在深度学习概念没有火起来之前,GPU在普通人眼中是游戏显卡,即图形处理器。下面用一个例子来说明GPU和CPU的区别。
当我们打开游戏里面的3D模型,可以发现3D模型都是由一个一个小三角形构成,三角形由三根线构成,为了节省存储的空间,我们只存储三角形的三个顶点坐标,构成线的像素点坐标我们不储存,而是实时计算出来。
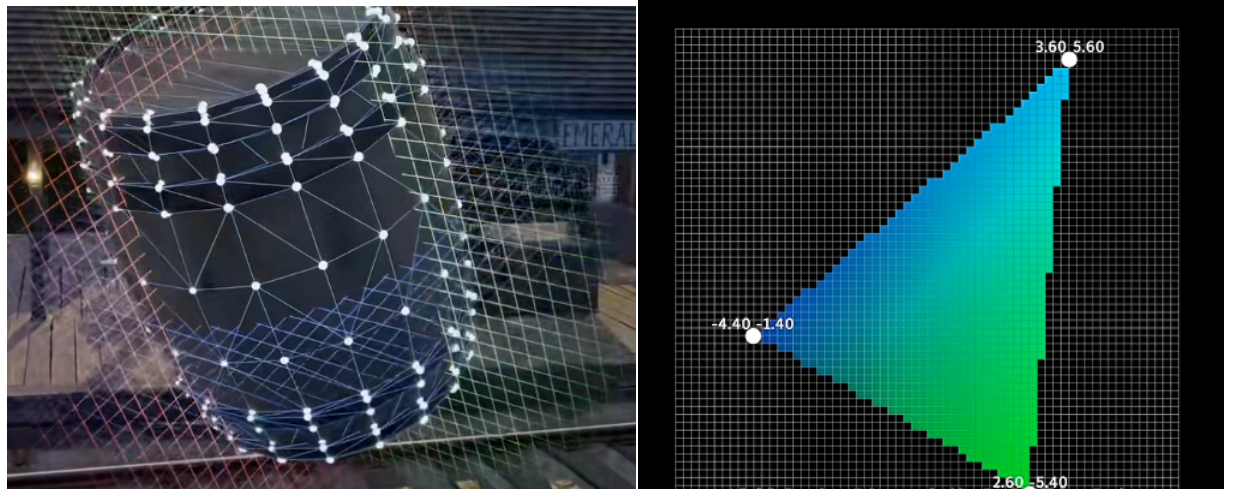
由两个点构成一个直线就可以发现,一根线我们只存储两个端点的信息,中间的像素点再时时计算渲染。我们可以由两个顶点坐标计算斜率和截距,就可以算出两条线中间的点的位置。虽然都是简单计算,只有大量简单的乘法和加法。但是 CPU 天生时执行复杂逻辑的,只能逐个计算,所以计算时间非常长。
人们就想到创造出可以大量并行计算简单的乘法和加法的计算单元,就是GPU。CPU和GPU没有优劣之分,只是用来执行不同功能的单元。GPU的计算单元被称作CUDA核心。
CPU是我们最早接触的执行模型。程序按顺序运行,在单线程中逐步执行指令。要支持这种执行模式需要大型控制单元和快速运行能力,因为存在大量分支和条件控制逻辑。因此CPU会将大量芯片面积用于分支预测(下面这张图),虽然核心数量有限但运行速度极快。相比之下,GPU则拥有海量计算单元(ALU),就是那些绿色小方块。只有极小部分芯片面积用于控制逻辑,用少量控制逻辑来协调海量并行运算的计算单元。从概念上看,这体现了CPU和GPU的不同侧重点。
二者的设计目标截然不同,CPU优化延迟,追求单个任务最快完成。而GPU优化吞吐量,GPU不关心单个任务延迟,只追求所有任务整体最快完成。为此GPU配备大量可快速休眠唤醒的线程,虽然GPU每个任务的延迟较高,但整体完成时间反而领先CPU。这就是它们不同的设计理念和目标。因此,GPU的架构结构不同在于在于GPU会运行大量流式多处理器(SM)。
CPU设计初衷是用来最小化单任务延迟,快速响应复杂逻辑,大部分晶体管用于控制逻辑和缓存,核心数量通常有4-64,可以执行乱序执行、分支预测、推测执行等等任务。
GPU的设计初衷是最大化数据吞吐量,批量处理简单计算,大部分晶体管用于算术逻辑单元(ALU),核心多而简,可以达到数万个。优化延迟,追求单个任务最快完成。配备大型控制单元、分支预测器,核心数量少(4-32个)但时钟频率极高。
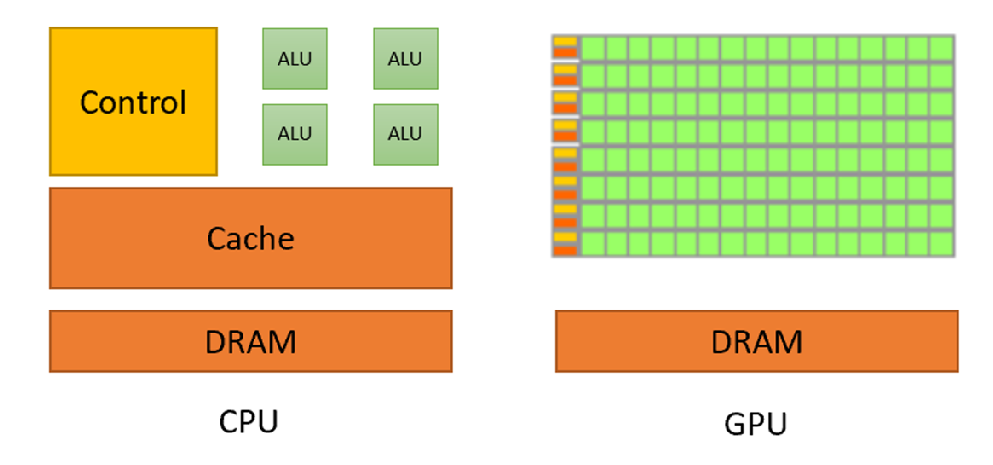
上面这幅图可以看到:CPU的计算单元(绿色部分)少,大部分用来控制(Control)和缓存(Cache)这决定了它可以进行复杂的逻辑运算,GPU则不同,他的控制单元少(黄色部分),大部分都是绿色的计算单元,这决定了它可以进行大量并行计算简单的乘法和加法运算,复杂的逻辑和复杂的计算就不行了。GPU主要就是优化吞吐量,追求所有任务整体最快完成。控制逻辑仅占芯片面积的极小部分,计算单元(ALU)占绝大多数。所以我们在使用GPU时还要CPU的调度,一个好的GPU要配上好的CPU才能发挥作用。
到了AI时代,深度学习中的矩阵将GPU推上神坛。因为AI时代的核心是神经网络的计算,其中涉及到大量的矩阵运算,矩阵运算的本质是大量的乘法和加法,特别适合GPU来做这种简单又重复的运算,在2010年左右人们就开始利用GPU来进行AI相关的计算。
没有GPU的时代,电脑显示图形全靠CPU计算,1981年:IBM PC配备的CGA显示卡只能显示16色,像个"电子相框",所有计算都由CPU完成,1987年:IBM推出VGA标准,能显示256色,但依然是纯"显示"功能,没有计算能力。
关键突破在于1985年ATi公司成立,开始用ASIC技术做图形芯片。1992年ATi的Mach32图形卡首次集成图形加速功能,这是GPU的"胚胎"。
90年代是"图形加速器"的黄金时代,但还没有"GPU"这个正式名称。
里程碑事件:1994年,3DLabs发布Glint300SX,第一颗PC用3D加速芯片诞生;1996年,3dfx的Voodoo芯片让普通PC能跑3D游戏,开启消费级3D时代;1997年富士通发布个人电脑首款3D几何处理器,三菱推出支持变换和光照(T&L) 的芯片。
但是各家标准混乱,互不兼容;只能处理特定3D任务,功能很"专一";当时叫"3D加速卡",还没GPU概念。
1999年,NVIDIA发布GeForce 256,首次提出"GPU"(图形处理器)概念。这个名字区分了传统CPU,宣告:显卡有了自己的大脑。
GeForce 256具有革命性,硬件T&L技术上,将把3D图形的坐标变换、光照计算从CPU解放出来,变成了GPU专职。实现了单芯片集成,整合三角形构成、裁剪、纹理、渲染功能,并且是实现性能飞跃:让CPU的3D计算负担减轻80%以上。
在2000年市场大洗牌,2000年后,3dfx、Matrox等老厂商逐渐退出,只剩NVIDIA GeForce和ATI Radeon双雄争霸(ATI 2006年被AMD收购)。
第一阶段:固定管线 Shader(2001-2006)
2001年,微软DirectX 8引入顶点着色器和像素着色器,GPU可以跑简单程序了。以前GPU是固定流水线上的"拧螺丝工人",现在变成了能执行简单指令的"小机器人"。
第二阶段:统一渲染架构(2006-2012)
2006年,NVIDIA发布GeForce 8800 GTX(G80核心),首个统一渲染架构GPU。原来顶点着色器和像素着色器是分开的"专科医生",现在变成了通用的"全科医生"。计算资源可以动态分配,利用率从50%提升到90%+;同时发布CUDA技术,让GPU能跑C语言程序。
| 架构 年份 | 核心突破 | 代表产品 |
|---|---|---|
| Tesla (2006) | 引入CUDA,开启GPGPU | GTX 280 |
| Fermi (2010) | 支持双精度计算、ECC纠错 | GTX 480 |
| Kepler (2012) | 动态并行、高能效 | GTX 680 |
2012年是转折点:AI研究人员用GPU训练深度神经网络,让AlexNet图像识别准确率震惊世界。从此GPU从"游戏显卡"升级为"AI发动机"。
英伟达构建了NVIDIA CUDA生态,让程序员轻松调用GPU算力

一张英伟达的的显卡剖面图如图,一张显卡由供电、显卡核心、显存、显示接口和金手指组成。
我们主要介绍显卡核心:显卡核心由cuda core、控制单元和缓存单元等构成。而 CPU 和 GPU 最大的不同就在于,GPU 负责的工作大多是重复性的 3D 建模或者渲染,而流处理器就是负责顶点运算或者像素运算,能动态的分配进行顶点运算和像素运算的流处理器数量,达到资源的高效利用。
A100是NVIDIA为数据中心设计的纯计算GPU,没有图形输出能力。
PCIe版本(常见形态) 尺寸为双槽全高,长267mm。功耗:250W(40GB版)/300W(80GB版)。散热是被动散热,无风扇(依赖服务器风道)。接口为PCIe 4.0 x16金手指 + NVLink桥接器接口;重量约1.4公斤。
GA100 GPU核心芯片
封装:巨型BGA封装,尺寸约55mm×55mm。位置:板卡正中央,焊在PCB上。542亿个晶体管,7nm工艺,面积826mm²。
HBM2e显存堆栈(革命性设计) 不同于消费级GPU的GDDR显存颗粒,A100采用3D堆叠技术:
┌─────────────────────────┐
│ HBM2e显存堆栈 (8层) │ ← 像个"芯片大楼"
│ ┌─────┐┌─────┐┌─────┐ │
