本章將會讀取 SOF0 跟 SOS。
SOF0 會提供讀取 SOS 的必要資訊, SOS 所儲存的是整個 JPEG 檔案的主體,被變換、壓縮過後的圖像數據。
| 區段 | 進度 |
|---|---|
| DQT | ✅ |
| DHT | ✅ |
| SOF0 | ✅ |
| SOS | ✅ |
| 壓縮圖像數據 | ✅ |
我們在第一章簡介 JPEG 的各種算法時,有提到 sequential 算法會由上往下解碼,當只從伺服器接收到部分數據時,就開始解碼了,邊收數據邊解碼,解碼到哪顯示到哪,在網速慢的時候會有比較好的使用者體驗。
從這個特性中我們可以聯想到, JPEG 圖檔必然是分塊進行壓縮的,因爲它不需要知道所有的數據就已經可以開始解碼。
下方是圖示:
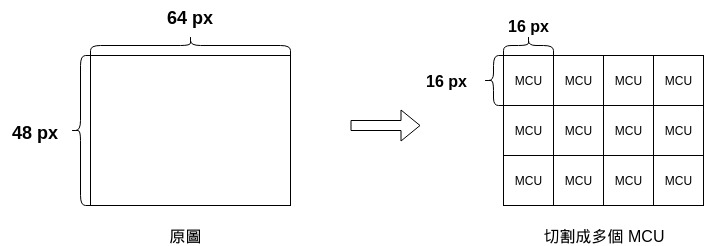
一張圖片在壓縮時會被切割成多塊 MCU , MCU 是 Minimum Coded Unit 的縮寫,意思是最小編碼單元。
但注意,MCU 的寬、高並不固定爲 16 px,甚至未必是正方形,而是取決於顏色分量的採樣率。
在附錄一中提到 JPEG 圖檔儲存的是 YCbCr 色彩空間,我們稱 Y, Cb, Cr 三個部分爲顏色分量,這三個顏色分量的採樣率並不相同,人眼對亮度敏感,對色度不敏感,因此通常不會去降採樣代表亮度的 Y ,而僅僅降採樣 Cb, Cr 。
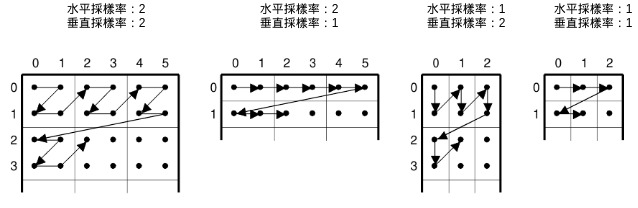
我們用下面這幾張圖來解釋何謂採樣率、以及它如何影響 MCU 的組成。
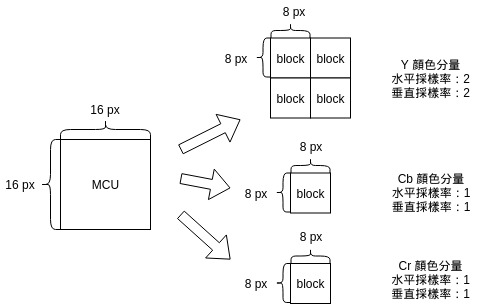
這張圖片的 Y 顏色分量的水平、垂直採樣率爲 2 , Cb, Cr 顏色分量的水平、垂直採樣率爲 1 。
每個顏色分量的最基本單元是 block ,一個 block 的寬、高固定爲 8 * 8。
MCU 的寬 = 8 * 最高水平採樣率
MCU 的高 = 8 * 最高垂直採樣率
用虛擬碼表示:
# horizontal sampling(水平採樣率) 縮寫爲 hs
# vertical sampling(垂直採樣率) 縮寫爲 vs
MCU.width = 8 * max(Y.hs, Cb.hs, Cr.hs)
MCU.height = 8 * max(Y.vs, Cb.vs, Cr.vs)
因此上圖的 MCU 的寬、高皆爲 8 * max(2, 1, 1) = 16 。
注意到,這這個例子中,我們僅僅用 6 個 block 就描述了 16 * 16 px 的 MCU ,假如我們不降採樣,需要用 12 個 block 才能描述,也就是說我們透過降採樣壓縮了一半的數據量。
如果把 Y 的 水平、垂直採樣率改爲 1 ,MCU 的寬、高爲 8 * max(1, 1, 1) = 8 。圖示如下:
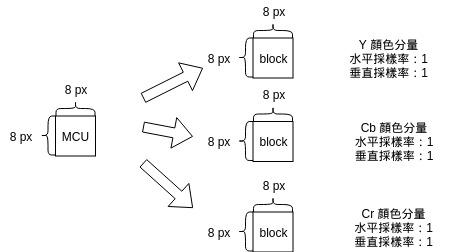
雖然我們在本章還不用知道這個問題的答案,但是看到每個分量的大小不同,很自然就會產生這個疑問吧?
