
YouTube episodes → a queryable graph of who said what about which technologies — in plain async Python.
Transcribe with speaker diarization, extract statements & entities with an LLM, resolve duplicates with embeddings, and sync it all into SurrealDB.
Star us ❤️ →






You declare the graph in native Python and your own types — target_state = transformation(source_state). The heavy lifting (incremental processing, change tracking, managed graph targets) runs in a Rust engine underneath, so adding one episode processes one episode, not the whole corpus.
Read YouTube URLs → fetch & transcribe (yt-dlp + AssemblyAI diarization) → extract speakers, statements, and mentioned entities with an LLM → resolve duplicate people/techs/orgs with embeddings + LLM → declare nodes and relationships into SurrealDB.

The whole graph is declared as target states — read it in conv_knowledge/app.py:
# Phase 1 — one memoized component per episode: transcribe, extract, declare nodes + edges
@coco.fn(memo=True)
async def process_session(youtube_id, session_table, statement_table, session_statement_rel):
transcript = await fetch_transcript(youtube_id) # yt-dlp + AssemblyAI diarization
metadata = await extract_metadata(step1_text, transcript) # LLM → who is speaking
stmts = await extract_statements(step2_text) # LLM → claims + mentioned entities
session_table.declare_record(row=Session(id=session_id, ...)) # graph node
for stmt in stmts.statements:
statement_table.declare_record(row=Statement(id=..., statement=stmt.statement))
session_statement_rel.declare_relation(from_id=session_id, to_id=stmt_id) # edge
# Phase 2 — collapse "GPT-4" / "gpt4" / "ChatGPT-4" into one canonical node
entity_dedup = await resolve_entities(
entities=raw_names, embedder=coco.use_context(EMBEDDER),
resolve_pair=LlmPairResolver(model=coco.use_context(RESOLUTION_LLM_MODEL)),
)
# Polymorphic edge: a statement can mention a person, a tech, or an org
statement_mentions_rel = await surrealdb.mount_relation_target(
SURREAL_DB, "statement_mentions", statement_table,
[entity_tables[c.name] for c in ENTITY_TYPES],
)
📘 Full Tutorial →
Step-by-step walkthrough: the two-step LLM extraction, the data models, entity resolution, the graph schema, and exactly what happens on each kind of change.
- Structured LLM extraction. OpenAI (via LiteLLM) + Pydantic models pull speakers, thematic statements, and mentioned entities as typed data — not freeform text you have to re-parse.
- Entity resolution, built in.
resolve_entitiescollapses near-duplicate people, techs, and orgs using embedding similarity + LLM confirmation, so the graph has one canonical node per real-world thing. - Incremental, per episode.
@coco.fn(memo=True)with one component per YouTube ID means adding an episode processes only that episode; unchanged sessions are skipped. - A real graph, declaratively. Nodes and polymorphic relationships are declared as target states; CocoIndex syncs them into SurrealDB and cleans up what's gone — no migration scripts.
- Plain async Python, swappable parts. Transcriber, LLM, embedder, and graph store are all yours to change.