│ │DRAM ││DRAM ││DRAM │ │ ← 每层8Gb容量
│ └─────┘└─────┘└─────┘ │
│ 硅通孔(TSV)垂直互联 │
│ GPU SoC │
└─────────────────────────┘
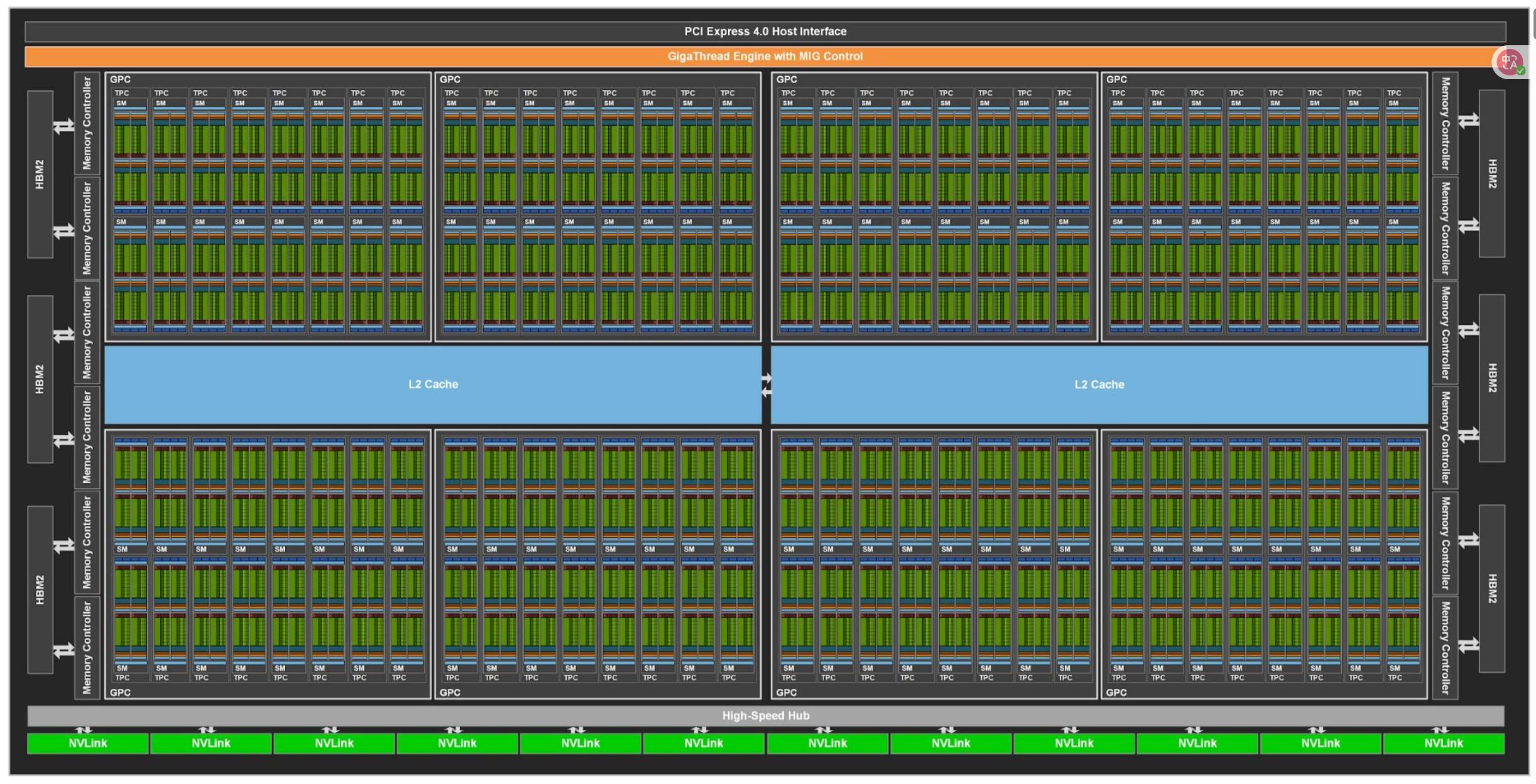
Ampere架构拓扑如下:
┌─────────────────────────────────────────┐
│ GA100 GPU核心
│
│ ┌─────────┐ ┌─────────┐ ┌─────────┐│
│ │ GPC 0 │ │ GPC 1 │ │ GPC 2 ││
│ │ (12 TPC)│ │ (12 TPC)│ │ (12 TPC)││
│ └─────────┘ └─────────┘ └─────────┘│
│
│ ┌─────────┐ ┌─────────┐ ┌─────────┐│
│ │ GPC 3 │ │ GPC 4 │ │ GPC 5 ││
│ │ (12 TPC)│ │ (12 TPC)│ │ (12 TPC)││
│ └─────────┘ └─────────┘ └─────────┘│
│
│ ┌─────────┐ ┌─────────┐ ┌─────────┐│
│ │ GPC 6 │ │ GPC 7 │ │ GPC 8 ││
│ │ (12 TPC)│ │ (12 TPC)│ │ (12 TPC)││
│ └─────────┘ └─────────┘ └─────────┘│
│
│ HBM2e控制器 ×8 ┌─────────────────┐
└──────────────────│ PCIe 4.0 ×16 │──┘
└─────────────────┘
A100有四个层级的架构拓扑,首先是GPC(图形处理簇),一个显卡核心有8个(实际启用7-8个)GPC;每GPC12个TPC(纹理处理簇),共96个TPC;每TPC 2个,共192个SM(实际启用108个)SM(流式多处理器);每个SM有64个CUDA核心,一共有192 × 64 = 6,912个CUDA核心。
然后是Tensor Core,每个SM有192个(实际启用432个第三代Tensor Core)。
A100的SM是Ampere架构核心,相比消费级GPU有本质增强:
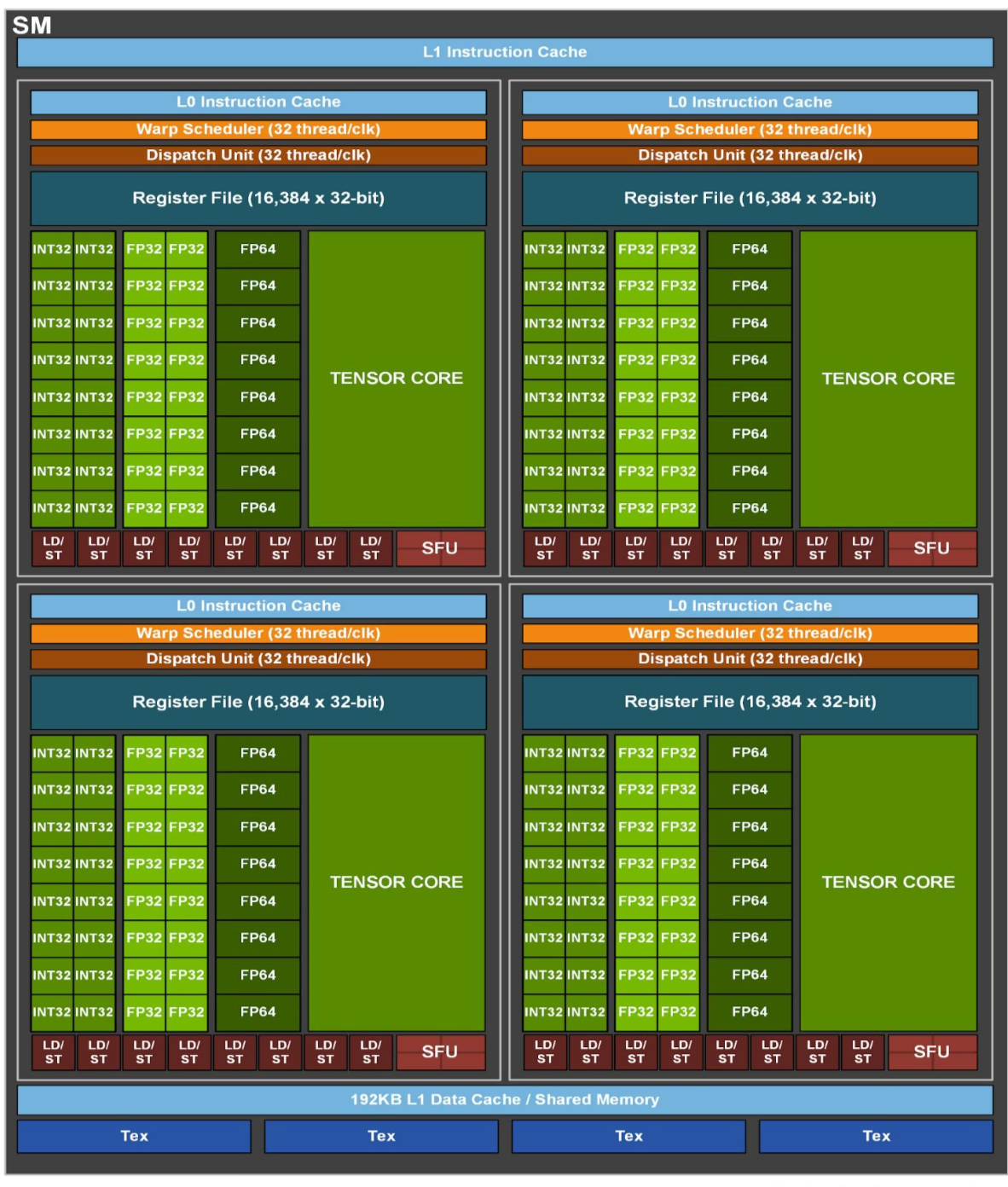
┌────────────────────────────────────────
│ SM(流式多处理器)
│
│ ┌────────┐ ┌────────┐ ┌────────┐
│ │CUDA核心│ │CUDA核心│ │CUDA核心│
│ │ ×64 │ │ ×64 │ │ ×64 │ ← FP32/INT32单元
│ └────────┘ └────────┘ └────────┘
│
│ ┌──────────────────────────┐
│ │ 第3代Tensor Core ×4 │ ← AI专用加速单元
│ │ 支持FP64/TF32/FP16/INT8 │
│ └──────────────────────────┘
│
│ ┌──────────────────────────┐
│ │ 共享内存 / L1缓存 │ ← 192KB
│ │ 128KB │
│ └──────────────────────────┘
│
│ ┌──────────────────────────┐
│ │ 寄存器文件 │ ← 256KB
│ │ 256KB │
│ └──────────────────────────┘
└────────────────────────────────────────
SM的独特之处是在于CUDA核心,64个/组,共4组 = 256个CUDA核心/SM(实际配置为64个FP32 + 64个INT32),同时还有第三代Tensor Core,支持结构化稀疏(性能翻倍),并和支持双精度FP64(消费级GPU没有)
| 数据类型 | 性能(每SM) | 用途 |
|---|---|---|
| FP64 | 19.5 TFLOPS | 科学计算、高精度AI |
| TF32 | 156 TFLOPS | 默认AI训练格式 |
| FP16/BF16 | 312 TFLOPS | 混合精度训练 |
| INT8 | 624 TOPS | 推理加速 |
| INT4 | 1,248 TOPS | 极致推理优化 |
核心技术:
结构化稀疏:自动跳过0值计算,有效性能提升2倍 多精度融合:单周期内处理不同精度数据
我们可以将流式多处理器视为一个原子单元(即最小单元)。当使用Triton这类工具编程时,操作层级就对应着SM。在每个SM内部,它包含许多流处理器(SP),而每个流处理器会并行执行大量线程。可以这样理解,SM拥有一套控制逻辑,能决定执行内容,比如实现分支判断;而SP则负责将相同指令应用于不同数据片段。这样就能实现海量并行计算。在这种架构下,每个SM是控制粒度的基本单元,而单个SP能独立完成大量计算。以上一代GPUA100为例,它包含128个SM——这远超大多数CPU的核心数量。每个SM内部都集成有大量SP和专用矩阵乘法单元,这就是其计算模型的基本形态。每个SM能操控其专属组件(如张量核心)进行计算。
SM同时管理数千个线程,决定哪个线程在何时使用哪个计算单元。它不像CPU那样为每个线程保存大量状态,而是轻量级切换,几乎没有开销。
SM内部有4条独立的指令流水线,每个时钟周期可以同时发射4条不同指令给不同的Warp(线程束)。
SM内置192KB的L1缓存/共享内存,供本SM内所有CUDA核心快速存取数据,延迟比全局显存低100倍。
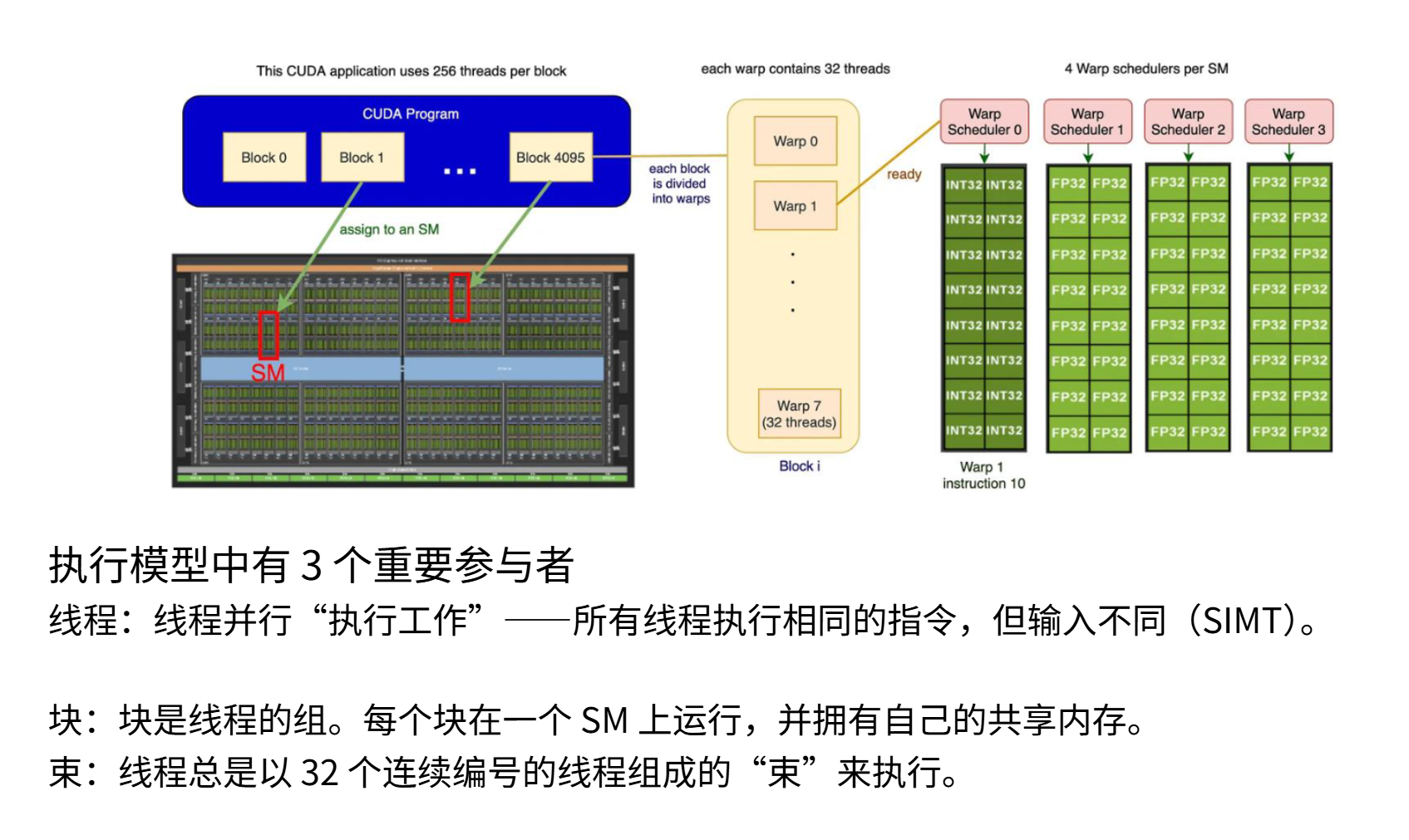
在GPU运行中,我们划分三个粒度层级来思考:块(block)、线程束(warp)和线程(thread),这是粒度逐级细化的顺序。块是大型线程组,每个块会被分配给一个SM处理。可以把每个SM想象成独立工作的单元,而块就是分配给它的处理单元。在每个块内部包含大量线程,每个线程代表待执行的任务单元。这些线程在执行时会分组运行,这种分组称为线程束。每个线程束由32个连续编号的线程组成,从块中提取出来同步执行。通过这个示意图可以看到:多个块被分配给不同的SM,每个块内包含多个线程束,每个线程束又由大量线程组成。所有这些线程都会在不同数据上执行相同的指令,这就是基本执行模型。
一个Warp是32个线程组成的固定小组,是SM调度的最小单元。Warp像"公交车",32个乘客(线程)必须同站同下,执行完全相同的指令。如果某个线程需要走不同分支(if-else),全车人要等它,这叫Warp Divergence(线程束分化)。
SM同时驻留64个Warp,4个Warp调度器每个管理16个Warp;Warp内32线程在SIMD单元上同步执行
Bock程序员指定的线程组,映射到1个SM上执行。Block像"施工队",队内成员可以共享工具(共享内存),可以通过哨子同步。
每个Block独占SM的共享内存和寄存器资源;Block内所有线程必须在同一SM内执行(不能跨SM);
线程是最细粒度的执行单元,每个线程执行同样的Kernel代码,但操作不同数据。Thread像"流水线上的工人",每人负责一个数据元素(如向量中的一个数)。
每个线程有私有寄存器(通常256个);线程ID:threadIdx.x 决定它处理哪个数据