所有採樣率都爲 1 的時候,MCU 跟各個顏色分量都是 8 * 8 的正方形,直接一一對應即可。
但是在第一張圖中的例子,MCU 有 16 * 16 ,Cb, Cr 都只有 8 * 8 ,那要如何對應呢?
按照採樣率來對應,例如下圖, Cb, Cr 的最左上角對應到了 MCU 的左上四個 px :
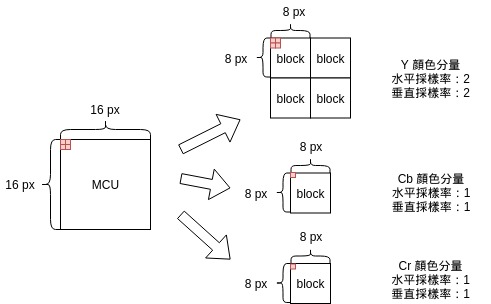
用虛擬碼表示會更清晰:
# 欲計算 MCU[i][j].Cb ,也就是 MCU 的第 i, j 個像素的 Cb 分量數值。
# Cb 儲存 Cb 顏色分量的數值
# horizontal sampling(水平採樣率) 縮寫爲 hs
# vertical sampling(垂直採樣率) 縮寫爲 vs
max_hs = max(Y.hs, Cb.hs, Cr.hs)
max_vs = max(Y.vs, Cb.vs, Cr.vs)
# 計算 i, j 縮小到 Cb 的大小時,應該索引爲多少
# 注意此處的除號 "/" 都會捨去到整數
new_i = i * Cb.vs / max_vs
new_j = j * Cb.hs / max_hs
# Cb 是一個四階陣列
# 前兩階描述 block 的位置,後兩階描述要擷取的是這 8*8 中的哪一個點
MCU[i][j].Cb = Cb[new_i / 8][new_j / 8][new_i % 8][new_j % 8]
# Y, Cr 的算法跟 Cb 完全相同,省略之
SOF0 區段記錄了圖片寬、高,以及各個顏色分量的資訊,有了這些數據,我們才能夠開始讀取本章的重頭戲—— SOS 段中的壓縮圖像數據,SOF0 段詳見下表:
| 代號 | 大小 | 描述 | 備註 |
|---|---|---|---|
| ① | 1 byte | 精度 | baseline 流程的精度固定爲 8 ,也就是說用 1 byte 來存取色彩空間的數值即可 |
| ② | 2 bytes | 圖片高度 | |
| ③ | 2 bytes | 圖片寬度 | |
| ④ | 1 byte | 有幾個顏色分量 | JFIF 規定顏色空間爲 YCbCr 因此顏色分量數量固定爲 3 |
| ⑤ | 9 bytes | 各個顏色分量的詳細資訊 | 見下一張表 |
上表中的 ⑤ ,爲下表重複 3 次,分別描述 3 個顏色分量的資訊:
| 代號 | 大小 | 描述 | 備註 |
|---|---|---|---|
| ① | 1 byte | 顏色分量 id | 1 表示 Y , 2 表示 Cb , 3 表示 Cr |
| ② | 1 byte | 採樣率 | 高 4 bit 代表水平採樣率 ,低 4 bit 代表垂直採樣率。採樣率可以是 1, 2, 3, 4 |
| ③ | 1 byte | 量化表 id | 最後解碼時,要選擇哪一個量化表對該顏色分量進行量化(量化表在第二章介紹過) |
上述採樣率的限制告訴我們,一個 MCU 的寬跟高最多爲 8 * 4 = 32 。
在真正讀取壓縮數據之前,我們要先知道這些數據是根據哪個霍夫曼表進行編碼的, SOS 區段詳細如下:
| 代號 | 大小 | 描述 | 備註 |
|---|---|---|---|
| ① | 1 byte | 有幾個顏色分量 | |
