We came up with two possible structures for the open-MaStR:
Version 1:
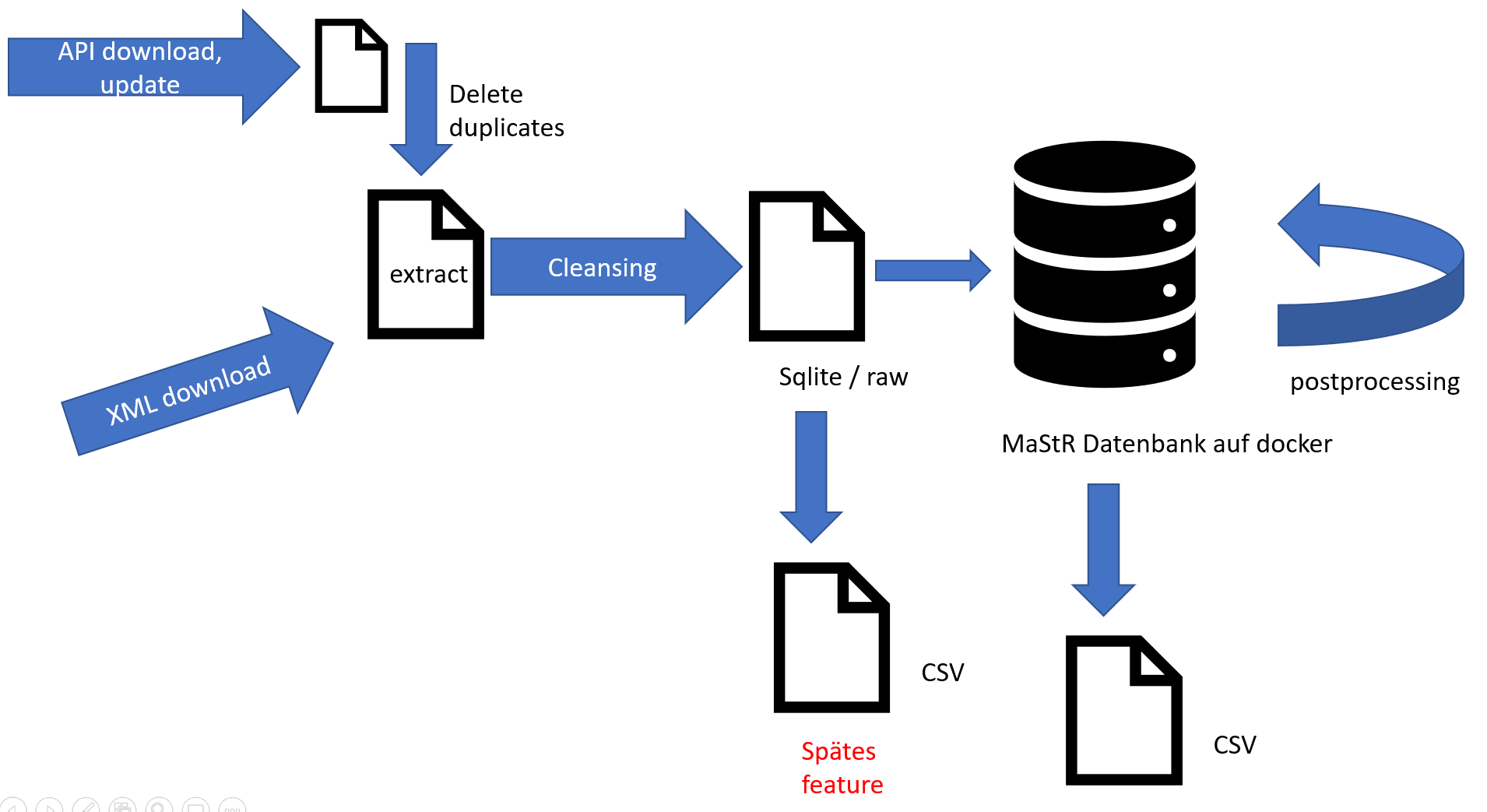
Data from the MaStR can either be downloaded by API or by the full data XML dump. Data from both sources should be formatted the same as early as possible, in the socalled extract file. From there on, the same process happens with both downloads: the data is cleansed, meaning that obvious errors are removed. This results in the raw file, which is in sqlite format. This is then read into the docker MaStR database. Different modular functions take the database from docker and do different kinds of preprocessing.
Version 2:

Here, the download from the API / the XML files are written into the docker database as soon as possible into tables with the ending _raw. Different cleansing functions start automatically to change this raw data. The user can then decide whether to run different postprocessing functions, which will generate new tables in the database with the ending _cleaned.
Right now, we tend to implement version 2.
We came up with two possible structures for the open-MaStR:

Version 1:
Data from the MaStR can either be downloaded by API or by the full data XML dump. Data from both sources should be formatted the same as early as possible, in the socalled extract file. From there on, the same process happens with both downloads: the data is cleansed, meaning that obvious errors are removed. This results in the raw file, which is in sqlite format. This is then read into the docker MaStR database. Different modular functions take the database from docker and do different kinds of preprocessing.
Version 2:

Here, the download from the API / the XML files are written into the docker database as soon as possible into tables with the ending _raw. Different cleansing functions start automatically to change this raw data. The user can then decide whether to run different postprocessing functions, which will generate new tables in the database with the ending _cleaned.
Right now, we tend to implement version 2.