1. Start SurrealDB (Docker):
docker run -d --name surrealdb --user root -p 8787:8000 \
-v surrealdb-data:/data surrealdb/surrealdb:latest \
start --user root --pass root surrealkv:/data/database2. Set keys — transcription + extraction:
export ASSEMBLYAI_API_KEY="..." # speaker-diarized transcription
export OPENAI_API_KEY="sk-..." # LLM extraction via LiteLLM
# Optional (shown with defaults)
export SURREALDB_URL="ws://localhost:8787/rpc"
export SURREALDB_NS="cocoindex"
export SURREALDB_DB="yt_conversations"
export SURREALDB_USER="root"
export SURREALDB_PASS="root"
export INPUT_DIR="./input"
export LLM_MODEL="openai/gpt-5.4"
export RESOLUTION_LLM_MODEL="openai/gpt-5-mini"3. Install deps:
pip install -e .4. Add YouTube URLs — one per line in input/sample.txt (# for comments):
https://www.youtube.com/watch?v=VIDEO_ID_1
https://www.youtube.com/watch?v=VIDEO_ID_2
5. Build the graph (incremental — re-running skips unchanged sessions):
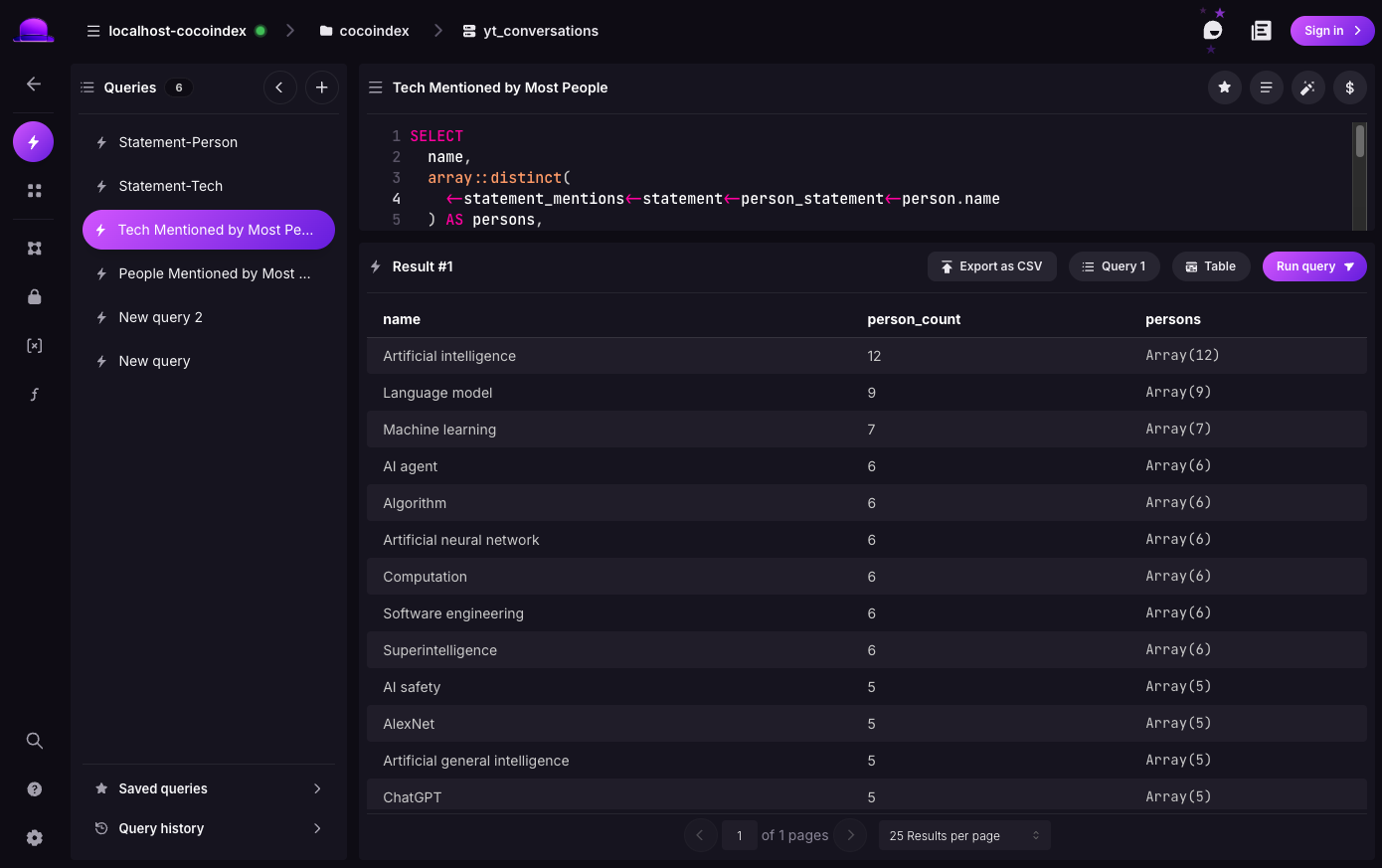
cocoindex update conv_knowledge.appSurrealDB ships Surrealist, a built-in UI for browsing and querying. For example — which technologies are mentioned by the most distinct people?