| ② | 2 * 3 bytes | 顏色分量對應的霍夫曼表 | 每個顏色分量佔用 2 bytes , 見下一張表 |
| ③ | 3 bytes | baseline 流程用不到 | 在 baseline 流程固定爲 0x003F00 |
② 的內容爲下表重複 3 次:
| 代號 | 大小 | 描述 | 備註 |
|---|---|---|---|
| ① | 1 byte | 顏色分量 id | 1 表示 Y,2 表示 Cb,3 表示 Cr |
| ② | 1 byte | 對應的霍夫曼表 id | 高 4 bit 代表直流(DC)霍夫曼表,低 4 bit 代表交流(AC)霍夫曼表 |
上表讀完之後,緊接著的就是壓縮圖像數據流,把數據流切割來看,可以看成一個接一個的 MCU 串:
[MCU1], [MCU2], [MCU3], [MCU4], ....
而一個 MCU 又可以進一步切割成(假設 Y 水平、垂直採樣率爲 2 ,Cb, Cr 水平、垂直採樣率爲 1)不同顏色分量的串連,以 Y -> Cb -> Cr 的順序:
[Y1, Y2, Y3, Y4, Cb1, Cr1]
這裏的 Y1, Y2, .... Cr1 ,都是一個 8 * 8 的 block 了,所以之後我們只要瞭解一個 block 如何讀取,就大功告成了。
注意,如同在第二章所提到的,爲了與標記碼做區別,在讀取壓縮圖像數據時,若讀取到一個 byte 爲 0xFF ,則後面會緊接一個 0x00 的 byte,但這個 0x00 的 byte 不是數據,必須忽略。
由左到右,再由上到下,圖示:
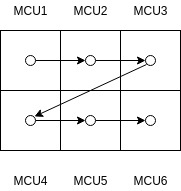
一樣是由左到右,再由上到下,我直接截張標準書的圖:
假如現在 MCU 的寬、高都是 16px ,但是整張圖像的寬、高爲 40, 60 ,MCU 無法整除圖像,怎麽辦?
數量多到剛好可以覆蓋圖像即可,在上面的例子裡
- 該圖像的每條橫列有 3 個 MCU (16 * 3 > 40)
- 該圖像的每條直列有 4 個 MCU (16 * 4 > 60)
本文跟範例程式碼都不特別處理邊界的問題,肉眼並不容易發現。
用虛擬碼來表示讀取壓縮圖像數據的過程:
# 以下虛擬碼中 for i in a..b 語法表示 i 從 a 迭代到 b - 1
function read_compressed_data() {
for i in 0..直列上MCU個數 {
for j in 0..橫列上MCU個數 {
read_MCU()
}
}
}
function read_MCU() {
for component in [Y, Cb, Cr] {
for i in 0..component.vertical_sampling {
for j in 0..component.horizontal_sampling {
read_block()
}
}
}
}
function read_block() {
// 每個 block 的寬、高都爲 8 * 8
for i in 0..8 {
for j in 0..8 {
read_value() # 直流與交流的讀取方式不同
}
}
}
前面講解了 block 的讀取順序,現在來講解要如何讀取一個 block。
我們在 SOS 段中知曉了每個顏色分量對應的直流跟交流霍夫曼表。但什麼是直流,什麼又是交流呢?