GPU执行模型,多个线程(Warp)共享同一条指令,但操作不同数据。SIMT像"大合唱",指挥(指令)统一,但每个人唱自己的声部(数据)。
内存距离SM越近,访问速度越快。因此存在极高速的内存类型(如L1缓存和共享内存),它们位于SM内部,具有极快的读写速度。像寄存器这类需要频繁读写的元件,就应该放置在L1和共享内存中。
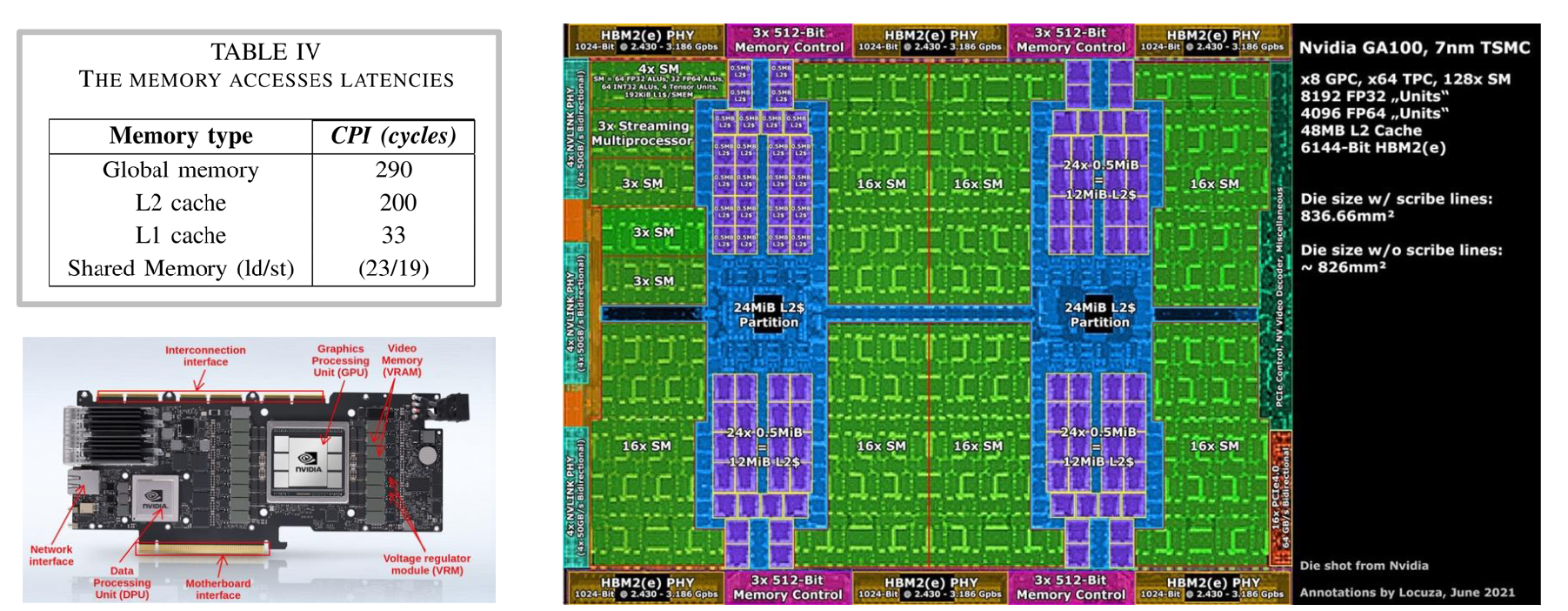
如图所示,这些绿色区域是SM集群,而蓝色区域代表紧邻SM的L2缓存,它们虽然不在SM内部,但物理位置仍然很近,速度也相当快(虽然比L1慢一个数量级)。在芯片外部(以这张3090或PCIeA100为例),GPU芯片旁边实际安装了DRAM内存,这意味着数据需要实际离开芯片通过物理连接进行传输。你可以在这张芯片图上看到边缘的这些黄色连接器。这些是HBM连接器,它们连接到实际GPU外部的DRAM芯片。
你可以从上图左侧看到访问这些存储所需的速度,SM内部存储器的访问速度要快很多,大约只需20个时钟周期就能从中获取数据,而访问L2缓存或全局内存则需要200到300个时钟周期。这个10倍的差距会对性能造成严重影响。如果某段计算需要访问全局内存,可能意味着你的SM会无工作可做,矩阵乘法全都完成了,任务耗尽,只能空转。这样利用率就不会高。这在某种程度上将成为思考内存架构的核心主题,也是理解GPU工作原理的关键。
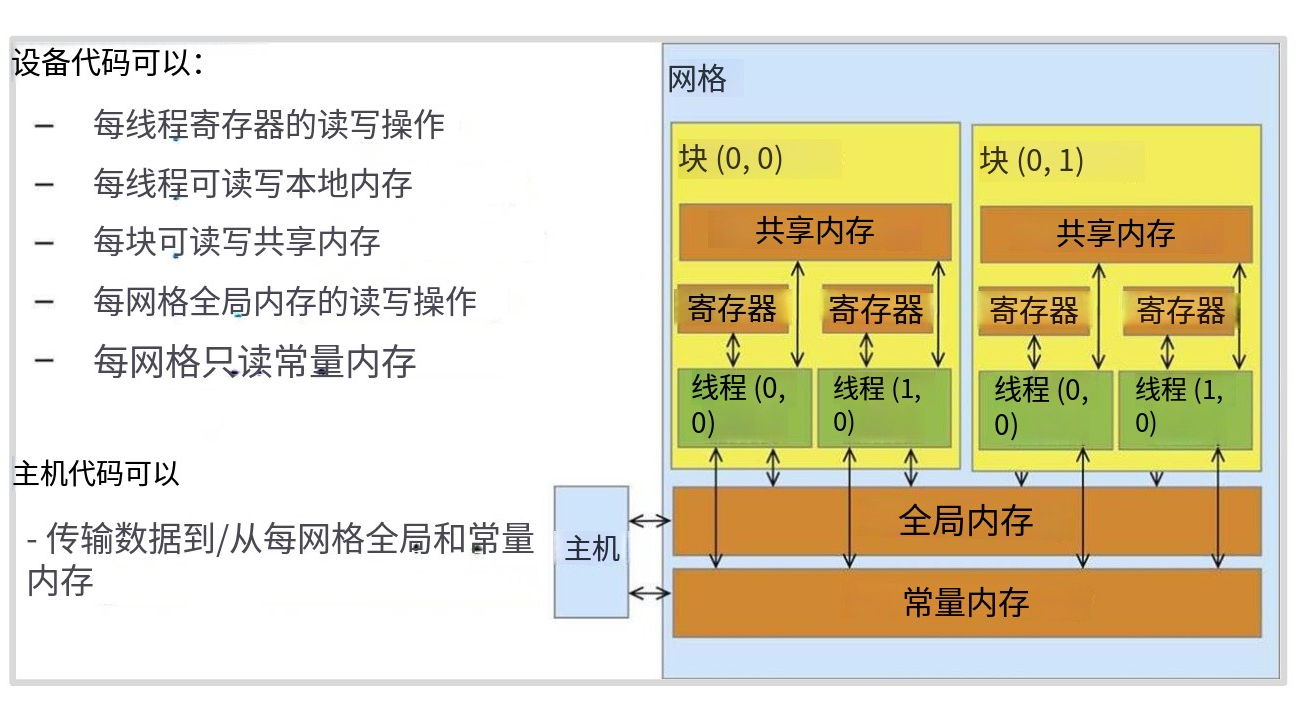
首先是寄存器,这是速度极快的存储单元,用于保存单个数值型数据。本地内存、有共享内存、还有全局内存、他们在内存层次结构中逐级递增,速度也越来越慢。
代码可以写入全局内存,也可以写入常量内存(虽然这个不常用)。每个线程都能访问自己的寄存器和共享内存,但跨线程块的信息需要写入全局内存。这意味着当编写执行任务的线程时,理想情况下它们应该操作相同的小批量数据,这样就不用跨线程。我们可以将这小批量数据加载到共享内存中,所有线程都能高效访问共享内存,执行完毕后任务就完成了。这是最理想的执行模式。反之,如果线程需要到处访问数据,就必须访问全局内存,速度会非常非常慢。
| 特性 | 参数 说明 |
|---|---|
| 物理位置 | GPU芯片外的HBM2e显存堆栈 |
| 容量 | A100: 40GB/80GB |
| 带宽 | 2,039 GB/s (A100) |
| 延迟 | ~500 GPU周期 (~250ns) |
| 编程控制 | 手动管理 (cudaMalloc) |
| 可见性 | 所有线程可访问 |
全局内存可以存放模型的所有权重、激活值、梯度(如GPT-3的1750亿参数);训练数据、中间结果、最终输出,将数据持久化;我们通过PCIe从主机内存拷贝数据,是CPU-GPU传输通道。
全局内存提供海量容量(80GB),能容纳大模型的巨大显存;成本相对低(HBM2e虽贵,但比SRAM便宜100倍)是GPU存储的基础。
| 特性 | 参数 说明 |
|---|---|
| 物理位置 | GPU芯片内,所有SM共享 |
| 容量 | 40MB (A100) |
| 带宽 | ~3TB/s |
| 延迟 | ~200周期 (~100ns) |
| 编程控制 | 自动管理 (硬件控制) |
| 可见性 | 所有SM所有线程 |
能够为全局数据加速,自动缓存全局内存的热点数据(如频繁访问的模型权重);是数据共享枢纽,SM之间通过L2缓存交换数据(比直接走HBM快3倍);能数据一致性保证,所有SM看到的L2数据一致。
能缓解显存带宽瓶颈,AI训练90%时间访问同一批权重,L2缓存命中可节省95%的HBM带宽;硬件自动管理程序员无需干预,降低编程复杂度。
| 特性 | 参数 说明 |
|---|---|
| 物理位置 | 每个SM内部 |
| 容量 | 192KB/SM (A100, 可配置) |
| 带宽 | 1TB/SM |
| 延迟 | 20-40周期 (~10-20ns) |
| 编程控制 | 完全手动 (__shared__) |
| 可见性 | Block内所有线程可见 |
它是一个线程协作的仓库,块(Block)内线程通过共享内存交换数据(如矩阵乘法的分块(Tiling)数据);可以手动性能优化,可将热点数据显式放入共享内存,实现接近寄存器的速度;L1缓存功能当不手动使用时,自动作为L1缓存缓存全局内存数据。
L1速度比L2快5倍,是GPU性能优化的核心战场;灵活性;高程序员可控,实现复杂算法(如规约、扫描、卷积);有成本效益:192KB/SM × 108 SM = 20MB总容量,比纯SRAM L2廉价。
| 特性 | 参数 说明 |
|---|---|
| 物理位置 | 芯片内专用缓存 |
| 容量 | 64KB (全局常量) |
| 带宽 | 广播机制 (1次读取服务32线程) |
| 延迟 | ~5周期 (命中缓存) |
| 编程控制 | 只读, __constant__声明 |
| 可见性 | 全GPU所有线程只读 |
可以存储广播数据;同一Warp内所有线程读取同一常量时(如神经网络的学习率),只需1次内存访问;可以存储配置参数;存储Kernel调用参数、查找表、常量系数。
它具有极致能效;广播机制节省99%带宽;专用缓存,不占用L1/L2资源。
| 特性 | 参数 说明 |
|---|---|
| 物理位置 | SM内,每个CUDA核心旁 |
| 容量 | 256KB/SM (A100) |
| 带宽 | 10TB/SM (理论) |
| 延迟 | 1周期 (零开销) |
| 编程控制 | 完全自动 (编译器分配) |
| 可见性 | 线程私有 |
寄存器文件能做到零延迟计算,它存储线程的局部变量、临时结果。并且做到极致并行,每个线程255个寄存器,支持深度流水线。
寄存器文件的特点是速度快,1周期延迟。但是昂贵,寄存器文件的容量少。他的容量限制决定并行度,寄存器用量越少,SM能驻留的Warp越多。
1. 速度和容量不可兼得
| 内存类型 | 速度 | 容量 | 成本($/GB)(估计) |
|---|---|---|---|
| 寄存器 | 1周期 | 256KB/SM | $1,000,000 |
| 共享内存 | 20周期 | 192KB/SM | $100,000 |
| L2缓存 | 200周期 | 40MB | $10,000 |
| HBM2e显存 | 500周期 | 80GB | $100 |
如果只用寄存器,8万块不够造1张卡;如果只用显存,算力浪费90%。分层是唯一经济可行方案。这是速度容量和成本的妥协。
2. 通用性和专用性取舍
全局内存是一个通用仓库,它什么都存,但速度慢。而共享内存是专用仓库(共享内存),程序员往往精确控制,速度极快。L1L2则是自动缓存,由硬件智能预测,无需编程。
3. 局部性原理和并行计算
刚访问的数据很可能再次访问(如循环中的权重),这样放在全局内存的开销就很大。除此之外还有空间局部性,相邻数据很可能一起访问(如矩阵的同行元素)
GPU的解决方案是划分层级:L2缓存利用时间局部性,缓存重复访问的权重;共享内存利用空间局部性,手动加载分块(Tiling)数据;Warp利用常量内存的广播特性,1次读取服务32线程。后面我们还会介绍。
下面这个表格就说明了GPU和CPU的区别:
| 特性 | GPU (A100) | CPU (Xeon) |
|---|---|---|
| 主存带宽 | 2TB/s | 100GB/s |
| 缓存控制 | 共享内存手动控制 | 缓存完全自动 |
