Package Stats 📊



Package Build (Tests/Doc Creation/PyPi Releases) 👌
![]()

![]()
Paper 📜 (Click here!)
Documentation 📋 (Click here!)
If you use Plurals in your research, please cite the following paper appearing at CHI 25 (Honorable Mention):
Bibtex:
@inproceedings{ashkinaze2025plurals,
author = {Ashkinaze, Joshua and Fry, Emily and Edara, Narendra and Gilbert, Eric and Budak, Ceren},
title = {Plurals: A System for Guiding LLMs Via Simulated Social Ensembles},
booktitle = {CHI Conference on Human Factors in Computing Systems},
series = {CHI '25},
year = {2025},
month = may,
location = {Yokohama, Japan},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
pages = {1--27},
numpages = {27},
doi = {10.1145/3706598.3713675},
url = {https://doi.org/10.1145/3706598.3713675}
}
APA:
Ashkinaze, J., Fry, E., Edara, N., Gilbert, E., & Budak, C. (2025). Plurals: A system for guiding LLMs via simulated social ensembles. In CHI Conference on Human Factors in Computing Systems (CHI '25, pp. 1-27). Association for Computing Machinery. https://doi.org/10.1145/3706598.3713675
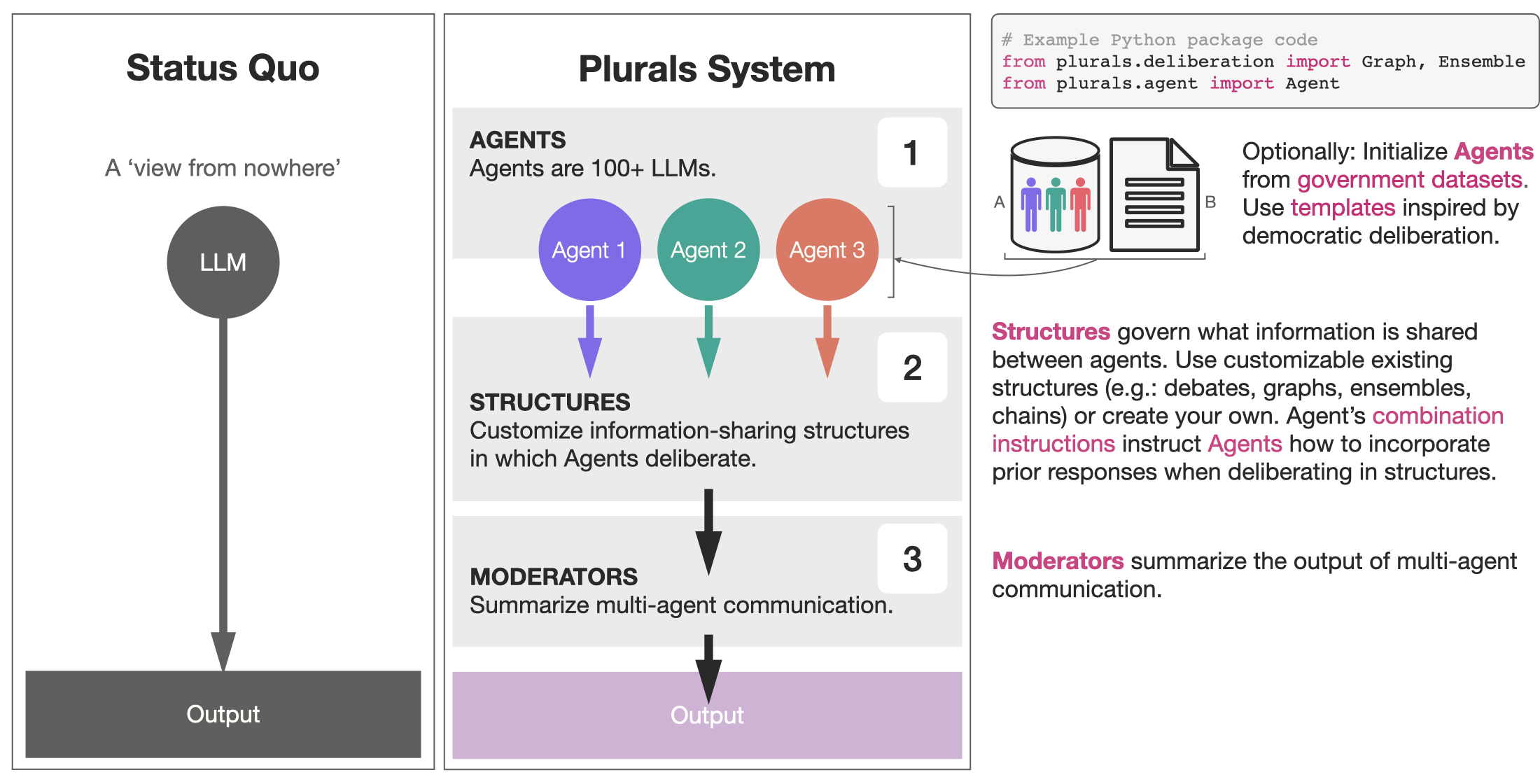
Plurals is an end-to-end generator of simulated social ensembles. (1) Agents complete tasks within (2) Structures, with communication optionally summarized by (3) Moderators. Plurals integrates with government datasets (1a) and templates, some inspired by democratic deliberation theory (1b).
The building block is Agents, which are large language models (LLMs) that have system instructions and tasks. System instructions can be generated from user input, government datasets (American National Election Studies; ANES), or persona templates. Agents exist within Structures, which define what information is shared. Combination instructions tell Agents how to combine the responses of other Agents when deliberating in the Structure. Users can customize an Agent's combination instructions or use existing templates drawn from deliberation literature and beyond. Moderators aggregate responses from multi-agent deliberation.
