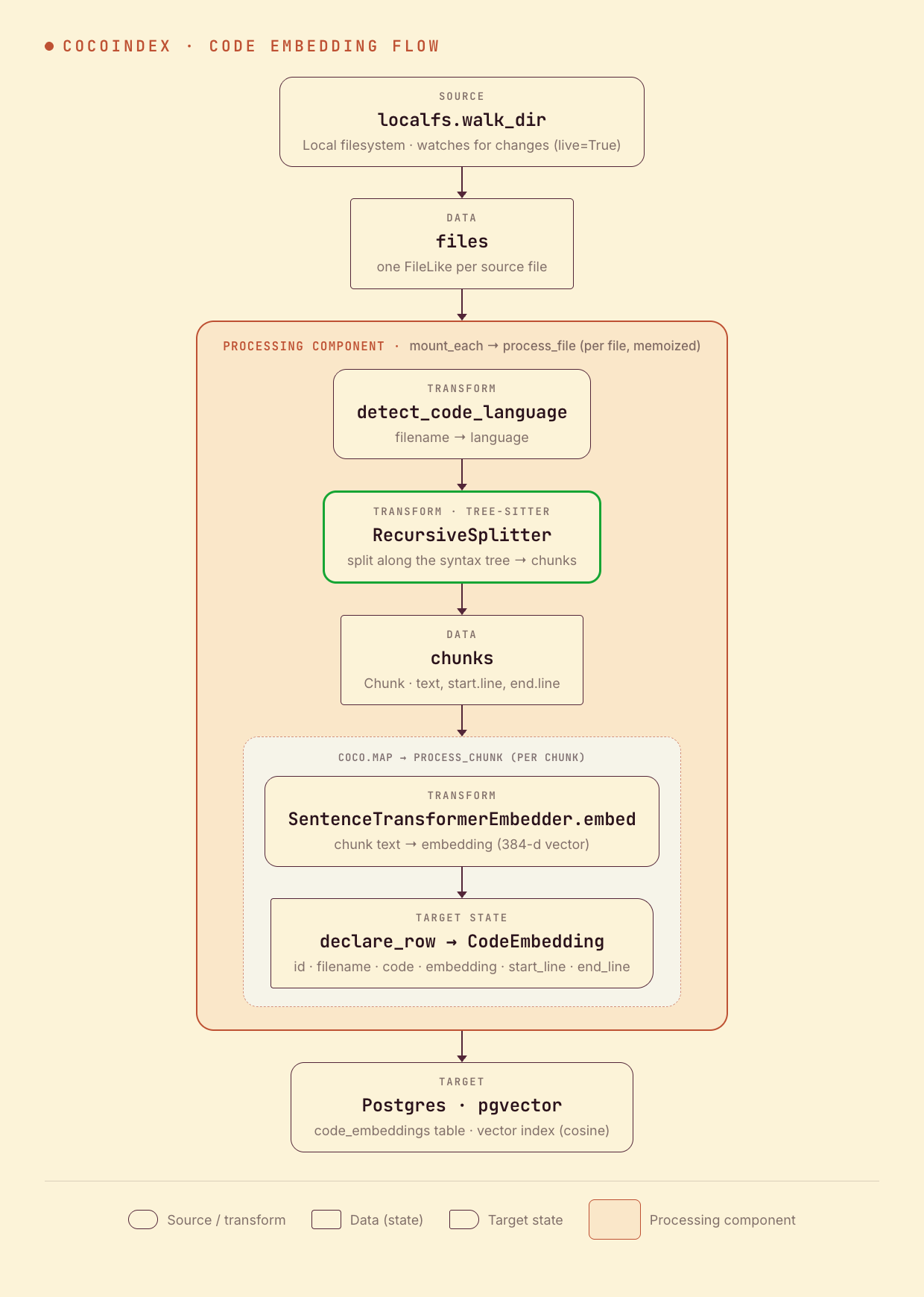
The whole indexing path is the snippet below — read it top-to-bottom in main.py:
@coco.fn(memo=True)
async def process_file(file: FileLike, table: postgres.TableTarget[CodeEmbedding]) -> None:
text = await file.read_text()
language = detect_code_language(filename=str(file.file_path.path.name))
chunks = _splitter.split(text, chunk_size=1000, min_chunk_size=300,
chunk_overlap=300, language=language) # Tree-sitter, syntax-aware
id_gen = IdGenerator()
await coco.map(process_chunk, chunks, file.file_path.path, id_gen, table)
@coco.fn
async def process_chunk(chunk, filename, id_gen, table) -> None:
embedding = await coco.use_context(EMBEDDER).embed(chunk.text)
table.declare_row(row=CodeEmbedding(
id=await id_gen.next_id(chunk.text), filename=str(filename), code=chunk.text,
embedding=embedding, start_line=chunk.start.line, end_line=chunk.end.line,
))
@coco.fn
async def app_main(sourcedir: pathlib.Path) -> None:
table = await postgres.mount_table_target(PG_DB, table_name=TABLE_NAME, ...)