| 线程寄存器 | 255个/线程 | 16个/线程 (x86) |
| 延迟容忍 | 通过Warp切换隐藏延迟 | 降低延迟至上 |
| 内存模型 | 共享内存显式同步 | 缓存一致性协议 |
CPU和GPU的本质区别是GPU内存系统是为吞吐量优化,容忍高延迟;CPU内存系统是为延迟优化,降低延迟。这导致GPU需要更多层级和手动控制。
TPU是Google自2015年起自主研发的ASIC芯片(专用集成电路),专为神经网络计算而生。如果说GPU是"图形计算王者转职AI",那TPU就是"生来只为AI"的纯粹战士。TPU从电路设计第一天起,只干一件事:那就是加速张量(Tensor)运算。
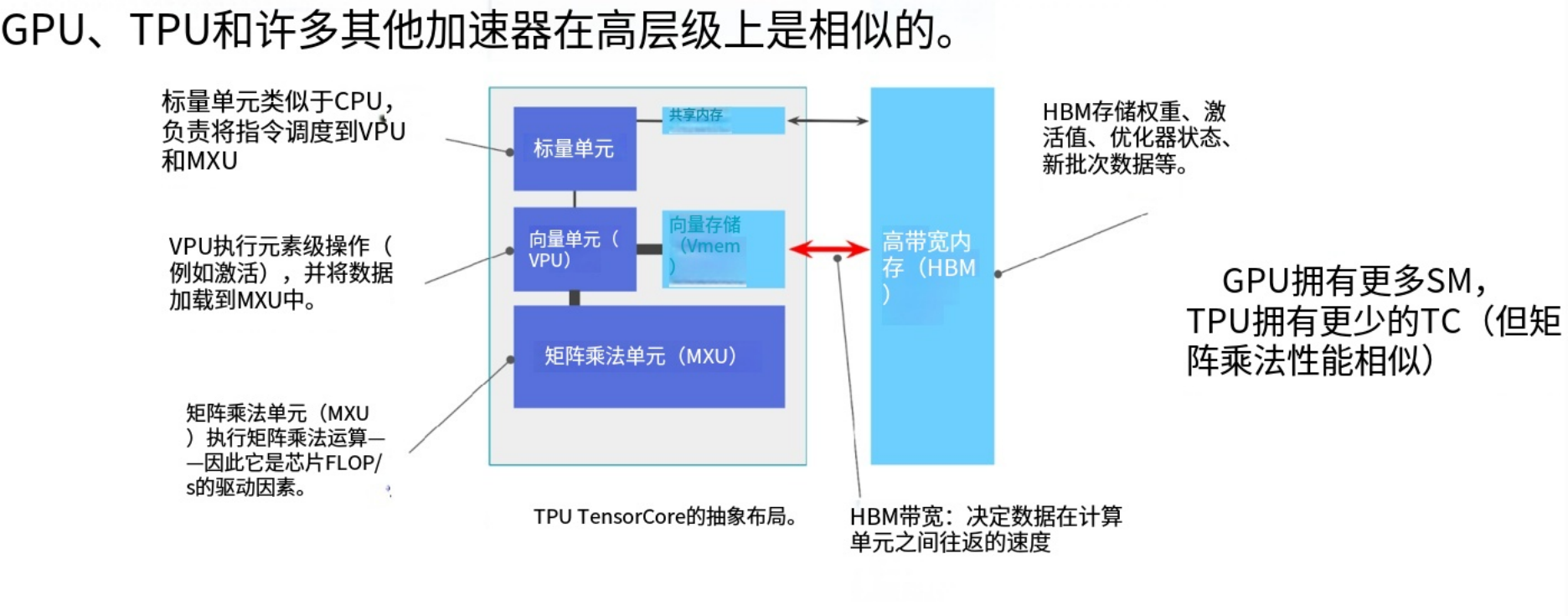
TPU内部具有张量核心(Tensor Core),对应GPU的SM,是独立原子单元;TPU的内部结构包含标量单元(控制逻辑,类似CPU)、矢量单元(逐项向量运算)、MXU(矩阵乘法单元):占芯片最大面积,专用于矩阵乘、矢量内存 + SM内存(片上高速存储)、 HBM(芯片外高带宽内存)。
TPU和GPU的本质区别是TPU仅优化矩阵乘法,不尝试执行通用计算,架构更简洁。TPU没有warp,只有块,只是矩阵乘法和非矩阵乘法的平衡。
所谓的张量核心(tensorcore),可以将其类比为SM(流式多处理器)。每个张量核心都是能处理数据的独立原子单元。它包含标量单元(本质是控制单元),也能执行类似CPU的任意操作;还有能处理向量的矢量单元,适合进行逐项向量运算;芯片最大部分是专门用于矩阵乘法的硬件模块MXU;同时配备极快的矢量内存和SM内存(这些都是芯片内部/张量核心内存)。
此外还有位于芯片外部的高带宽内存。它与SM的相似之在于都是外部慢速内存,内部高速内存;以及专门的矩阵乘法硬件。核心结构高度一致,区别在于加速器互联方式。张量核心在某些方面非常简单,因为它们专为矩阵乘法优化。与GPU不同,张量核心除了矩阵运算不尝试执行其他任务,因此架构上更为简洁,但概念上是相通的。
张量核心之所以被称为张量处理器,是因为它能处理任意维度的张量。它确实能操作任意张量,它可以进行索引操作。MXU执行的核心运算是矩阵乘法,因此它始终像是针对张量进行批量矩阵乘法的操作。它能处理张量,但实际执行的始终是矩阵乘法,而非更复杂的张量运算。
GPU之所以如此成功,关键在于其卓越的可扩展性。只需增加流式多处理器数量就能提升算力,无需担忧提高时钟频率带来的散热问题。编程方面,CUDA看似复杂,但由于其编程模型设计,实际并没有那么可怕,因为每个流式多处理器内线程会对不同数据执行相同指令,这种概念易于理解。特别是在处理矩阵简单运算时,这种简洁模型优势尽显。此外,这些线程都非常轻量级,可随时暂停或启动,这使得GPU能在每个流式多处理器内实现极高的利用率。
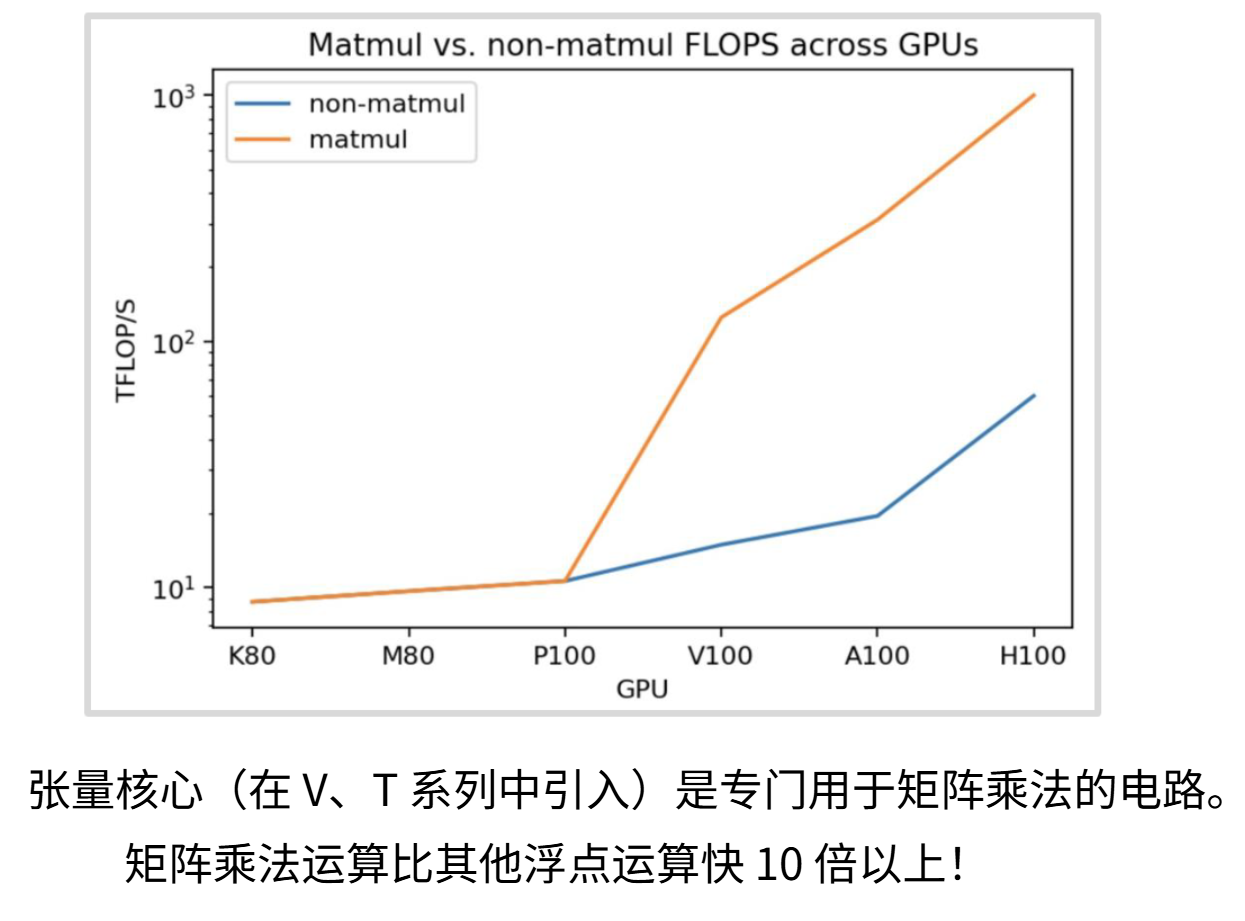
从上图可以看出GPU的世系从P100开始,蓝色的非矩阵运算和黄色的矩阵运算就开始分道扬镳,展现了巨大的差异,这主要原因是GPU厂商特意为矩阵运算优化的张量核心(tensor core)是专门用于矩阵乘法的电路。
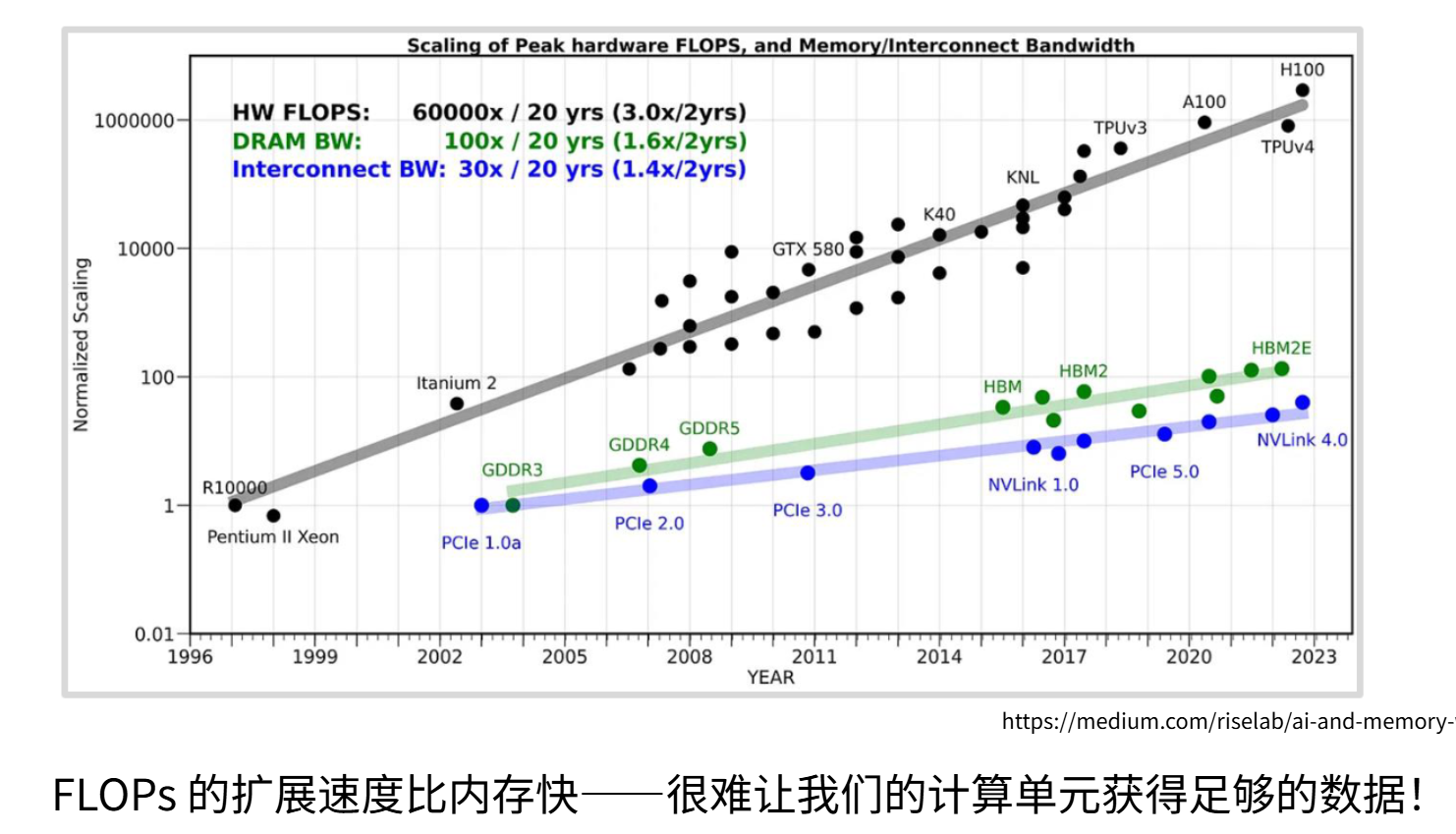
1980-2000年遵循登纳德缩放定律,即晶体管缩小,频率提升,功耗下降的趋势发展,但是现状是单线程性能2000年后趋于平缓,无法依靠频率提升。现代扩展方式是并行扩展(增加SM数量),从K20到H100,整数运算性能呈超指数增长(1-10万倍提升)。
但是其中的核心矛盾还没有解决---内存扩展速度远低于计算扩展。计算性能(灰线)是10万倍提升;内存带宽(绿线)大约100倍提升(GDDR-HBM2E);互联带宽(蓝线)增长最缓慢。
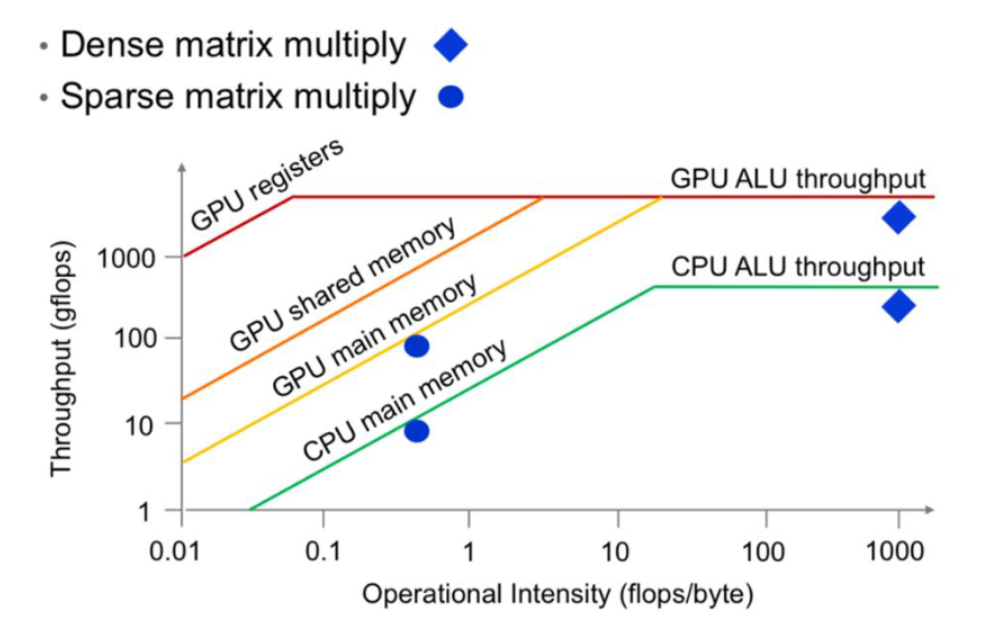
这是一个屋顶线模型,横轴是操作强度(Operational Intensity),表示计算与数据移动的比率。当操作强度高时,意味着计算设备在进行大量计算而数据移动相对较少;当操作强度低时,意味着数据移动占主导。纵轴是吞吐量(Throughput),表示计算设备每秒可以完成的浮点运算次数。
不同颜色的线代表不同的内存结构:
- GPU registers(GPU寄存器,红线):提供最高的吞吐量,因为寄存器访问速度非常快,但容量有限。
- GPU shared memory(GPU共享内存,橙线):速度次之,适用于需要在多个线程间共享数据的场景。
- GPU main memory(GPU主内存,黄线):速度较慢,但容量更大,适用于存储大量数据。
- CPU main memory(CPU主内存,绿线):速度更慢,因为CPU内存访问速度通常低于GPU内存。
它们到达的屋顶(内存墙)
- GPU ALU throughput:表示GPU的算术逻辑单元在理想情况下的最大吞吐量。
- CPU ALU throughput:表示CPU的算术逻辑单元在理想情况下的最大吞吐量。
图表显示,随着操作强度的增加,不同内存层次的吞吐量也会增加,直到达到某个上限。这个上限是由内存层次的带宽和延迟特性决定的。例如,GPU寄存器由于其高速访问特性,可以在较低操作强度下达到高吞吐量,但容量有限。而CPU主内存由于访问速度较慢,即使在高操作强度下,吞吐量也相对较低。
现在就可以看到未来趋势,内存墙问题将持续恶化,算法设计必须以内存为中心进行设计,不能浪费一丝一毫宝贵的内存,并且我们必须理解GPU内存的内存结构变化,使得计算快速进行不浪费内存。
当我们考察吞吐量或利用率时,会发现存在两种状态,位于曲线左侧的区域属于内存受限状态,而右侧区域则属于吞吐量受限状态。从某种角度理解,右侧区域意味着计算单元完全满载运行,所有矩阵乘法单元时刻保持运算状态;而对角线区域则存在某种内存瓶颈,此时计算能力受限于计算强度(即每字节浮点运算次数)。因此我们需要避开左侧的内存受限区域,力求处于右侧区域以实现计算单元的完全利用率,总之关键在于避免不必要的内存访问,尽可能减少对低速全局内存的访问频次。
下面是一个简单的分支预测
// 代码示例
if (x < 4) {
A; // x < 4 执行>
B;
} else {
X; // x > 4 执行
Y;
}
Z; // 无论X等于多少执行GPU采用SIMT(单指令多线程)执行架构,同一线程束(Warp)内的所有线程必须同步执行相同指令(仅操作数据不同)。现代GPU中,一个Warp通常包含32个线程(NVIDIA)或64个线程(AMD)。
当Warp内的线程遇到条件分支时,若部分线程满足x < 4走if路径,另一部分满足x >= 4走else路径,便发生了分支发散(Branch Divergence)。此时GPU采用掩码屏蔽机制串行化处理:先执行if分支,走else路径的线程被临时屏蔽;待if完成后,再执行else分支,此时if线程被屏蔽。两条路径的指令都会被执行,只是各自只有部分线程生效。这导致该Warp的执行时间近似等于两条路径耗时之和,计算资源利用率下降。
因此,核心优化原则是:避免同一线程束内的线程发散,要尽量避免条件分支。若一个Warp内所有线程都走同一路径(如线程x均小于4),则分支开销几乎为零。此外,发散不仅延长执行时间,还可能破坏内存访问的合并性,进一步降低带宽效率。
精度提升GPU速度的本质是用精度换取更快的计算和"省得多"的带宽。这背后是硬件电路简化、存储数据量减少、专用加速单元三重优化叠加。最明显的是计算数据和权重等所有元素的比特数减少时,需要移动的比特量就会大幅降低。即便从全局内存访问这些比特,其影响也会变得微乎其微。