很簡單,每個 block 都是 8 * 8 ,最左上角的數值就是直流係數,要使用直流霍夫曼表來解碼;而餘下的 63 個數值是交流係數,使用交流霍夫曼表來解碼。
那爲什麼要取名叫做直流、交流?這跟 DCT 變換有關,請看(附錄一)理論基礎。
讀取 block ,其實就是讀取 block 中的 64 個數值,順序一樣是由左到右,再由上往下,就不再畫圖了。
讀取一個 block 的具體流程爲:
- 讀取直流係數:
- 不斷從數據流中讀取一個 bit ,直到可以對上直流霍夫曼表中的一個碼字,取出的對應信源編碼代表的是接下來還要讀入幾位,假如是 n 就繼續讀取 n bits ,以下表解碼後,就是直流係數。
- 讀取交流係數
- 再接着取出 bit 直到對上交流霍夫曼表的一個碼字,取出對應信源編碼。
- 這個信源編碼代表的意義爲
- 高 4 bits 代表接下來的數值連續有幾個 0
- 低 4 bits 代表這些 0 之後跟著的數值的位數,假如是 n 就繼續讀取 n bits ,以下表解碼後,就是這些 0 之後跟着的數值。
- 有兩個特殊的信源編碼,含義與上述不同
- 0x00 代表接下來所有的交流係數全爲 0
- 0xF0 代表接下來有 16 個 0
- 當以下兩種狀況發生時,代表交流係數已經讀取完畢
- 63 個交流編碼都已經讀完
- 讀到 0x00 ,直到剩下的交流係數全爲 0
| 實際數值 | 位數 | 碼字 |
|---|---|---|
| -1,1 | 1 | 0,1 |
| -3,-2,2,3 | 2 | 00,01,10,11 |
| -7,-6,-5,-4,4,5,6,7 | 3 | 000,001,010,011,100,101,110,111 |
| -15,……,-8,8,……,15 | 4 | 0000,……,0111,1000,……,1111 |
| -31,……,-16,16,……,31 | 5 | 00000,……,01111,10000,……,11111 |
| -(2^n -1),……-2^(n - 1),2^(n - 1),……2^n - 1 | n <= 11 | 所有長度爲 n 的二進位 |
稍微觀察一下,應該很容易看出規律,正數就是照一般二進位計算,負數就是對正數的碼字取反而已,有點一補數的意思:
剛看到這個讀取方式時,覺得有兩點奇怪:
-
爲什麼要先讀取接下來有幾位,再透過上面那張表來讀真正的值?爲什麼不直接從霍夫曼表中讀出真正的值?
我沒有查閱到這個問題的直接答案,但是有一些猜想,請見附錄一。
-
爲什麼交流霍夫曼表的信源編碼代表的是前綴的 0 的數量?
一個簡單的解釋是,block 被量化之後裏面實在太多 0 了,所以對 0 的數量編碼反而更省空間。
我們剛剛讀取到的直流係數,其實只是前一個 block 中的直流係數跟這一個 block 的直流係數的差而已。
在編碼時,會計算出兩個 block 之間的差,然後只儲存這個差,也就是說若
DC[n] = DC[n - 1] + diff
在第 n 個 block 中,第一個讀取的數值就是這個 diff ,當然,在第 0 個 block ,直接讀取就是了。
注意到,三個顏色分量是分開來做差分的,以上 block 的順序,就按照一個顏色分量讀取 block 的順序來排列。
分開做差分是非常合理的,差分的作用在於,當好幾個數值有一定的連續性,也就是說連續的幾個數值之間的差距很小,我們就可以用較少的編碼量來儲存這個差,譬如說 10000, 10001, 10003, 9999 這個數列,可以儲存爲 10000, 1, 2, -4 即可,1, 2, -4 因爲數值很小,可以用很少的編碼來儲存。
但是這個假設在跨越顏色分量的時候就不成立了,一張圖片的局部,通常亮度不會有非常急劇的變化,但如果有張圖片的亮度高,色度低,跨顏色分量的差在整張圖片中都會非常大,完全失去差分編碼的壓縮作用。
這份資料的第 3 頁結尾開始看,有一個很詳細的例子,就不再複述了。
如果你已經成功讀取壓縮圖像數據,那恭喜你,最困難的關卡已經過去,剩下大約 50 行程式碼的功夫,就能將將圖片解碼完成了。