table.declare_vector_index(column="embedding")
files = localfs.walk_dir(sourcedir, recursive=True,
path_matcher=PatternFilePathMatcher(included_patterns=["**/*.py", ...]),
live=True)
await coco.mount_each(process_file, files.items(), table)
📘 Full Tutorial →
Step-by-step walkthrough with the data model, the lifespan, chunking, embedding, the App, and exactly what happens on each kind of change.
- Syntax-aware chunking, built in. Tree-sitter splits along real code structure — functions, classes, blocks — so retrieval returns whole units, not fragments cut mid-statement. Every major language; unknown types fall back to plain text.
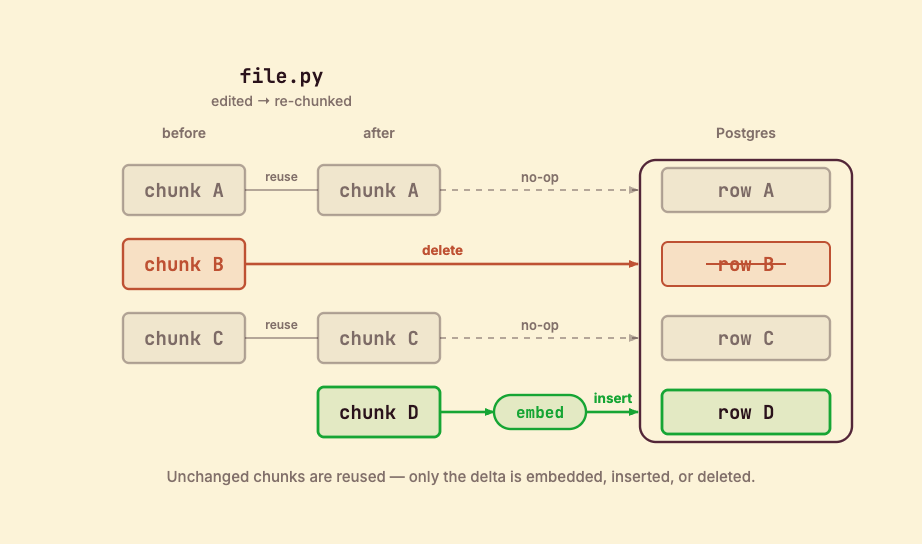
- Incremental by default.
@coco.fn(memo=True)skips unchanged files and reuses embeddings for unchanged chunks;mount_table_targetupserts only the rows that moved and deletes orphans. Edit one function → one chunk is re-embedded. - Live updates.
live=True+cocoindex update -Lkeeps watching the filesystem and applies changes with low latency — always-fresh context for an agent. - Plain Python, your stack. Swap the embedding model (12k+ on Hugging Face), the chunking, or the vector store. No DSL.
- Consistent index & query. The same embedder is shared by the indexing and query paths, so what you index is what you search.