| 精度类型 | 位数 | 表示范围 | 典型场景 | 速度提升 |
|---|---|---|---|---|
| FP32 | 32位 | 3.4×10³⁸ | 传统训练,精度敏感 | 基准 |
| FP16 | 16位 | 6.5×10⁴ | 通用训练/推理 | 2-4倍 |
| BF16 | 16位 | 3.8×10³⁸ | AI训练首选 | 2-4倍 |
| TF32 | 19位 | 3.4×10³⁸ | A100+默认格式 | 5-10倍 |
| INT8 | 8位 | 2⁸ ≈ 256 | 量化推理 | 8-16倍 |
| INT4 | 4位 | 2⁴ = 16 | 极致推理 | 16-32倍 |
| FP8 | 8位 | 动态范围 | Hopper/Blackwell | 10-20倍 |
我们知道浮点运算器的复杂度与位宽平方成正比。也就是位数越大的浮点运算器的体积和复杂程度越大。FP16的乘法器晶体管数量仅为FP32的1/4。代表着能在同样面积里放更多低精度的浮点运算器。而更多的计算单元意味着计算能力更强。
FP16数据只占FP32一半的寄存器空间,同样256KB寄存器文件可存两倍数据,同时16位数据总线带宽需求减半,同样带宽可传两倍数据,并且FP16乘法器延迟更低,频率可更高。
我们知道低精度下,同样参数量的模型文件,低精度下的占用的内存就是会比高精度下的低。比如GPT-3 175B参数,FP32 = 700GB;BF16 = 350GB;激活值,每层激活缓存,FP32 = 16GB;FP16 = 8GB;梯度,反向传播梯度,FP32 = 16GB;FP16 = 8GB。可以看出低精度下训练占用的内存会比高精度下的低得多。
我们可以进行简单的带宽计算,假设HBM2e带宽2TB/s,那么FP32下每秒传输500亿个参数;BF16下每秒传输1000亿个参数(翻倍)。
所以低精度下加载权重时间成倍减小;缓存命中率提升(同样缓存容量,存的数据更多),显存可容纳更大模型(350GB的LLaMA-65B在80GB显存上用BF16可跑)。
Tensor Core是NVIDIA为低精度矩阵乘设计的专用电路,它不是缩小版FP32,而是重构版矩阵引擎。
Ampere架构Tensor Core性能:
| 精度 | 峰值算力 | 相对FP32 CUDA核心 |
|---|---|---|
| FP32 | 19.5 TFLOPS | 1× (基准) |
| TF32 | 156 TFLOPS | 8× |
| FP16 | 312 TFLOPS | 16× |
| BF16 | 312 TFLOPS | 16× |
| INT8 | 624 TOPS | 32× |
加速的原理:
脉动阵列(Systolic Array):数据在阵列中流动,每个周期每个单元完成1次乘加,32×32阵列每周期完成1024次运算 权重静止:矩阵权重预加载到阵列寄存器,减少数据搬运 累加器优化:FP32累加器保证精度,输入输出用低精度
芯片面积优化,之前提到过精度越高的运算单元复杂度越大,1个FP32 CUDA核心面积约0.1 mm²;1个FP16 CUDA核心面积约0.05 mm²(节省50%);1个INT8 CUDA核心面积约0.025 mm²(节省75%)。
同时还有独特的架构设计,A100的SM中,Tensor Core复用寄存器文件,FP32模式64个CUDA核心活跃,每周期64次FMA;FP16模式:64个CUDA核心 + 4个Tensor Core活跃,每周期64次FMA + 1024次矩阵运算。
同样芯片面积,低精度可集成4倍计算单元,实现4倍吞吐量。
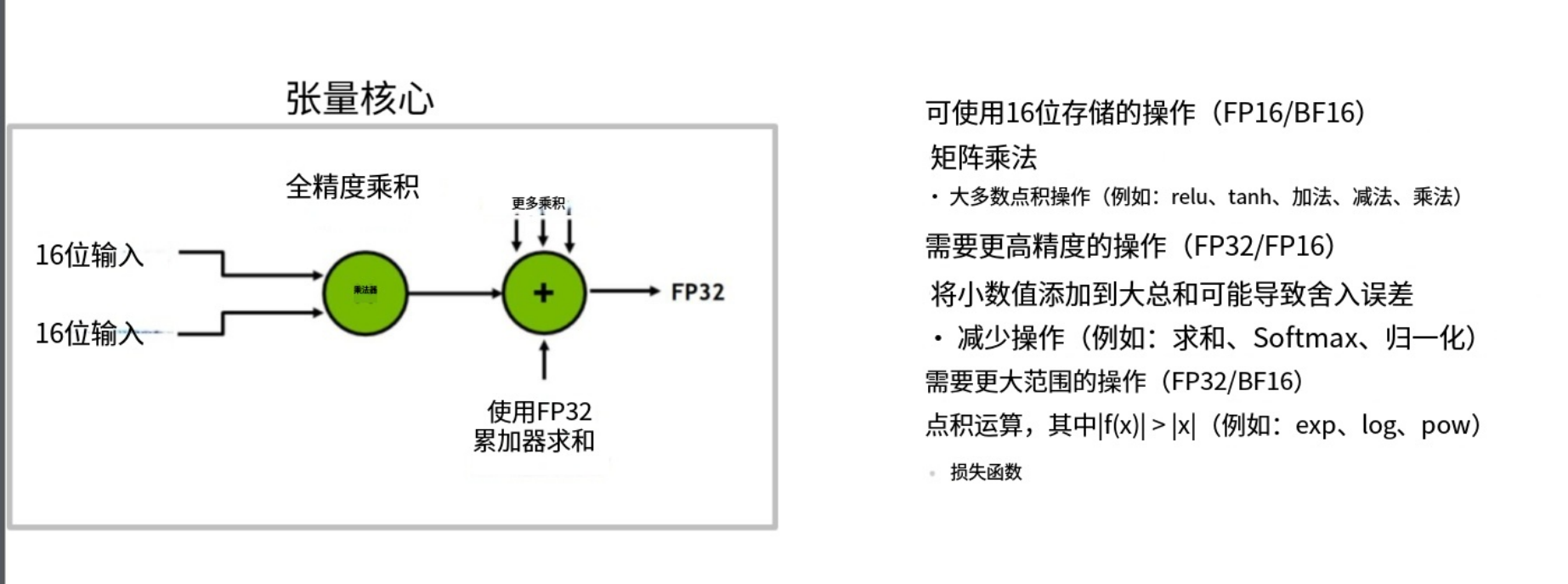
关键在于并非所有网络组件和训练算法都适合低精度处理。以矩阵乘法为例,混合精度矩阵乘法通常将输入设为16位低精度,但乘法运算会保持全32位精度。这是因为在累加部分和时,中间计算需要高精度保障,因此采用FP32累加器。张量核心最终输出FP32结果,可按需降回16位。由此可见输入数据可采用16位存储,但累加等操作需32位精度;某些运算(如指数函数)需要更大动态范围,可能适合bf16格式。要确保低精度训练时模型稳定性,需要大量精细的工程优化。但若能实现,当内存成为瓶颈时,从32位转为16位可直接使吞吐量翻倍。
算子融合通过消除中间结果内存读写和减少Kernel启动开销,实现2-5倍速度提升。
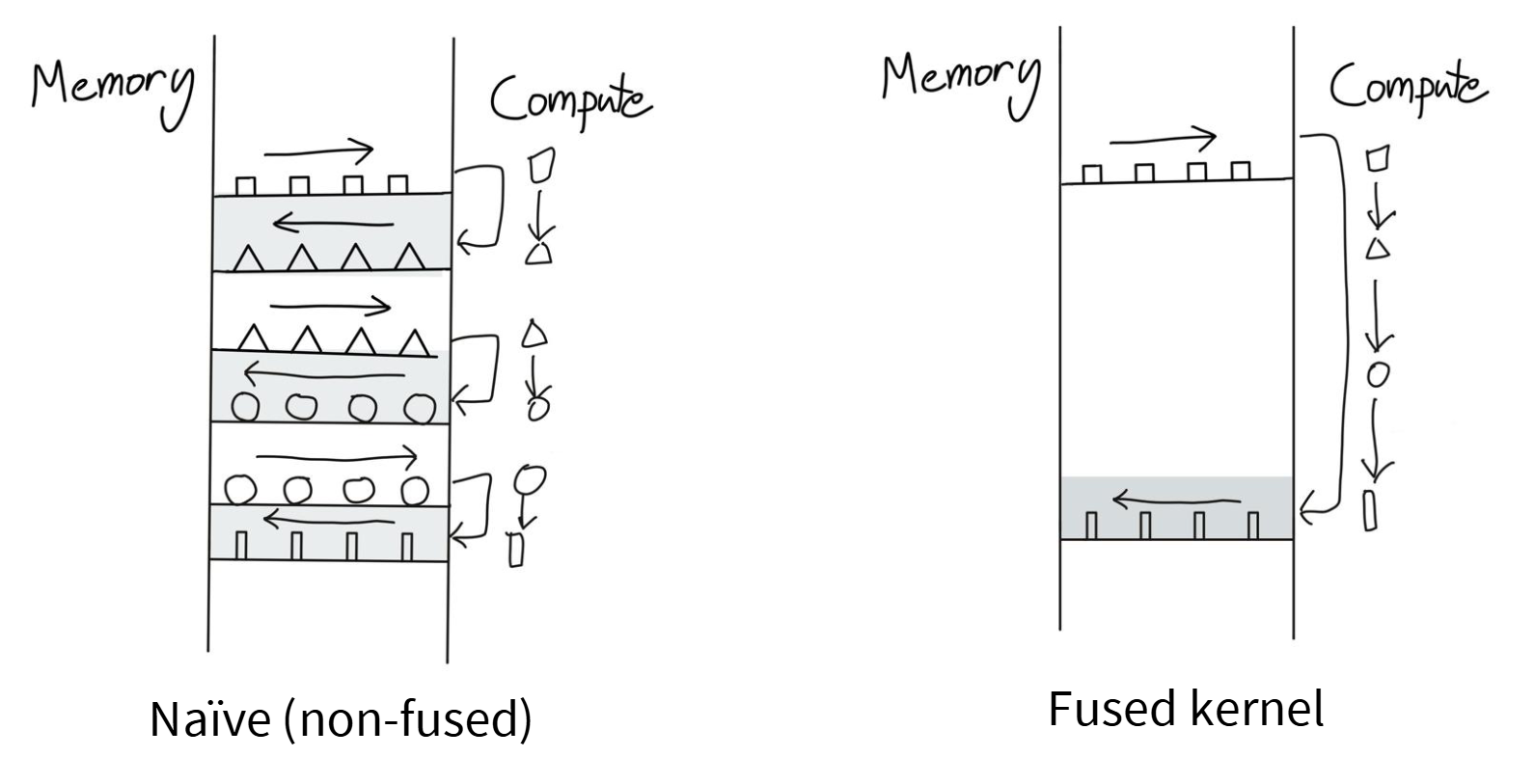
我们可以将GPU计算单元视为工厂,输入方形部件输出三角部件。若计算能力增强但内存传输带宽有限(好比传送带容量固定),新增的工厂设备将无法充分利用,整体性能仍受限于内存到计算的传输速率。
想象左边这张图的左侧是内存区域,右侧是计算单元。进行运算时,我们从一个方形数据开始,把方形数据从内存搬运到计算单元,执行某些操作后将其转为三角形,再把三角形移回内存。接着发现又需要这些三角形数据,于是重新将它们送入计算单元,三角形变成圆形,如此循环往复。数据在计算单元和内存之间来回传输,如果在GPU上直接进行简单运算,并立即将结果写回全局内存,最终就会形成这种模式。如果统计单块数据的往返次数,这种方式的效率极其低下,会产生巨大的内存开销。
现在观察右侧的计算流程:我们发现这些运算之间不存在依赖关系,所以将方形直接转为三角形再转为圆形,最后变成矩形再传回内存。我们让所有数据始终驻留在计算单元内。
这其实就是融合核函数的思维模型,当一系列运算需要按顺序处理同一数据时,与其每次都将中间结果写回存储,不如尽可能在单个计算单元完成所有操作,直到必须传回内存时才进行传输。这就是核融合的核心思想。
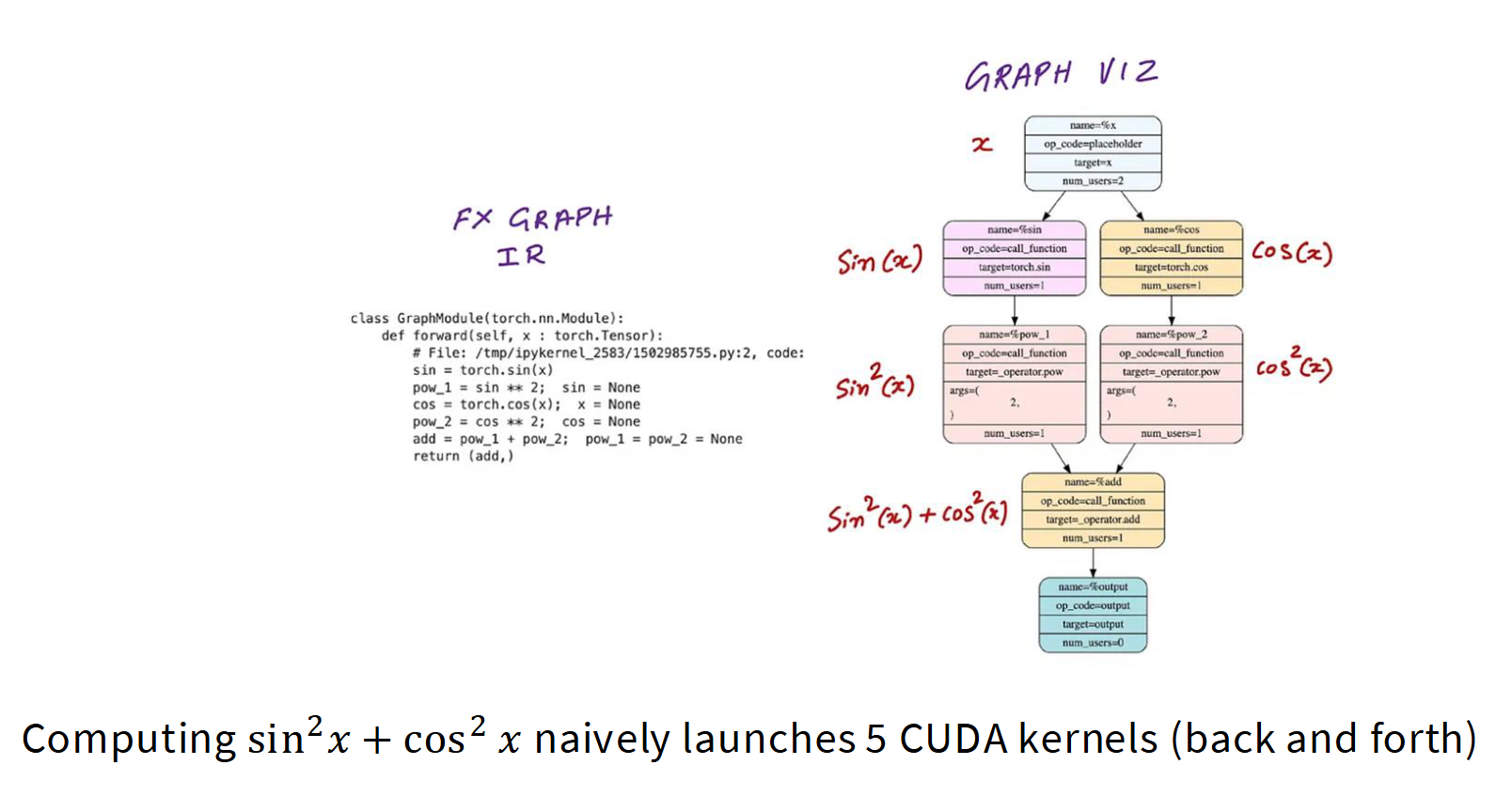
假设我们编写了一个神经网络模块,输入
但是我们发现这五个运算其实没有复杂依赖,仅需少量内存,完全可以将它们融合成单个运算,在GPU单线程上完成所有处理,无需将数据写回全局内存。
本质上算子融合是将多个连续操作合并为单个CUDA核函数,避免中间结果写回全局内存,
重计算的核心思想是通过增加计算量来避免内存访问。
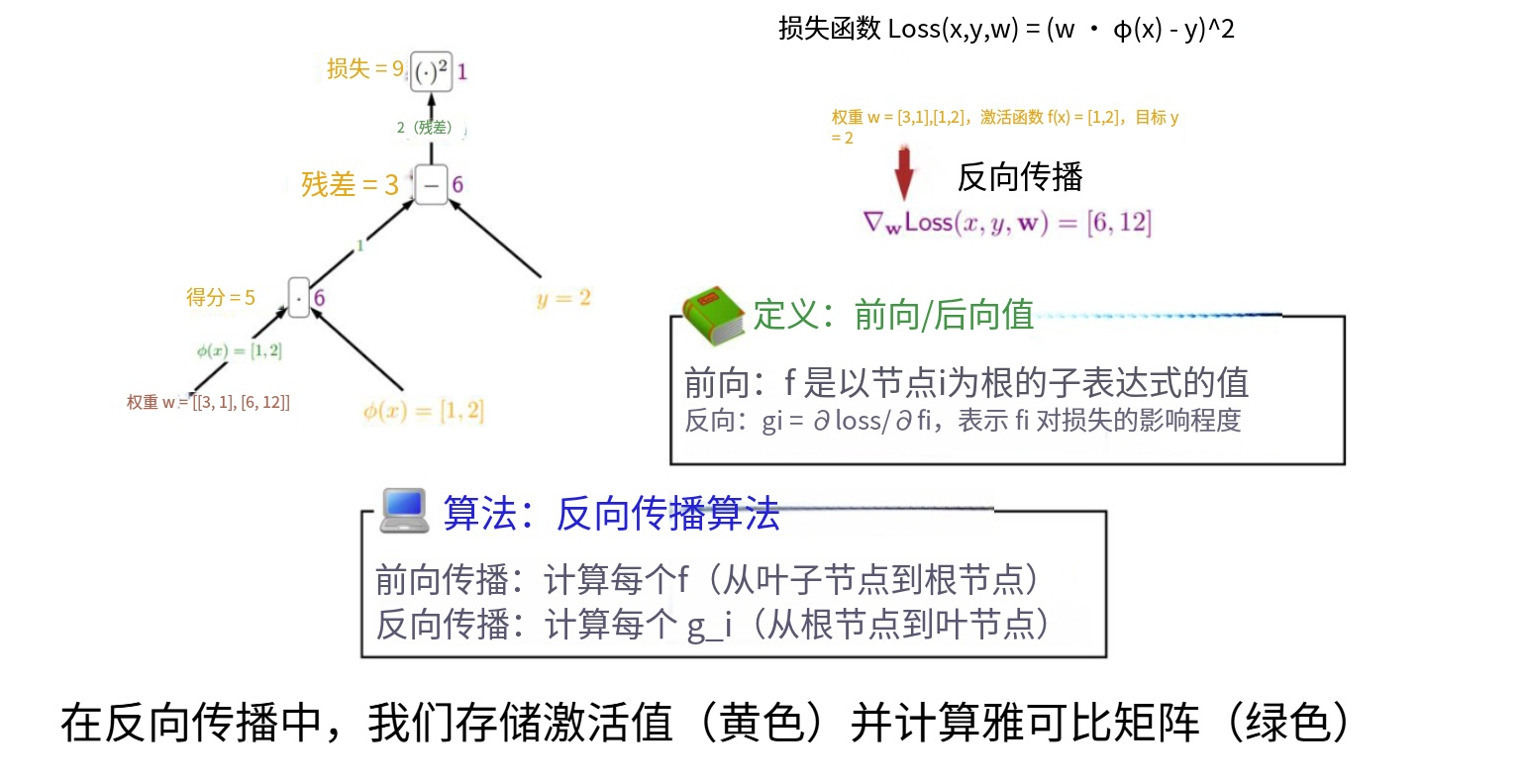
我们获取最底层的输入数据(黄色节点),然后我们向上传播激活值。这些也是树上的黄色数值。接着我们反向计算雅可比矩阵。这些是边上的绿色数值。为了计算梯度,我将进行反向传播,需要进行乘法运算。我们会将雅可比矩阵和激活值结合,反向传播梯度。仔细想想,前向传播后的那些黄色数值必须被存储起来。它们被存储后,需要从我们存放的全局内存中提取,并送入计算单元。
从机制上来说,这个过程是必然发生的。但这可能会导致海量的内存输入输出操作。但是能够避免这种情况。
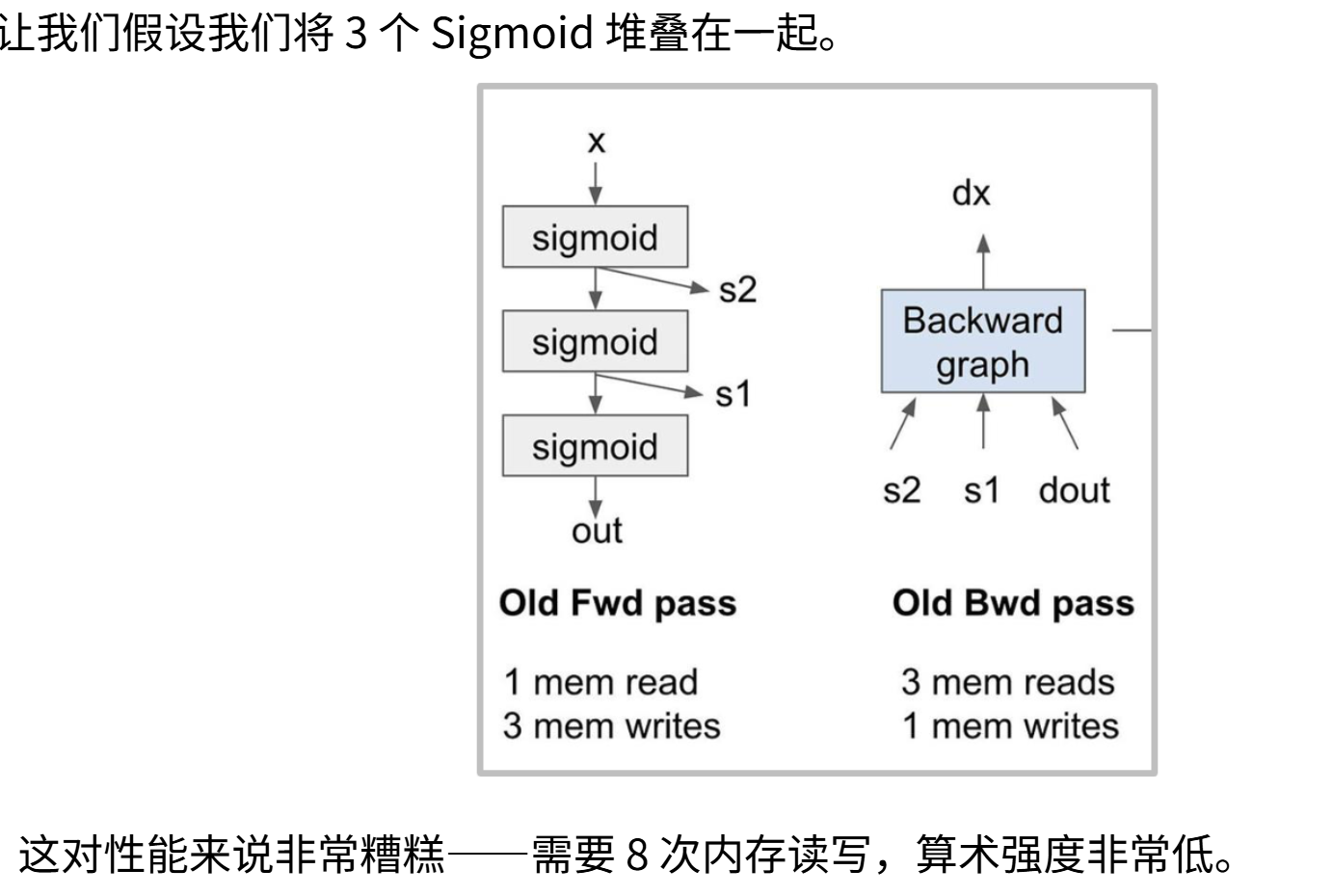
假如我们将三个
而重计算的核心思想就是:不存储那些激活值也不会将它们放入内存,而是在反向传播过程中动态重新计算。在新的前向传播过程中,不存储S1和S2:输入
总的来说,这次的重计算不储存s1 和 s2,在反向传播中重新计算。这是计算的时间成本和内存的写入和读取的内存和时间成本的考量,重计算适用于计算成本比读写成本小的场景。
通过在本地内存中实时重算S1、S2和输出值,避免了全局内存读取操作,最后只需一次dx的内存写入。在完成相同计算的前提下,现在只需要5/8的内存访问量。付出的代价是必须重新计算这三个sigmoid函数。但如果计算单元原本就因为内存瓶颈而处于闲置状态,这就非常合算,用过剩的计算能力换取紧缺的内存带宽。