Plurals includes support for multiple information-sharing structures (e.g., chains, graphs, debates, ensembles) and templates for customizing LLM deliberation within these.
- 📖 Early version of the paper appeared in the NeurIPS Pluralistic Alignment Workshop and International Conference on Computational Social Science (resource nomination 🏆, research impact nomination 🏆)
- 🏆 Paper appeared at CHI 2025 with Honorable Mention!
- 📖 Tutorial given at ICWSM
- 🔧 Improvement: Changes to debate to decrease sycophancy
- ✨ Feature update: Names of Agents in DAG are now visible to other Agents
- ✨ Feature update: Added a best-of-n feature for Agents. This supports things like verifiable rewards and LLM-as-a-Judge. Best-of-n can be used inside of Structures, where different Agents have different optimizing objectives. See the tutorial for details.
- ✨ Feature update: Added
Interviewclass for building rich, story-based personas via simulated interviews, inspired by 1. Agents can also automatically generate task-specific interview questions (returned as structured JSON), which are then used to conduct targeted interviews. See the tutorial for details. - ⚡ Performance improvement: Best-of-N generation is now parallelized.
- 🔧 Improvement: Added methods for exporting and viewing structures —
structure.to_dataframe(),structure.to_json(),structure.print_responses()— which make it much easier to inspect what's happening internally. The structure tutorial now documents these features (see this section). - 🔧 Improvement: Structures now support TQDM progress bars. When initializing a structure, just add
verbose=True.
https://josh-ashkinaze.github.io/plurals/
pip install pluralsimport os
os.environ["OPENAI_API_KEY"] = 'your_openai_key'
os.environ["ANTHROPIC_API_KEY"] = 'your_anthropic_key'See the tutorial for more details on how to build and customize structures.

from plurals.agent import Agent
from plurals.deliberation import Graph, Moderator
story_prompt = """
Craft a mystery story set in 1920s Paris.
The story should revolve around the theft of a famous artwork from the Louvre.