1. Postgres + pgvector. If you don't have one, start a local instance with the compose file in this repo:
docker compose -f ../../dev/postgres.yaml up -d
export POSTGRES_URL="postgres://cocoindex:cocoindex@localhost/cocoindex"2. Install deps:
pip install -e .3. Build / update the index (writes rows into Postgres) — pick one:
cocoindex update main # catch-up: scan, sync changes, exit
cocoindex update -L main # live: catch up, then keep watching for edits4. Query it — semantic search from the terminal:
python main.py "embedding"
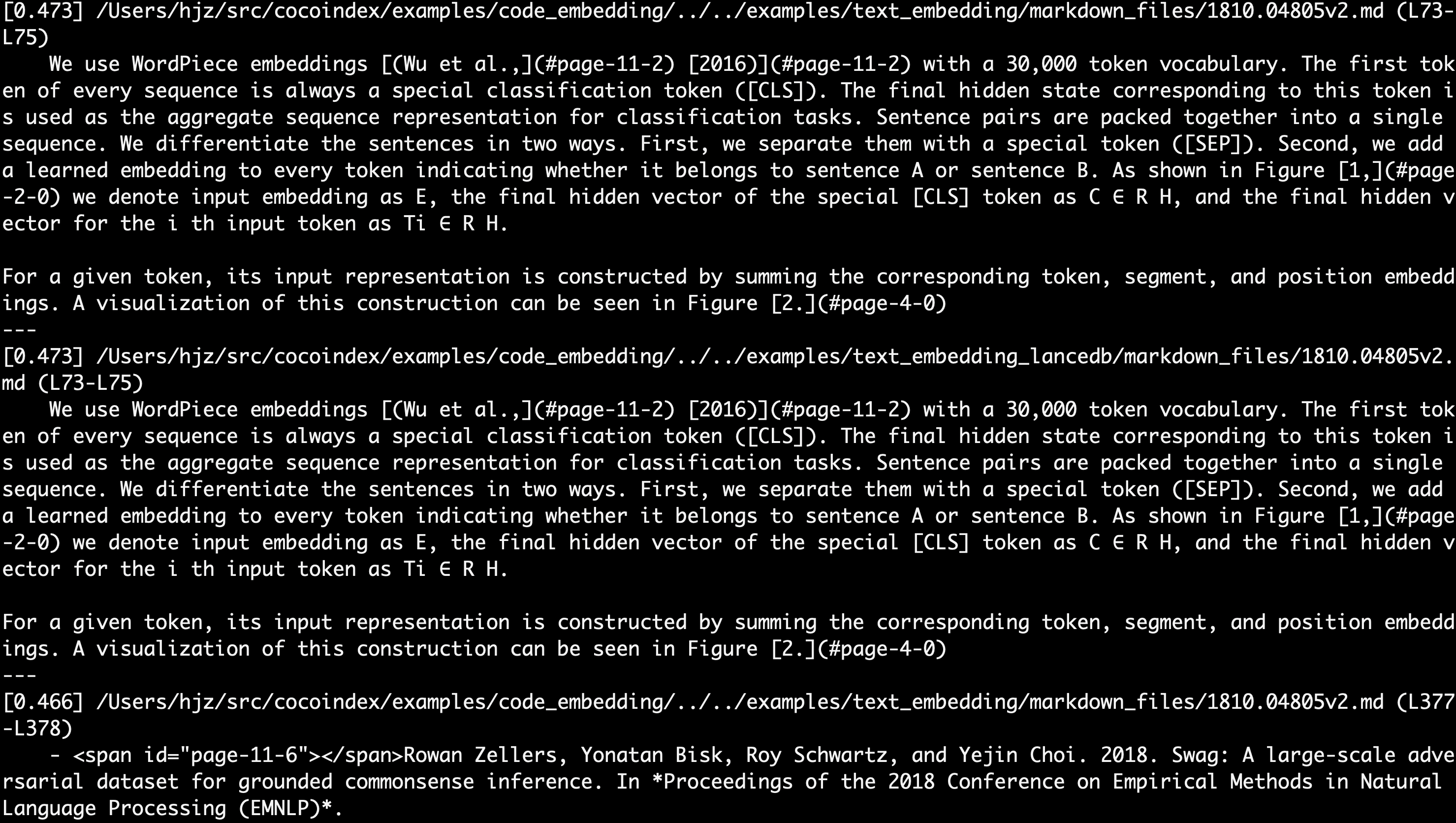
Each result carries start_line/end_line, so hits point straight at the lines that matched. Query uses pgvector's <=> cosine distance, turned into a similarity score.
CocoIndex Code is this exact pipeline — AST-aware chunking, incremental re-index, local embeddings — hardened and packaged as a CLI and an MCP server you can plug straight into a coding or code-review agent.