GPU中的慢速内存(即全局内存/DRAM)实际上极其缓慢。为了提升速度,硬件层面会进行特定优化。

其中一项DRAM硬件优化是:当读取某个内存值时,实际获得的不仅是目标值,而是整块内存数据,被称为突发模式。假设读取大内存块的第一个值,内存不仅会返回0,还会同时返回0123这四个值。
每个地址空间都被划分为突发段,系统会直接返回整个突发段而非仅目标数据。当寻址内存时,数据传输到放大器是最耗时的步骤。而突发段作用是一旦完成这个步骤,就能免费获取大量字节数据。突发段设计正是为了优化耗时的数据迁移过程。如果内存访问模式得当,就能显著加速内存访问。比如要读取整个数据块,若采用随机访问,需要执行与查询长度相当的次数;但若先读取首值,就能立即获取整个突发段;接着读取第4个值,又能立即获得第二个突发段。通过精心设计内存访问策略,仅从每个突发段提取所需数据,理论上可实现四倍吞吐量,这就是内存合并技术。
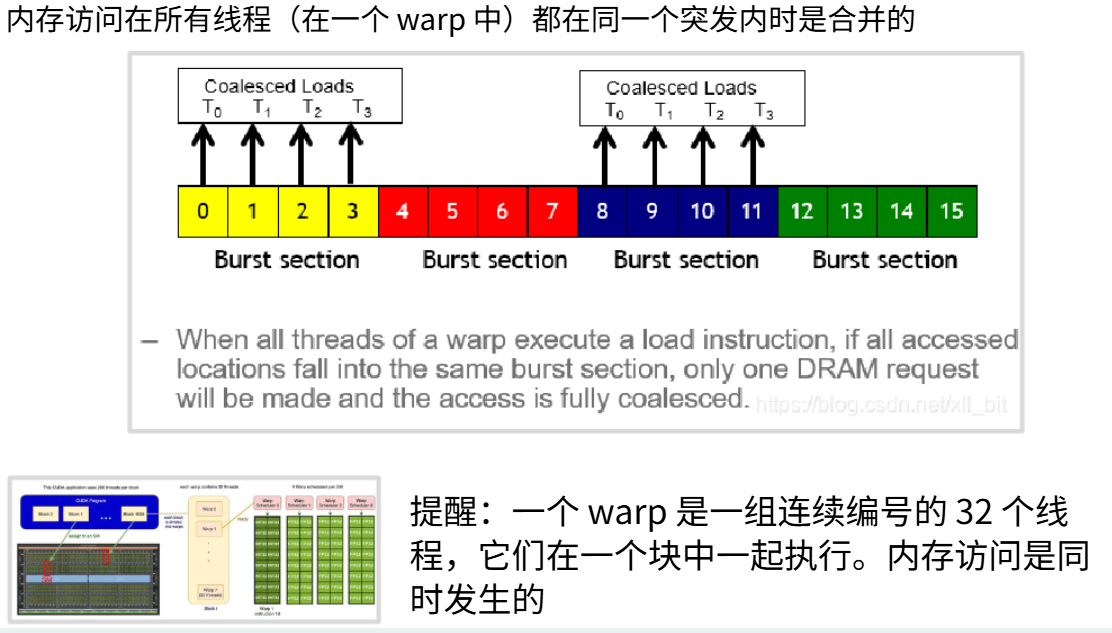
当线程束中的所有线程都位于同一突发段时,智能硬件和编程模型会将这些查询聚合不再分别查询0123,而是通过单次查询0即可从突发模式DRAM中同时读取所有四个值。注意线程束包含32个有序线程,这些线程的内存访问是同步进行的。通过优化可以一次性获取全部4字节数据,使内存吞吐量提升四倍。
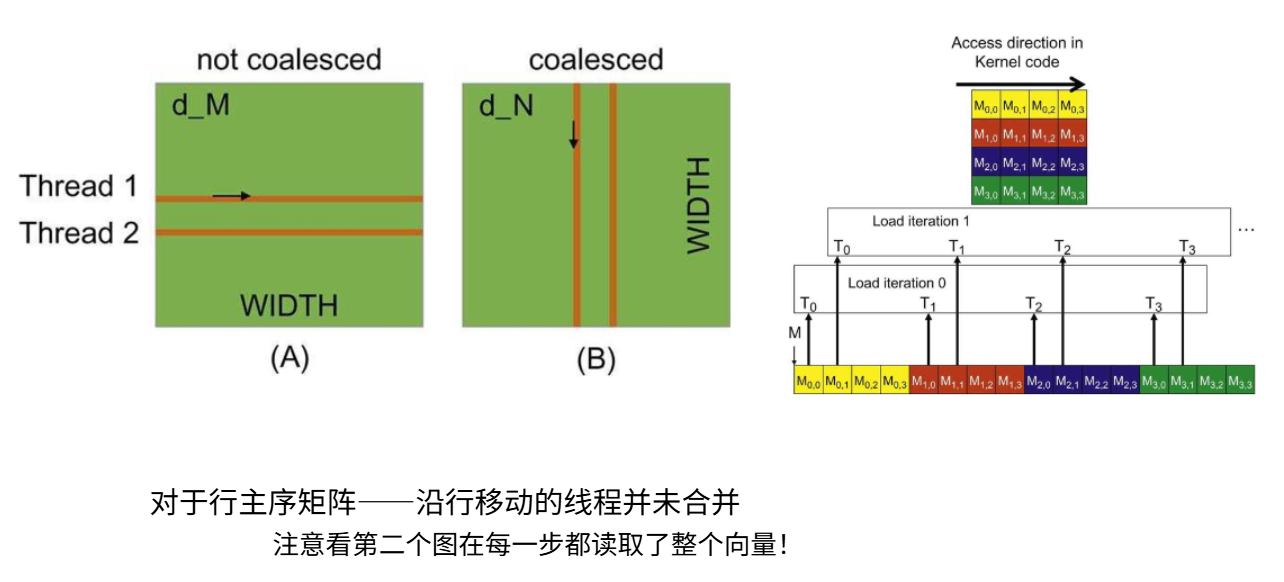
以矩阵乘法为例,假设有两种矩阵读取方式:按行遍历(每个线程处理一行)或按列遍历(每个线程处理一列)。实际上左侧按列遍历的模式会非常缓慢,因为内存访问无法合并;而右侧按行遍历时,线程内存访问地址连续,可以实现内存合并。
右侧是一个矩阵和矩阵在内存中的位置,以矩阵乘法为例,假设矩阵采用 row-major 方式存储。考虑两种线程访问模式:
1)每个线程负责矩阵的一整行; 2)每个线程负责矩阵的一整列。
当每个线程处理一行时,同一个 warp 内的线程会访问彼此相距较远的内存地址,这种访问模式无法实现内存合并(coalescing),因此内存带宽利用率很低,性能较差。相反,当每个线程处理一列、并且在同一时间步访问同一行的不同列元素时,warp 内线程访问的是连续的内存地址,可以实现完全的内存合并,从而显著提升访问效率。
从内存布局角度看,如果一组线程从左向右访问矩阵中同一行的连续元素,那么这些访问都落在同一个或相邻的内存块段中,只需一次或少量内存事务即可完成数据加载。但如果线程访问的地址分散在多个不连续的内存块段中,则每个访问都可能触发独立的内存事务,导致实际内存访问速度远低于理论带宽。
这种内存访问顺序的差异属于非常底层的优化细节,但在 GPU 程序中却至关重要;一旦遍历顺序设计不当,性能往往会出现数量级的下降。
分块的核心思想是通过分组内存访问来减少全局内存的访问量。
通过矩阵乘法的例子来解释,原始的矩阵乘法算法严重问题,从这个简单的矩阵乘法算法开始:左侧是
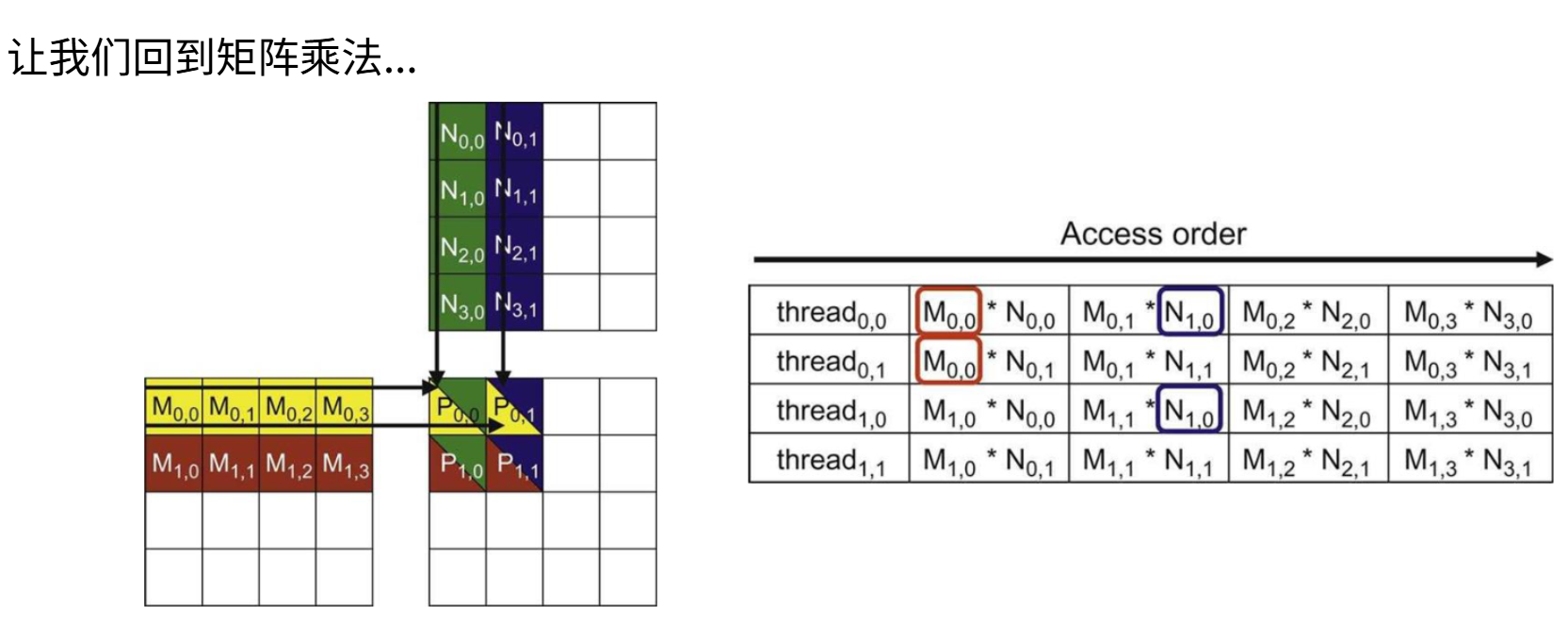
这里的内存访问是非合并的,行矩阵的访问顺序是不连续,且存在重复的内存访问。例如
问题在于能否避免过多的全局内存读写,理想方案是用一段时间将数据块从全局内存加载到高速的共享内存,在共享内存中完成大量计算,最后再处理下一数据块。这样能最小化全局内存访问。
化.png)
在矩阵乘法中我们将
另一个优势是由于加载的是完整数据块,我们可以按任意顺序(例如列优先或行优先)遍历这些子矩阵,从而在从全局内存加载数据块到共享内存时实现内存访问的合并。采用分块访问策略能带来全方位的性能提升。
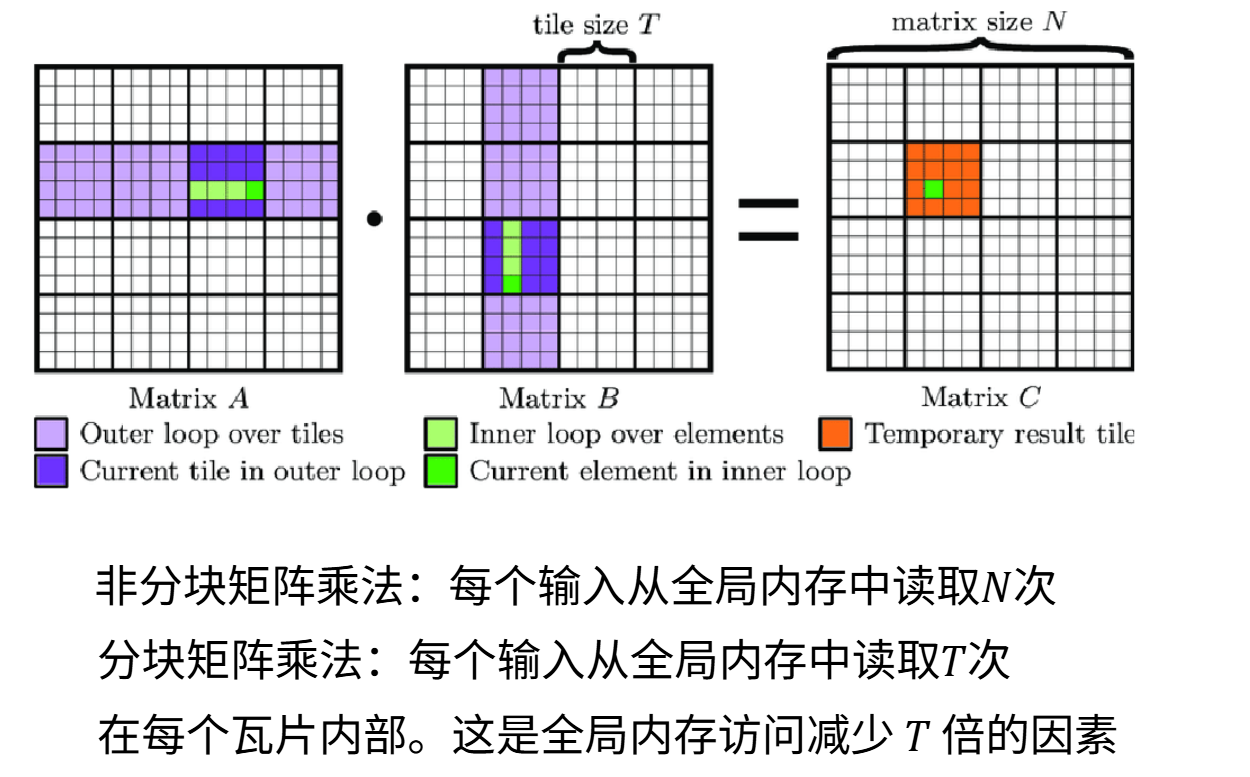
现在我们可以进行分块计算的数学分析。假设有矩阵
分块的复杂性.png)
分块策略非常复杂,这是导致GPU和矩阵乘法性能表现令人困惑的根源之一。假设采用128这个规整的分块尺寸,当处理256尺寸的完整矩阵时效果很好,一个2x2的分块数据加载很顺畅。假设在列方向使用257大小的分块,那么需要六个分块才能覆盖这个矩阵,而右侧的两个分块里面没有数据。问题在于每个分块都会被分配给一个流多处理器(SM),每个分块对应一个线程块,线程会在各自分块(Tiling)内执行运算。所以右侧那两个分块几乎不会执行什么计算,对应的SM基本上会处于闲置状态。
如果遇到计算瓶颈,我们希望更均衡地在SM之间分配负载,因此必须优化分块尺寸来避免这类情况。但是确定分块尺寸涉及很多复杂因素。必须实现内存访问的合并不能超过共享内存容量,所以分块不能太大;还要对矩阵维度进行划分,最好能均匀或接近均匀地分割,避免出现这种SM利用率极低的情况。
另一个非常深入细节的复杂问题是分块划分与突发传输区段的交互。假设矩阵布局很规整,每个突发传输区段都能与分块完美对齐。读取这个分块只需要获取四个不同的突发传输区段,就能载入整个分块。但如果在末尾增加一个元素,矩阵布局就会导致突发传输区段错位。
比如上图,加载分块时,第一行还能作为一个完整的突发传输区段载入,但第二行就分散在两个不同的突发传输区段里,需要两次读取才能获取,依此类推。仅仅因为末尾多了一个元素,就导致内存访问量翻倍——这是突发传输区段与对齐布局发生偏移造成的。本质上,如果分块或矩阵尺寸不是突发传输区段的整数倍,就容易出现这种行与突发传输区段不对齐的情况,导致内存访问量翻倍。解决方法是通过填充(padding)使矩阵尺寸变得规整,让突发传输区段与分块尺寸重新对齐。虽然这些内容非常底层,但要想充分压榨矩阵乘法的性能,就必须考虑这些细节。如果忽略这些,实际运行时就可能遭遇性能陷阱。

图6.24 FlashAttention V1原理图
Transformer在长序列上计算和显存复杂度为O(N²),瓶颈主要来自attention的多次带宽显存(HBM)读写访问。许多近似注意力方法通过降低理论复杂度来缓解该问题,但由于GPU kernel调度和内存访问不规则,往往无法实现实际运行时加速。FlashAttention则是从计算层面通过分块策略,在静态随机存取存储器(SRAM)内完成
FlashAttention在数学上与标准attention等价(除浮点误差外),属于精确重排而非近似计算。

图6.25 左图:前向传播+反向传播的运行时间;右图:注意力内存使用情况。
根据图 6.25的分析可以发现,尽管不同Attention实现方法的运行时间相差不大,但FlashAttention的显存占用明显更低,约为其他实现的一半。因此,在长序列场景下FlashAttention具有更好的可扩展性和更高的资源利用效率。
其中Q、K、V均
# 初始化
m_i = -inf
l_i = 0
O_i = 0
for each Q block i:
load Q_i
m_i = -inf
l_i = 0
O_i = 0
for each K,V block j:
if causal and j > i:
continue
load K_j, V_j
S_{ij} = Q_i @ K_j^T # (B_r, B_c)
if causal and i == j:
apply mask to S_{ij}
# softmax累加 → 归约
update m_i, l_i, O_i(online softmax)
write O_i to HBM
为什么FlashAttention V1要分块(tile/block)?