"""
agents = {
'plot': Agent(
system_instructions="You are a bestselling author specializing in mystery plots",
model="gpt-4o",
combination_instructions="Develop the plot based on character and setting inputs: <start>${previous_responses}</end>"
),
'character': Agent(
system_instructions="You are a character development expert with a background in psychology",
model="gpt-4o",
combination_instructions="Create compelling characters that fit the plot and setting: <start>${previous_responses}</end>"
),
'setting': Agent(
system_instructions="You are a world-building expert with a focus on historical accuracy",
model="gpt-4o",
combination_instructions="Design a rich, historically accurate setting that enhances the plot: <start>${previous_responses}</end>"
)
}
moderator = Moderator(
persona="an experienced editor specializing in mystery novels",
model="gpt-4o",
combination_instructions="Synthesize the plot, character, and setting elements into a cohesive story outline: <start>${previous_responses}</end>"
)
edges = [
('setting', 'character'),
('setting', 'plot'),
('character', 'plot')
]
story_dag = Graph(agents=agents, edges=edges, task=story_prompt, moderator=moderator)
story_dag.process()
print(story_dag.final_response)Sample 20 Americans from ANES survey data---each a real demographic profile, weighted for national representativeness---and run them as a parallel ensemble. See the Agents tutorial for an explanation of ANES personas.
from plurals.agent import Agent
from plurals.deliberation import Ensemble
task = "What would make commuting by bike more appealing to you? Be specific. You are in a focus group."
agents = [Agent(persona='random', model='gpt-4o') for _ in range(20)]
ensemble = Ensemble(agents=agents, task=task)
ensemble.process()
for r in ensemble.responses:
print(r)LLMs neutralizing biased text tend to rewrite entire sentences but human Wikipedia editors remove just a few words [1]. So how about the LLM generates 5 neutralizations and selects the one closest to the original by edit distance, a verifiable reward with no judge LLM needed. (Best-of-N can also be used inside Structures.)
See the tutorial on best-of-N and verifiable rewards.
[1] Ashkinaze, J., Guan, R., Kurek, L., Adar, E., Budak, C., & Gilbert, E. (2024). Seeing like an ai: How llms apply (and misapply) wikipedia neutrality norms. arXiv preprint arXiv:2407.04183.
# pip install editdistance
import editdistance
from plurals.agent import Agent
original = "He was a very, very good photographer. He also had to go to school, where he flourished achieving praise from his teachers."
def min_edit_dist(responses):
distances = [editdistance.eval(r, original) for r in responses]
return responses[distances.index(min(distances))]
agent = Agent(
task=f"Neutralize this text per Wikipedia's Neutral Point of View policy: {original}",
model="gpt-4o-mini",
num_responses=5,
response_selector=min_edit_dist,
kwargs={"temperature": 0.7}
)
response = agent.process()
print(f"Original: {original}")
print(f"Neutralized: {response}")
print(f"Edit distance: {editdistance.eval(original, response)}")Interview expands a seed into a full life-story by conducting a virtual interview with the Agent.
See the tutorial for more details on how to use Interview and how to generate interview questions from user input.
More broadly, simulated focus groups are a useful design pattern---where we construct either ANES or interview-based personas and then run them in an ensemble to give input, with a Moderator optionally summarizing the ensemble's responses.
from tqdm import tqdm
from plurals.agent import Agent
from plurals.interview import Interview
from plurals.deliberation import Ensemble, Moderator
seeds = [
"conservative farmer from rural Iowa",
"liberal professor from Boston",
"independent small-business owner from Nevada",
]
agents = []
for seed in tqdm(seeds, desc="Running interviews"):
interview = Interview(seed=seed, model="gpt-4o-mini")
interview.run_interview()
persona = interview.combined_response # full Q&A transcript from life-story interview questions
agents.append(Agent(persona=persona, model="gpt-4o-mini"))
moderator = Moderator(persona="default", model="gpt-4o")
ensemble = Ensemble(
agents=agents, moderator=moderator,
task="What would you want in a healthcare app? Answer in 200 words from your own, specific perspective."
)
ensemble.process()
print(ensemble.final_response)A Chain with combination_instructions='critique_revise', shuffle=True, and multiple cycles approximates random-network deliberation: over rounds each agent has likely critiqued every other agent's work, without any single voice anchoring the result.