SELECT name,
array::len(array::distinct(
<-statement_mentions<-statement<-person_statement<-person.id
)) AS person_count
FROM tech ORDER BY person_count DESC LIMIT 10;
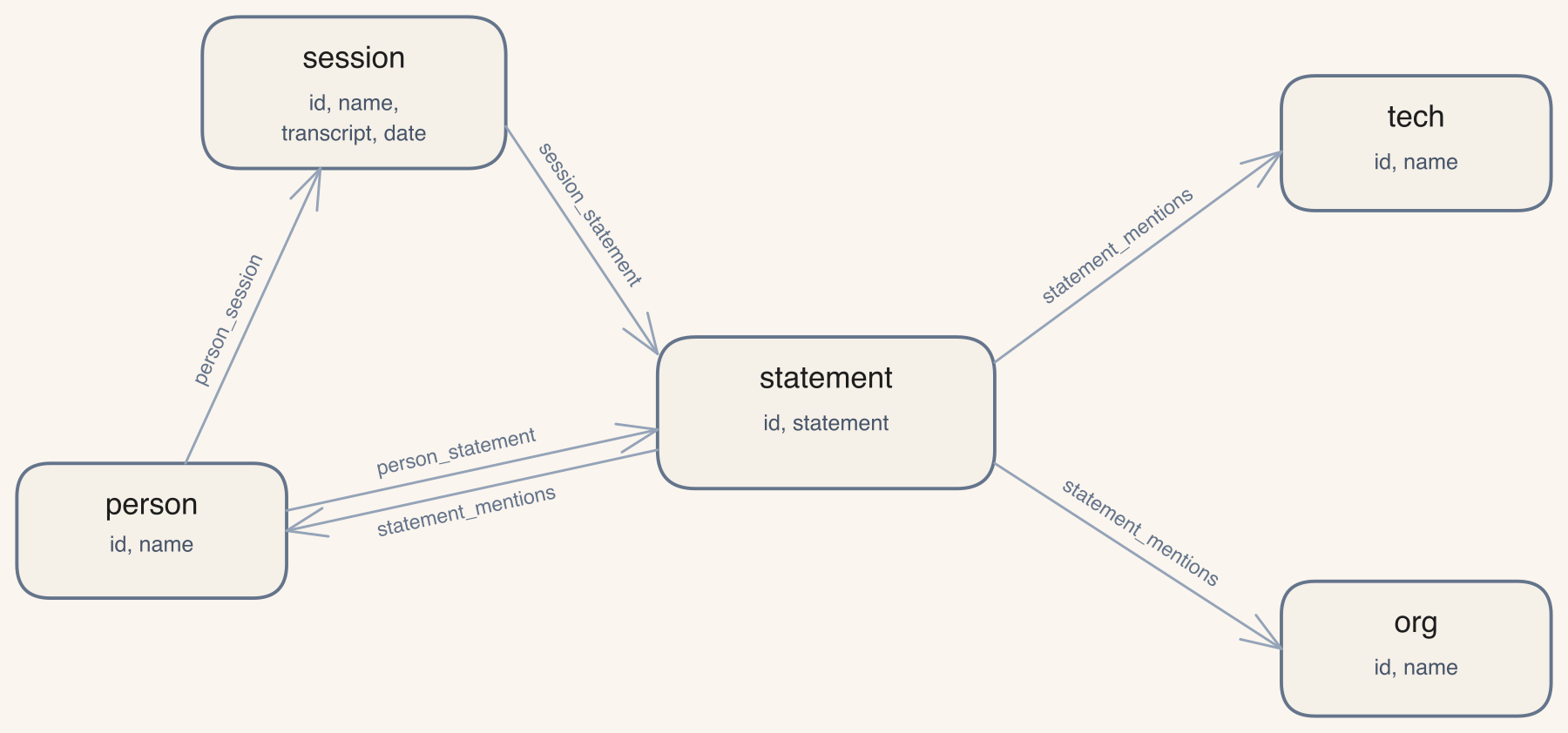
The graph is small and expressive — session, statement, person, tech, org nodes, joined by session_statement, person_session, person_statement, and the polymorphic statement_mentions:
Building graphs from other sources? See meeting notes → Neo4j and → FalkorDB, or browse all examples.
If this turned hours of podcasts into something you can actually query, give CocoIndex a star ⭐ — it helps a lot.
Docs · Tutorial · Discord · See all examples →