在GPU中,Attention的计算主要瓶颈在缓存(SRAM)容量和计算带宽。直接计算
$Q K^T$ 会生成一个$N \times N$ 的中间矩阵,当$N$ 较大时,无法一次性放入高速缓存,并且同时频繁访问HBM会加大缓存压力;FlashAttention的核心思想是:通过分块计算,减少对全局内存的访问,提高缓存利用率,并保证计算效率和数值稳定性。具体做法是在SRAM中处理可容纳的小块,同时进行softmax累加,从而大幅降低全局内存访问压力。
具体举例:
- 假设Q、K的形状为
$1024 \times 512$ 。 - 将Q按行分成8块,每块大小
$128 \times 512$ ,将$K^T$ 按列分成8块,每块大小$512 \times 128$ 。 - 每次只在SRAM内计算得到一个
$128 \times 128$ 的子矩阵并累加结果,直到完成整个$Q K^T$ 和$Q K^T V$ 的计算。
online softmax与标准softmax在数学上完全等价,二者都需要进行全局归一化。不同之处在于,online softmax采用流式(streaming)计算方式,在遍历过程中动态维护当前最大值和归一化因子(指数累加和),从而无需存储完整的中间结果,这种流式特性使其能够与分块计算自然结合。在FlashAttention中,Attention分数按tile逐块计算,并在块间持续更新最大值和归一化因子实现跨块的全局归一化。
online softmax在6.7.1 FlashAttention V1计算作用过程详细分析:
m_{ij} = rowmax(S_{ij})
m_new = max(m_i, m_{ij})
l_i = exp(m_i - m_new) * l_i
+ sum(exp(S_ij - m_new), axis=1)
O_i = exp(m_i - m_new) * O_i
+ exp(S_{ij} - m_new) @ V_j
m_i = m_new
O_i = O_i / l_i
因此online softmax成为FlashAttention V1在不显式构造整个注意力矩阵情况下完成精确Attention计算的关键组件。
FlashAttention V1 通过分块和在线 softmax 解决了注意力计算的显存瓶颈,但其循环顺序和并行策略并未充分发挥现代 GPU(尤其是 A100 及后续架构)中矩阵乘法(Tensor Core)的峰值吞吐能力。V2 在保持 V1 核心思想的基础上,对算法进行了深度重构,实现了更高效的并行与更低的非矩阵乘法开销。
在FlashAttention V1中,计算采用外循环遍历 IO效率,但带来的问题是:该过程中存在跨块的在线归一化与重标定操作(max、exp、rescale) 形成了数据依赖链,使得计算在执行上表现为matmul → 归约(归一化) & 标量更新 → matmul → 归约 & 标量更新...的交替模式,这些非matmul会降低Tensor Core的利用率,并限制算子融合与并行调度效率。
FlashAttention V2的出现并没有改变 数据依赖链带来的性能问题:
- 将原先“一个
$Q_i$ 对应一个线程块串行扫描所有$K、V$ ”的方式,改为对同一$Q_i$ 在$K、V$ 维度进行切分,并由多个线程块并行处理(split-KV并行); - 保留online softmax的数学形式,但通过分块并行计算 + 跨线程块归约的方式,将原本沿
$K、V$ 维度的“串行依赖处理”转化为并行计算 + 末端归约,从而显著提升并行度与硬件利用率。
for each Q block i in parallel: # V2的核心:Q 维度并行
load Q_i into SRAM
# 初始化
m_i = -inf
l_i = 0
O_i = 0
for each K,V block j:
load K_j, V_j into SRAM
S_ij = Q_i @ K_j^T # Tensor Core
m_ij = rowmax(S_ij)
m_new = max(m_i, m_ij)
# 重标定旧累积
alpha = exp(m_i - m_new)
P_ij = exp(S_ij - m_new[:, None])
l_ij = rowsum(P_ij)
# 更新归一化因子
l_new = alpha * l_i + l_ij
# 更新输出(核心优化点之一),online softmax累加
O_i = (alpha[:, None] * O_i) + (P_ij @ V_j)
m_i = m_new
l_i = l_new
# 末端归约
O_i = O_i / l_i[:, None]
write O_i back to HBM
V1 → V2性能提升的原因:
(1). 降低非矩阵计算对执行的干扰(而非减少其总量)
在V1中,每处理一个
(2). V2并未减少这些操作的数学次数(仍然是
是将原本沿
(3). 提升Tensor Core利用率(来自调度与并行重构,而非“批量提交”)
- V1中,由于online softmax 的逐块依赖,matmul与标量更新交替执行限制了Tensor Core 的持续工作能力;
- V2通过增加并行线程块(尤其是split-KV),让更多matmul可以在不同SM上同时进行,从而提高Tensor Core的整体占用率。
值得注意的是,SM的整体占用率并不等同于其实际计算单元的利用率(utilization)。即使线程块已充分填满SM,如果数据加载与计算之间存在同步等待,仍会导致Tensor Core等执行单元出现空闲。而FlashAttention V3正是在这一背景下提出,通过引入异步执行与流水线机制,进一步提升计算与数据传输的重叠程度,减少硬件空闲。
因此,V2提升的本质是:更多并行matmul + 更少串行依赖,而不是单线程内“批量提交” 的matmul。
一句话对比V1、V2版本——FlashAttention V2的本质不是减少FLOPs,而是把“online softmax的时间串行依赖”改写成“空间并行”。
V2 对分块大小进行了精细调整,以匹配 GPU 的 SRAM 容量和寄存器资源。以 A100 为例,每个 SM 拥有 192KB 共享内存,V2 选择
性能表现
-
速度提升:在 A100 上,对于序列长度 512
16k,V2 相比 V1 平均加速 **1.72.0 倍**,相比 PyTorch 标准实现加速 8~10 倍。 -
显存占用:与 V1 保持一致,仍为
$O(N \cdot d)$ ,但支持的最大序列长度因计算效率提升而有所扩展(单卡 40GB A100 可稳定训练 32k 长度)。 - 硬件适应性:V2 的优化策略对 Ampere 及后续架构(如 H100)同样有效,为后续版本(V3)奠定了高效并行的基础。
FlashAttention V2通过提升序列维度的并行度并优化计算调度,在保持V1内存访问高效(IO-aware)特性的前提下,显著提升了Tensor Core的利用率,从而将注意力计算的整体吞吐推向更高水平。这一改进使得长上下文Transformer的训练和推理在单卡或有限资源环境下更加高效,成为现代高性能Transformer系统中的重要优化组件,并被包括Llama 2、GPT-4等在内的多种大模型工程实现所采用或借鉴。
FlashAttention V2在A100等Ampere架构GPU上已接近Tensor Core的理论极限,但 H100(Hopper)架构引入了革命性的新特性:异步执行模型(支持计算与数据搬运完全重叠)、WGMMA(Warpgroup Matrix Multiply-Accumulate)指令以及原生FP8支持。V3正是针对这些硬件特性进行深度优化的产物,其目标是让注意力计算在H100上实现接近理论峰值的吞吐量,并充分利用低精度格式带来的算力红利。
FlashAttention V3并不是建立在“Q 外循环、K/V内循环”的顺序变化之上,而是在V2已有的并行与归约框架基础上,对底层执行机制进行重构。其核心改进是引入基于NVIDIA Hopper(如H100)的异步计算能力,将计算流程组织为生产者–消费者流水线。
其核心思想是利用Hopper架构中的异步指令(如TMA数据搬运与WGMMA矩阵乘法),实现:
- 数据加载(global → shared memory)与Tensor Core解耦;
- 跨warp group的流水线并行执行,在计算一个block的同时,预取下一个block的数据。
从而显著减少因数据等待导致的SM空闲周期,使GPU执行任务的周期更加接近理想的持续计算状态。
# 初始化double buffer
buffer_K[2], buffer_V[2]
for each Q block i:
load Q_i
async_load(buffer_K[0], buffer_V[0])
for j in range(num_blocks):
curr = j % 2
next = (j + 1) % 2
# 生产者,提前加载下一块
if j + 1 < num_blocks:
async_load(buffer_K[next], buffer_V[next])
# 消费者,使用当前buffer计算
S_ij = wgmma(Q_i, buffer_K[curr])
update m_i, l_i # softmax reduce
O_i += wgmma(P_ij, buffer_V[curr])
# 只在必要时同步(避免stall)
wait_for(buffer_K[next])
write O_i
WGMMA(Warpgroup Matrix Multiply-Accumulate) 是 H100 引入的新型指令,它将一组 warp(32 个线程)组织为 warpgroup(4 个 warp,共 128 线程),并在硬件层面直接支持异步执行。V3 将
H100的第四代Tensor Core在FP8精度下的理论吞吐量是FP16的两倍(例如H100 SXM的FP8峰值约为1979 TFLOPS,而FP16为989TFLOPS)。V3原生支持FP8输入,但在注意力计算中必须解决 数值稳定性 问题,因为 softmax 对精度敏感。
因此 V3 采用混合精度策略就可以提升性能:
矩阵乘法
此外,V3 实现了 动态缩放因子 管理。由于 FP8 的表示范围有限(E4M3 约 -448 到 448,E5M2 约 -57344 到 57344),在计算
H100 的每个 SM 拥有 256KB 共享内存(比 A100 的 192KB 更大),且寄存器文件也更为充裕。V3 重新调整了分块大小
更重要的是,V3 对寄存器使用进行了精细控制,避免寄存器溢出(register spilling)到本地内存(L1缓存)。通过将中间统计量(
性能表现上计算效率和速度、长序列能力都有提升
- 计算效率:在 H100 SXM 上,使用 FP8 时,V3 的 TFLOPS 利用率可达 75%~80%,接近理论峰值。这意味着注意力计算几乎不再受内存带宽限制,而是完全由计算能力驱动。
- 速度提升:相比 V2 在 H100 上的 FP16 实现,V3 的 FP8 版本速度提升约 1.5~2 倍;即使在相同 FP16 精度下,V3 的异步优化也能带来约 1.3 倍 的加速。
- 长序列能力:在 128k 甚至 1M 长度的序列上,V3 仍能保持极高的吞吐,使得超长上下文模型的训练和推理成本大幅降低。单卡 H100 80GB 可稳定训练 256k 长度的模型。
FlashAttention V3是算法与硬件深度协同设计的典范。它通过异步WGMMA流水线解耦了数据加载与计算,利用FP8混合精度释放了H100的低精度算力,并通过精细的块布局与寄存器优化消除了内存瓶颈。这一系列改进使得注意力计算不再是Transformer长上下文扩展的阻碍,而是成为能够充分利用硬件极限的“高性能组件”。V3的诞生,直接支撑了当前工业界100k~1M上下文窗口的大语言模型的工程实现。
对于FlashAttention的发展:
- V1 解决的是IO瓶颈;
- V2 解决的是并行调度与GPU利用率问题;
- V3 解决的是计算与访存重叠(SM工作效率)问题。
一句话概括也就是,从“减少内存带宽瓶颈” → “提升并行调度与GPU利用率” → “实现计算与访存重叠,让SM始终忙碌”。

图6.26 传统KV Cache分布
在传统的KV Cache管理方式中,通常为每个请求序列预先分配一段逻辑上连续的缓存空间,用于存储其历史生成的Key/Value状态。然而,由于实际生成长度难以精确预测,这种静态预分配策略会带来显存利用率问题。当预留空间大于实际生成长度时,会产生内部碎片(internal fragmentation),即已分配但未被使用的显存空间;同时,由于不同请求的生命周期不一致,释放时间存在差异,显存中可能形成多个零散的空闲块,这个时候尽管总空闲容量充足,但由于无法提供足够大的连续缓存块来满足新序列的分配需求,从而产生外部碎片(external fragmentation)。

图6.27 显存占用分析
上述碎片问题会显著降低GPU高带宽显存(HBM)的整体利用效率。为从系统层面缓解这问刚才提到的问题,根据操作系统分页机制(paging),PageAttention将KV Cache拆分为固定大小的页面(pages),并通过页表进行间接地址映射,使逻辑连续的KV存储不再依赖物理连续内存,从而有效减少碎片并提升显存利用率。
在标准的自回归(AR)推理过程中,每个新生成的 token 都会产生对应的 K 和 V,并按时间顺序追加至 KV cache。逻辑顺序严格对应时间顺序,而物理存储顺序则取决于具体的实现策略。为了保证高效的 GPU 访问与 CUDA kernel 的访存模式(如 memory coalescing),传统实现通常将 KV cache 组织为连续内存张量,并依据预设的最大序列长度上界进行显存预分配。然而,由于不同请求的实际生成长度存在显著差异,且 GPU 显存分配器难以支持低代价的动态扩容与内存重排,这种基于最大长度的连续预分配策略容易产生内部碎片与外部碎片。
不妨通过一个例子来说明标准 AR 中连续物理内存带来的问题。假设每次请求都按最大长度 2048 个 token 预留连续的 KV cache 物理空间:
如果同时存在多个长度各异的请求,比如请求 A 实际生成 128 个 token,请求 B 生成 1024 个 token,请求 C 生成 300 个 token:
请求A:128 token
请求B:1024 token
请求C:300 token
那么问题就显现出来了。内部碎片体现在:每个请求都提前占用了 2048 长度的连续物理空间,但实际使用量远小于此,造成大量剩余空间被浪费(例如请求 C 浪费了 1700 多个 token 的容量)。外部碎片则表现为:显存中散落着许多小块空闲空间,却没有一整块连续区域能够被利用,这在 GPU 上尤为严重,导致碎片化的空闲内存无法再分配给新的请求。
vLLM 提出的 PageAttention 正是为了解决上述问题——它将“静态连续存储”转变为“动态分页管理”。 核心思路是将 KV cache 切分为固定大小的块(Page) ,例如每个 Page 包含 16 个 token 的 KV 存储。通过一个页表(Block Table),PageAttention 将逻辑上连续的 token 对应的 KV 映射到物理上未必连续的存储块中,从而最大化利用显存空间。例如,三个逻辑连续的 token 段(1–16、17–32、33–48)可以通过页表分别映射到物理地址的 Block7、Block2 和 Block19,物理上不必相邻。
为什么这样就不需要连续的物理空间呢?因为在 Attention 计算时,系统会依据页表逐块读取 KV:每处理一个 block,先查页表找到对应的物理 block,再执行读取操作。只要页表维护了正确的映射关系,即使物理地址不连续,读取的顺序逻辑依然是正确的。整个流程可以简化为:
for each block:
查页表
找到对应物理 block
读取
更重要的是,这个内存分配过程是按需动态进行的——随着请求实际生成的 token 数量增长,逐步为其分配新的 page,而非预先圈定一整块空间。
PagedAttention 将显存管理从以请求为单位的静态圈地转变为以 token 为单位的动态确权。通过物理地址的非连续映射,它彻底解决了标准 AR 中因预留最大长度而导致的严重内部碎片问题。仍以 300 tokens 的请求为例,每个 Page = 16 tokens 时:
- 所需 Page 数量为 (300 / 16 = 18.75),向上取整需要 19 个 Page。
- 实际分配的物理空间为 (19 \times 16 = 304) 个 token 容量。
- 浪费仅为 (304 - 300 = 4) 个 token。
相比之下,标准 AR 预留 2048 长度会浪费 (2048 - 300 = 1748) 个 token。vLLM 将显存浪费从 1700+ token 降至个位数,使同一块 GPU 上的并发能力(throughput)获得了数量级的提升。
用一个简单的用餐类比可以帮助理解:标准 AR 像是“按次收费的满汉全席”,不管吃多少,都必须按 2048 道菜的规模占位,吃 300 道就走,剩下 1748 道只能倒掉(显存被强占且无法复用)。而 PagedAttention 则是“按需取餐的自助餐”,每 16 个 token 是一盘菜,吃完一盘再取下一盘,空出来的餐盘可以立即让给其他用餐者(显存可动态回收复用)。
因此,传统 AR 的浪费规模为 (O(\text{max_seq_len})),而 PagedAttention 的浪费仅控制在 (O(\text{page_size})) 级别,显存利用率与并发能力由此得到显著提升。
总结来看,PageAttention 的工作原理可以概括为:
虚拟地址 -> 页表 -> 物理地址
在 vLLM 的源码层面,其映射逻辑可以表达为:
请求 ID + Token 偏移量 -> 逻辑块索引 -> Block Table 检索 -> 物理内存基址 -> 偏移读取
尽管 PageAttention 与 FlashAttention 在表面上都致力于提升大模型的推理性能,但二者的优化维度有着本质上的不同。
FlashAttention 主要聚焦于单次前向计算中的 IO 复杂度,属于算子级的微观优化。它通过分块计算(tiling)与在线 Softmax(log-sum-exp streaming)技术,避免了显式构建完整的 (QK^T) 中间矩阵,从而显著减少 HBM 与 SRAM 之间的数据往返次数,降低内存带宽压力与访问延迟。简单来说,FlashAttention 解决的是 “算得更快” 的问题。