See the Structures tutorial for more details on how to customize combination instructions and structure parameters. In general,
the Chain class with multiple cycles and Shuffling is surprisingly powerful!
from plurals.agent import Agent
from plurals.deliberation import Chain, Moderator
agents = [Agent(persona='random', model='gpt-4.1') for _ in range(5)]
moderator = Moderator(persona='default', model='claude-sonnet-4-6')
chain = Chain(
agents=agents,
task="Draft a one-paragraph community guideline for an online forum about AI.",
combination_instructions="critique_revise",
moderator=moderator,
shuffle=True,
cycles=3,
verbose=True
)
chain.process()
print(chain.final_response)This is a design pattern I call "diamond DAG":
- One agent produces an output.
- The initial output is critiqued from N orthogonal perspectives.
- The output is then re-written based on the critiques.
See the Structures tutorial for more details on DAGs.
from plurals.agent import Agent
from plurals.deliberation import Graph
task = "Write an NSF abstract for a project on using large language models to detect misinformation on social media."
agents = {
'proposer': Agent(
system_instructions="You are a senior academic researcher writing an NSF grant abstract.",
model="claude-sonnet-4-6"
),
'merit_critic': Agent(
system_instructions=(
"You are an NSF review panelist evaluating Intellectual Merit only. "
"Critique novelty, methodological rigor, team qualifications, and advancement of knowledge. "
"Do not comment on broader impact."
),
model="claude-sonnet-4-6",
combination_instructions="Critique ONLY the Intellectual Merit of this NSF abstract: <start>${previous_responses}</end>"
),
'impact_critic': Agent(
system_instructions=(
"You are an NSF review panelist evaluating Broader Impacts only. "
"Critique societal benefits, education and outreach, diversity, and infrastructure for future research. "
"Do not comment on intellectual merit."
),
model="claude-sonnet-4-6",
combination_instructions="Critique ONLY the Broader Impacts of this NSF abstract: <start>${previous_responses}</end>"
),
'rewriter': Agent(
system_instructions="You are a grants officer who has helped researchers win NSF awards for 20 years.",
model="claude-sonnet-4-6",
combination_instructions="The original abstract and two NSF reviewer critiques are below. Rewrite to address both Intellectual Merit and Broader Impacts: <start>${previous_responses}</end>"
),
}
edges = [
('proposer', 'merit_critic'),
('proposer', 'impact_critic'),
('merit_critic', 'rewriter'),
('impact_critic','rewriter'),
]
graph = Graph(agents=agents, edges=edges, task=task, verbose=True)
graph.process()
graph.print_responses()Plurals is run by a small and energetic team of academics doing the best they can [1]. To report bugs or feature requests, open a GitHub issue. We strongly encourage you to use our Bug or Feature Request issue templates; these make it easy for us to respond effectively to the issue.
[1] Language adopted from (https://github.com/davidjurgens/potato).
-
Persona-based experiments (Ex: Create a panel of nationally representative personas)
-
Deliberation structure experiments (What are optimal information-sharing structures?)
-
Deliberation instruction experiments (What are optimal instructions for combining information?)
-
Agent-based models (Ex: understanding contagion in AI networks)
-
Curation (Ex: To what extent can Moderator LLMs filter and select the best outputs from other LLMs?)
-
Steerable guardrails (Ex: Can LLM deliberation steer abstentions?)
-
Persuasive messaging (Use many LLMs to collaboratively brainstorm and refine persuasive messaging for different audiences; Experiment with simulated focus groups)
-
Viewpoint augmentation (Provide varied perspectives and information from multiple agents)
-
Creative ideation (e.g., get ideas from multiple LLMs with different perspectives/roles for hypothesis generation, creative ideas, or product design)
If you are interested in collaborating, please reach out to Joshua Ashkinaze (jashkina@umich.edu). We are actively running both human and AI experiments around (1) how and when simulated social ensembles augment humans; (2) using Plurals for moderation.