public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {}ArrayBlockingQueue는 BlockingQueue를 구현하고 있는 클래스입니다. BlockingQueue에 대해서는 여기 에서 확인하고 오시면 됩니다.
간단하게 정리하자면 BlockingQueue는 한쪽에서 put이 일어나고, 다른 한쪽에서 take()가 일어납니다. 여기서 중요한 점은 큐가 꽉 차있는데 put()을 진행하게 되면 take() 작업이 발생할 때 까지 기다리게 됩니다.
반대로 take() 과정이 일어났을 때 큐가 비어있다면 put() 과정이 일어날 때 까지 대기하게 됩니다.
이러한 특징은 ArrayBlockingQueue에도 적용이 됩니다. 그리고 이름에서 알 수 있듯이 Array를 사용해서 구현되어 있습니다.
ArrayBlockingQueue는 Head는 가장 오래된 원소가 들어 있고, Tail에는 가장 최근에 들어온 원소들이 존재합니다.
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
}ArrayBlockingQueue의 생성자는 위와 같습니다. 객체를 만들 때 무조건 초기 용량을 정해야 하며 초기 용량은 변하지 않습니다. 그리고 boolean fair는 false인 경우에는 lock을 스케쥴러에 의해서 예측할 수 없게 주어지지만,
true로 했을 경우에는 lock을 오래 기다린 쓰레드에게 먼저 줄 수 있게 공평하게 처리를 합니다.
일반적으로 Queue는 ArrayList가 아니라 LinkedList를 사용하여 구현을 합니다. 그 이유는 큐는 앞에서 삭제가 일어나는데, ArrayList의 경우는 빈 공간을 계속 메꾸기 위한 오버헤드가 발생하기 때문에 사용하지 않는 것입니다.
그런데 ArrayBlockingQueue는 Array를 사용합니다. 이유가 무엇일까요?
일단 ArrayBlockingQueue는 용량이 한번 정해지면 고정이라는 특징이 있습니다.
위에서 말했던 것처럼 ArrayBlockingQueue는 객체를 생성할 때 초기용량을 지정해주어야 합니다.
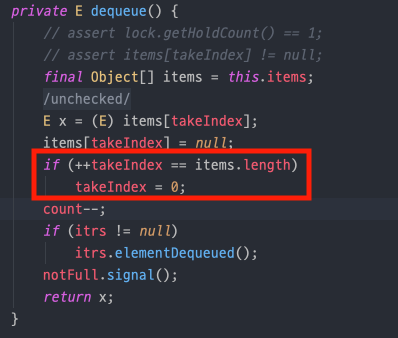
그리고 ArrayBlockingQueue의 dequeue 메소드를 보면 위와 같이 원소들의 자리 이동 과정이 일어나지 않습니다. 즉, 삭제한 원소는 null 처리를 하고 takeIndex로 배열을 관리하게 됩니다.
그래서 배열을 사용하여도 ArrayList 처럼 큰 오버헤드가 발생하지 않습니다.
-
- 공간을 미리 할당해놓기 때문에 삽입, 삭제를 비교적 적은 비용으로 할 수 있습니다.
- 공간을 미리 할당해놓기 때문에 사용하지 않는다면 메모리 낭비가 될 것입니다.
- ArrayList처럼 용량을 늘리는 작업을 하지 않습니다. (즉, 원소들의 자리 이동이 일어나지 않습니다.)
-
- 삽입을 할 때마다 노드 객체를 새로 만들어야 하는 비용이 듭니다.(배열보다는 더 많은 비용이 듭니다.)
- 삭제를 하는데도 배열보다는 비용이 더 많이 든다는 단점이 있습니다.(ArrayBlockingQueue는 원소들의 자리 이동이 없기 때문에)