PageAttention 则着眼于整个生成生命周期中的显存管理效率,属于系统级的宏观设计。它并不改变 Attention 的数学计算公式,而是将 KV Cache 组织为固定大小的物理块(page),并通过逻辑 block table 实现逻辑顺序与物理顺序的解耦。这种分页结构有效缓解了显存碎片问题,支持动态批处理与长上下文推理,从而提升显存利用率与并发吞吐能力。PageAttention 解决的是 “存得更高效” 的问题。
从几个关键维度来看,二者的差异更为清晰。在优化目标上,FlashAttention 专注于单次 forward 的 IO 复杂度,而 PageAttention 致力于整个生成生命周期的内存管理。在时间尺度上,前者是 micro-level(算子级)的优化,后者是 macro-level(系统级)的优化。在影响对象上,FlashAttention 作用于 attention kernel 本身,PageAttention 则管理 KV Cache 的生命周期。此外,FlashAttention 对训练和推理均有影响,而 PageAttention 基本仅适用于推理场景;FlashAttention 不依赖 decoder-only 架构,PageAttention 则对此有强依赖。
在实际的推理框架(如 vLLM)中,二者通常协同使用,以同时优化单请求延迟与整体吞吐量。但值得注意的是,PageAttention 通过间接寻址引入了 KV cache 的非连续物理布局,这可能破坏 FlashAttention 对连续内存访问与 memory coalescing 的假设。因此,在联合使用时,FlashAttention kernel 通常需要以 page 为最小 streaming 计算单元进行适配,或者确保 block_size 与 tile_size 相近,以维持共享内存利用率和访存效率。
国产GPU的性能指标已经相当可观,尤其在AI训练所需的半精度(FP16)算力上,头部产品已达到或逼近国际主流水平。更重要的是,这些算力已经在多个真实的大模型训练场景中得到验证。虽然在顶尖算力卡上国产还有一段距离要走,但是在中高端已经可以实现自给自足。目前国产GPU一直都在计算卡上发展,在民用的图形卡(电脑或者打游戏用)上并没有太大的投入。
沐曦股份是国产 GPU 领域的一支重要力量,2025 年营收已突破 16 亿元,正在从技术验证走向规模化商业落地。目前的主力产品是曦云 C 系列训推一体 GPU,同时下一代产品已在路上。
曦云产品线中,曦云 C500 系列已实现量产,作为 2025 年的主力产品,其对标英伟达 A100,定位于 AI 训练与推理。曦云 C600 系列的性能介于 A100 与 H100 之间,已于 2025 年底进入风险量产阶段,预计 2026 年上半年正式量产。而下一代旗舰曦云 C700 系列则直接对标英伟达 H100,2025 年 4 月已立项,计划在 2026 年下半年流片。
百度昆仑芯是国内最早涉足 AI 芯片领域的玩家之一,其前身是百度内部 2011 年成立的智能芯片及架构部,可以说是国产 AI 芯片的“老兵”。与华为昇腾走“系统架构弥补单点工艺”的路线、壁仞专注 GPGPU 不同,昆仑芯的差异化优势在于背靠百度的真实业务场景打磨,已在内部大规模验证后走向外部市场。
在产品层面,当前主力芯片昆仑芯 P800 已于 2024 年上市并大规模部署,采用 7nm 工艺,FP16 算力达 345 TFLOPS,是英伟达 H20 的 2.3 倍。单机 8 卡配置下,DeepSeek 一体机可提供 2 PFLOPS (FP16) 的峰值算力。面向未来,昆仑芯规划了多款新品:昆仑芯 M100 定位于大规模推理场景,强调极致性价比,将于 2026 年上市;昆仑芯 M300 面向超大规模多模态模型训练与推理,计划 2027 年推出。与此同时,天池 256 超节点和天池 512 超节点(分别支持 256 卡与 512 卡互联)均将在 2026 年面市,其中 512 卡超节点单节点即可完成万亿参数训练,整体性能提升超过 50%。
从市场出货来看,昆仑芯已站稳国产第二的位置。根据 IDC 发布的 2024 年中国加速计算芯片出货报告,英伟达以超 190 万片占据 70% 份额,华为昇腾出货 64 万片位居国产第一,昆仑芯以 6.9 万片位列国产第二,其后是天数智芯(3.8 万片)和寒武纪(2.6 万片)。
在软件栈方面,昆仑芯深度兼容主流 AI 框架。芯片预装百度飞桨 (PaddlePaddle) 框架,同时支持 TensorFlow、PyTorch 的无缝迁移,并提供“类 CUDA”编程环境,显著降低开发者的迁移成本。
在集群能力上,百度智能云今年已点亮基于昆仑芯 P800 的三万卡集群,可同时支撑多个千亿参数大模型训练,成为国产 AI 算力集群的重要里程碑。未来规划将进一步将集群规模从三万卡扩展至百万卡级别。
商业化落地方面,昆仑芯已成功从百度内部自用切入外部市场,覆盖上百家客户。运营商领域,在中国移动 2025–2026 年推理型设备集采中,昆仑芯斩获十亿级订单,三个标包均获第一;金融领域,招商银行仅需 32 台服务器即可完成千亿参数模型的全参数训练;能源、制造与科研领域也已有规模化应用,典型客户包括南方电网、吉利汽车、中国钢研、国家管网等。
海光信息是一家以 X86 CPU 起家、DCU(深度计算单元)后来居上的国产算力企业。它的独特之处在于,CPU 和 DCU 两条产品线都达到了市场主流水准,并形成了“CPU+DCU”异构协同的核心竞争力。
海光信息技术股份有限公司成立于 2014 年,2022 年 8 月在科创板上市。公司总部位于天津,专注于高端处理器的研发、设计与销售。与许多纯 AI 芯片公司不同,海光拥有两条完整的产品线:其一是基于 x86 架构的海光 CPU,主要应用于服务器与工作站,兼容庞大的 x86 生态系统;其二是基于 GPGPU 架构的海光 DCU,作为深度计算单元,专为 AI 训练与高性能计算设计。这种“双芯”布局使其既能覆盖通用计算市场,又能切入 AI 算力赛道。
海光 DCU 是其 AI 算力的核心,已完成三代产品迭代。第一代深算一号采用 7nm 工艺,FP16 算力约 90 TFLOPS,配备 32GB HBM2 显存,于 2021 年实现商用。第二代深算二号采用 7nm+ 工艺,FP16 算力提升至约 180 TFLOPS,显存容量达 512GB、带宽 1.5TB/s,2023 年发布时性能已对标 A100 的 80%–90%。当前旗舰深算三号 BW1000 采用 5nm 工艺,FP16 算力超过 400 TFLOPS,搭配 64GB HBM2e 显存,性能约为 H800 的 50%。据行业测试,BW1000 在单卡可用性能上实测达到对标产品的 87% 左右。更惊人的是,在 CAE 仿真场景中,256 块 DCU 的并行计算速度超过 4116 节点、13 万 CPU 核,取得了不小于 700 倍的加速效果。
海光 DCU 的软件策略非常务实——兼容现有生态,降低迁移成本。DCU 采用 GPGPU 架构,兼容“类 CUDA”编程环境,支持 PyTorch、TensorFlow 等主流 AI 框架,目前已集成超过 2000 个算子,对标 CUDA 的算子覆盖度超过 99%。自研的 DCU Toolkit 支持 HIP 接口转换,可将 CUDA 代码迁移至海光平台,迁移成本降低 70% 以上。同时,海光 DCU 已与国内外主流大模型全面适配,DeepSeek 新模型发布当天即可实现无缝适配与深度调优。
海光 DCU 已在多个关键行业实现规模化落地。在金融领域,某全国性股份行采用海光 DCU 进行 AI 信创改造与智能文档解析,OCR 识别效果达到英伟达同等水平,已部署于信贷审核、尽调分析等场景;中科金财基于海光 DCU 构建的 AI 风控系统,可实现实时交易分析延迟低于 10ms,较 CPU 方案提速 15 倍。在科研领域,信息高铁平台率先上线 BW1000 算力集群,支撑了 50 余个行业大模型的研发。在航空领域,紫光恒越交付了搭载“海光四号 CPU + BW1000 GPU”的一体机,实现了航空领域首单落地。在智能制造方面,澎峰科技利用海光 DCU 进行工业缺陷检测,单卡可并行处理 32 路 4K 视频流,检测精度达到 99.5%。
天数智芯是国内首家实现通用 GPU 量产的企业,产品已覆盖“云、边、端”全场景,累计出货量突破 5.2 万片。
天数智芯目前拥有三大产品系列,覆盖云端训练、云端推理和边端算力场景。
天垓系列主打 AI 训练,其中天垓 100 是国内首款量产训练 GPU,采用 7nm 制程,集成 240 亿晶体管,2.5D CoWoS 封装,板级功耗 250W,支持 FP32、FP16、BF16、INT8 等多精度算力,FP16 算力 147 TFLOPS,配备 32GB HBM2 显存,售价约 5 万元。天垓 150 作为性能升级版,FP16 算力提升至 192 TFLOPS,显存翻倍至 64GB HBM2,售价约 9 万元。从算力水平看,天垓 100 约为英伟达 A100(312 TFLOPS)的 47%,天垓 150 则进一步逼近。
智铠系列定位于 AI 推理,主打高性价比与低功耗。智铠 50 板级功耗仅 75W,INT8 算力 192 TOPS,配备 16GB HBM2e 显存,售价约 1.5 万元。智铠 100 是系列主力产品,INT8 算力达 384 TOPS,峰值带宽 800GB/s,支持 128 路视频解码,配备 32GB HBM2e 显存,售价约 2.3 万元,支持 FP32、FP16、INT8 等多精度计算。智铠 150 则提供 300 TOPS 的 INT8 算力,配备 32GB HBM2e 显存,售价约 3 万元。
彤央系列面向边端算力场景,于 2026 年 1 月发布,包含 TY1000 至 TY1200 型号,实测稠密算力覆盖 100 至 300 TOPS,性能超越英伟达 AGX Orin,售价暂未公开。
截至 2026 年 1 月上市披露,天垓系列产品累计交付超 5.2 万片,其中 2025 年上半年出货 1.57 万片,同比增长 2.3 倍。从产品线看,训练卡(天垓系列)年出货量接近 2 万颗,而推理卡(智铠系列)增长迅猛,2026 年预计营收占比将超过 70%,成为增长主力。
公司 2024 年营收超过 6 亿元,2026 年目标锁定 10 亿元。2026 年 1 月 8 日,天数智芯在港交所上市(股票代码:9903.HK),开盘上涨 31.54%。
目前公司已服务超 300 家客户,完成超 1000 次部署应用。主要客户涵盖计算中心、运营商、四大行、中国人寿以及瑞幸咖啡(数千家门店)等,同时在 20 个车路协同试点城市实现落地。
摩尔线程是中国首家推出全功能 GPU 并实现量产的公司。2025 年 12 月,公司在科创板上市,被称为“国产 GPU 第一股”,目前市值已超过 2800 亿元。其创始人兼 CEO 张建中曾担任英伟达全球副总裁,拥有 15 年的 GPU 行业经验。
摩尔线程的主力产品是 MTT S5000 旗舰级 AI 训推一体智算卡,于 2024 年推出,近期首次公开了详细参数。在关键算力上,S5000 的 FP8 算力达到 1000 TFLOPS,迈入 PFLOPS 级别,首次摸到国际顶尖门槛。显存规格为 80GB HBM2e,带宽 1.6TB/s,与英伟达 H100 相当。卡间互联带宽达到 784GB/s,可支持万卡集群高效协同。在计算精度方面,S5000 支持从 FP8 到 FP64 的全精度计算,是国内最早原生支持 FP8 的训练 GPU 之一。
从实测表现看,智源研究院基于 S5000 千卡集群训练具身大脑模型 RoboBrain 2.5,训练损失值与 H100 集群的差异仅为 0.62%,整体训练效果甚至实现小幅超越。在互联网厂商的端到端任务测试中,S5000 性能约为英伟达 H20 的 2.5 倍,单卡 Prefill 吞吐超过 4000 tokens/s,Decode 吞吐超过 1000 tokens/s,刷新了国产 GPU 的推理纪录。
摩尔线程保持每年一代架构迭代的节奏,2025 年已推出第五代“花港”架构,算力密度提升 50%、能效比提升 10 倍。基于该架构的“华山”(AI 训推)和“庐山”(图形渲染)芯片预计 2026 年面市。
2025 年,摩尔线程实现营收 15 亿元,同比增长超过 2 倍,净亏损约 10.7 亿元,同比收窄 37%,亏损趋势明显改善。公司综合毛利率达到 70.71%,已超过海光信息、寒武纪等同行,管理层预计最早 2027 年实现盈利。
与专注 AI 训练的厂商不同,摩尔线程走的是 “全功能 GPU”路线,单芯片可同时支持 AI 计算、图形渲染、物理仿真和科学计算。其核心技术是自研的 MUSA(元计算统一架构),具备与 CUDA 生态的兼容性,开发者可以较低成本迁移现有代码。目前,TileLang 原生算子单元测试覆盖率已超过 80%,显著降低了移植成本。开发者社区规模接近 20 万人,并已进入全国 200 多所高校。
阿里平头哥是阿里巴巴旗下的芯片设计公司,也是目前国产 AI 芯片阵营中累计出货量领先的玩家之一。它的核心特点是“自研自用 + 对外输出”,不仅支撑着阿里云和通义千问大模型,也向 400 多家外部企业提供算力。
平头哥的产品矩阵覆盖了从 AI 训练与推理、通用计算到存储与物联网等多个领域。在 AI 算力方面,真武 PPU 是当前主力芯片,定位于 AI 训推一体,主要用于大模型训练与推理、自动驾驶等场景,性能对标英伟达 H20,已在阿里云内部署多个万卡集群。含光 800 是平头哥首款自研 AI 推理芯片,2019 年发布时曾为全球性能最强的 AI 推理芯片之一,主要用于搜索推荐、图像识别等场景。
在通用计算与存储领域,倚天 710 是一款基于 ARM 架构的服务器 CPU,采用 5nm 工艺,是业界性能最强的 ARM 服务器芯片之一,主要服务于阿里云数据中心。镇岳 510 则是企业级 SSD 主控芯片,用于自研存储控制,可对冲存储芯片涨价风险。
在物联网与边缘侧,羽阵系列 RFID 芯片已应用于麦当劳等场景,累计出货数亿颗;玄铁系列 RISC-V 处理器 IP 则面向边缘计算与 IoT 设备,依托开源生态,累计授权已超过 45 亿颗。
真武 PPU 是平头哥当前最受关注的 AI 芯片,也是其市场地位的核心支撑。该芯片配备 96GB HBM2e 显存,片间互联带宽达到 700 GB/s,采用 PCIe 5.0 ×16 接口,功耗为 400W。整体性能超过英伟达 A800 和主流国产 GPU,与英伟达 H20 相当,并且针对 Transformer 架构做了专门优化,性价比优势明显。目前,真武 PPU 已在阿里云建成多个万卡集群,全面支撑 通义千问(Qwen) 大模型的训练与推理。
根据平头哥官方 2026 年 3 月披露的数据,截至 2026 年 2 月,AI 芯片累计规模化交付 47 万片,其中 60% 以上服务于外部商业化客户,已支持 400 多家企业客户的 AI 任务。而按照第三方机构 IDC 在 2026 年 Q1 发布的口径,平头哥累计出货量已突破 60 万片,在国产 AI 芯片厂商中跃居第二,仅次于华为昇腾。
从客户构成看,平头哥既服务阿里自身(通义千问)、新浪微博等互联网企业,也覆盖了多家头部金融机构(用于风控模型训练)、国家电网、中科院,以及小鹏汽车等自动驾驶企业(用于算法迭代)。
华为昇腾(Ascend)系列是华为自研的 AI 处理器,采用达芬奇(DaVinci)架构,属于 NPU 类型,是目前国内落地规模最大、生态最成熟的 AI 算力解决方案。
从产品线来看,昇腾系列覆盖了从边缘到云端的全场景。昇腾 310 采用 12nm 工艺,功耗仅 8W,FP16 算力为 8 TFLOPS,主要用于安防、工业检测等边缘推理与低功耗终端场景。昇腾 610 面向智能驾驶,采用 7nm 制程,FP16 算力达 100 TFLOPS,应用于华为 MDC 智能驾驶平台。在云端 AI 训练与推理领域,昇腾 910B 是当前主力型号,采用 7nm 工艺,FP16 算力约为 280–320 TFLOPS,对标英伟达 A100,已实现大规模部署。昇腾 910C 作为当前旗舰产品,采用双 die 封装,FP16 算力约 800 TFLOPS,能效比优于 H100。
面向未来,昇腾也公布了清晰的路线图。昇腾 950PR/DT 已于 2026 年推出,作为新一代推理与训练芯片,首发搭载华为自研 HBM 内存,并升级了 SIMT 架构,FP8 算力达到 1 PFLOPS。规划中的昇腾 960 旗舰训练芯片将支持自研 HiF4 格式,FP8 算力提升至 2 PFLOPS,较 950 系列翻倍。而昇腾 970 作为下一代训练芯片,FP8 算力预计达到 4 PFLOPS,计划于 2028 年推出。
在一些算力平台如 AutoDL 上,用户可以租到 910B 搭配鲲鹏 920 的算力实例。根据 AutoDL 平台的性能实测数据(见下图),昇腾 910B 在实际应用中的表现可直观对比英伟达 A100。


昇腾的软件生态依托 CANN(异构计算架构),相当于英伟达的 CUDA,目前已全面开源开放,提供从算子开发到模型调优的全栈工具。在框架兼容性上,PyTorch 2.1 版本已原生支持昇腾,开发者可直接通过 pip install 安装使用,无需复杂适配。同时,昇腾也兼容 TensorFlow、飞桨(PaddlePaddle)及华为自研的 MindSpore 框架。值得一提的是,HuggingFace 社区的 Transformers 库已原生支持昇腾,下载模型后即可直接运行。昇腾社区的 ModelZoo 2.0 也提供了数百个预训练模型,进一步降低了开发门槛。
昇腾的出货量增长迅猛,市场地位持续攀升。根据 IDC 的数据,2024 年华为昇腾出货量达 64 万片,在国内 AI 芯片市场中成为唯一能与英伟达抗衡的本土厂商。瑞穗证券预测 2025 年出货量将超过 70 万颗,显示出在外部制裁下的强劲需求与生产韧性。进入 2026 年,行业普遍预测总体出货量在 80 万至 85 万片之间,而根据星岛环球网与彭博社的报道,华为内部生产计划目标更为进取,计划将昇腾产品线的总产量(晶圆级)提升至 160 万颗,其中旗舰款 910C 的目标产量为 60 万片,约为 2025 年的两倍。
出货量增长的背后,是昇腾在中国 AI 芯片市场地位的跃升。根据知名研究机构伯恩斯坦(Bernstein Research) 的预测,2026 年中国 AI 芯片市场格局将发生根本性逆转:华为昇腾的市场份额预计将大幅增长至 50%,成为中国市场的绝对领导者;而受美国制裁政策影响,英伟达的份额则可能从 2025 年的高位急剧萎缩至 8%。
现在我们最有可能接触到的是华为的昇腾系列卡,这里放一个友方链接: 它收录了在Ascend NPU平台上经过测试和验证的大语言模型部署教程,供有需求的朋友进行学习。