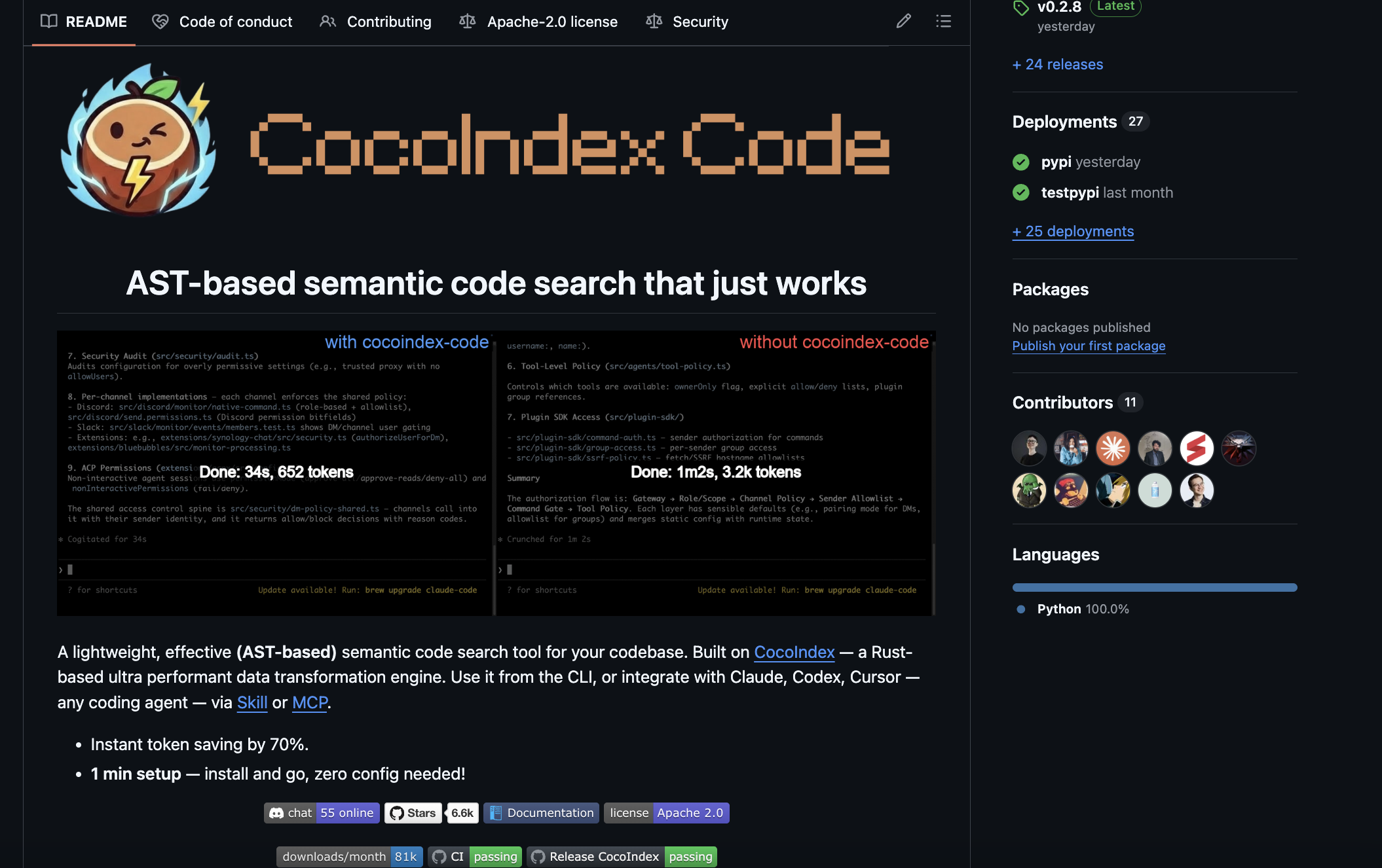
npx skills add cocoindex-io/cocoindex-code # Claude Code skill, then /ccc
claude mcp add cocoindex-code -- ccc mcp # MCP: Codex, OpenCode, Cursor, any client
ccc index && ccc search "where we embed chunks" # CLI
If this made your agents smarter, give CocoIndex a star ⭐ — it helps a lot.
Docs · Walkthrough · Discord · See all examples →