A Guide on Configuring a Gradio Queue for High-Volume Traffic#2558
Conversation
|
All the demos for this PR have been deployed at https://huggingface.co/spaces/gradio-pr-deploys/pr-2558-all-demos |
… performance-guide
 freddyaboulton
left a comment
freddyaboulton
left a comment
There was a problem hiding this comment.
Awesome guide @abidlabs ! I love the structure and concrete recommendations. Noticed a couple of typos but that's about it.
Is it worth mentioning api_open in the sense that "closing" the api may help with scaling by making sure the queue isn't skipped?
|
|
||
| If you write your function to process a batch of samples, Gradio will automatically batch incoming requests together and pass them into your function as a batch of samples. You need to set `batch` to `True` (by default it is `False`) and set a `max_batch_size` (by default it is `4`) based on the maximum number of samples your function is able to handle. These two parameters can be passed into `gr.Interface()` or to an event in Blocks such as `.click()`. | ||
|
|
||
| While setting a batch is conceptually similar to having workers process requests in parallel, it is often *faster* than setting the `concurrency_count` for deep learning models. The downside is that you might need to adapt your function a little bit to accept batches of samples instead of individual samples. |
There was a problem hiding this comment.
Do we have an answer as to whether concurrency_count plays well on gpus?
I wonder if we should mention that concurrency_count is better suited to IO-bound demos and batch_size is better suited to CPU/GPU bound demos. You kind of hint at that below where you say that high batch size likely means that concurrency count should be set to 1.
There was a problem hiding this comment.
I assigned a GPU to this Space and it seems to work just fine: https://huggingface.co/spaces/abidlabs/image-classifier. Specifically, I was able to process requests in parallel and cut the latency in half on average by using concurrency_count=2!
A user just needs to keep in mind that their GPU memory might be different than their CPU memory so they need to ensure that multiple workers will not OOM their GPU. I'll add a note in the hardware section
|
Thanks for the review @freddyaboulton! Will fix the typos and add a section on |
|
@aliabd I'm getting a weird behavior when I try to add my Guide to the
What's weird is that if I remove my additional guide from the
Even though the Guides: quickstart, key_features, sharing_your_app, interface_state, reactive_interfaces, advanced_interface_featuresDo you know what might be going on? |
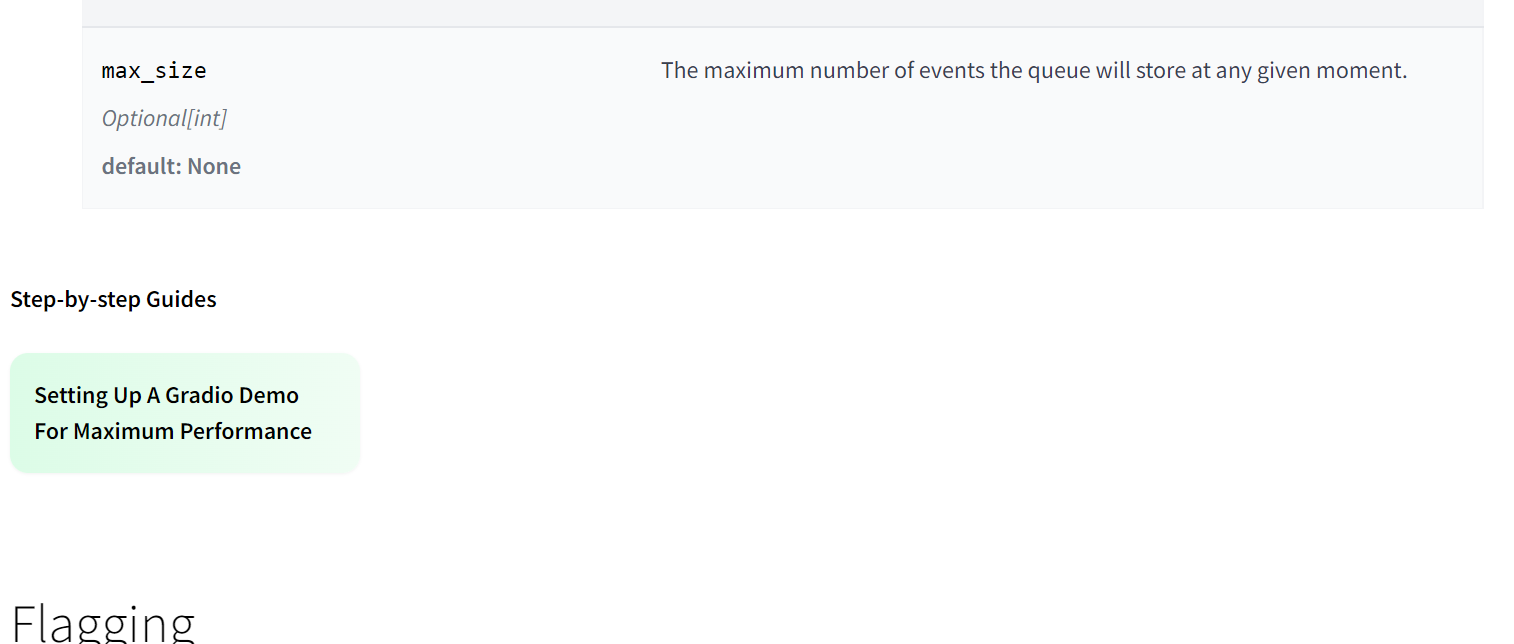
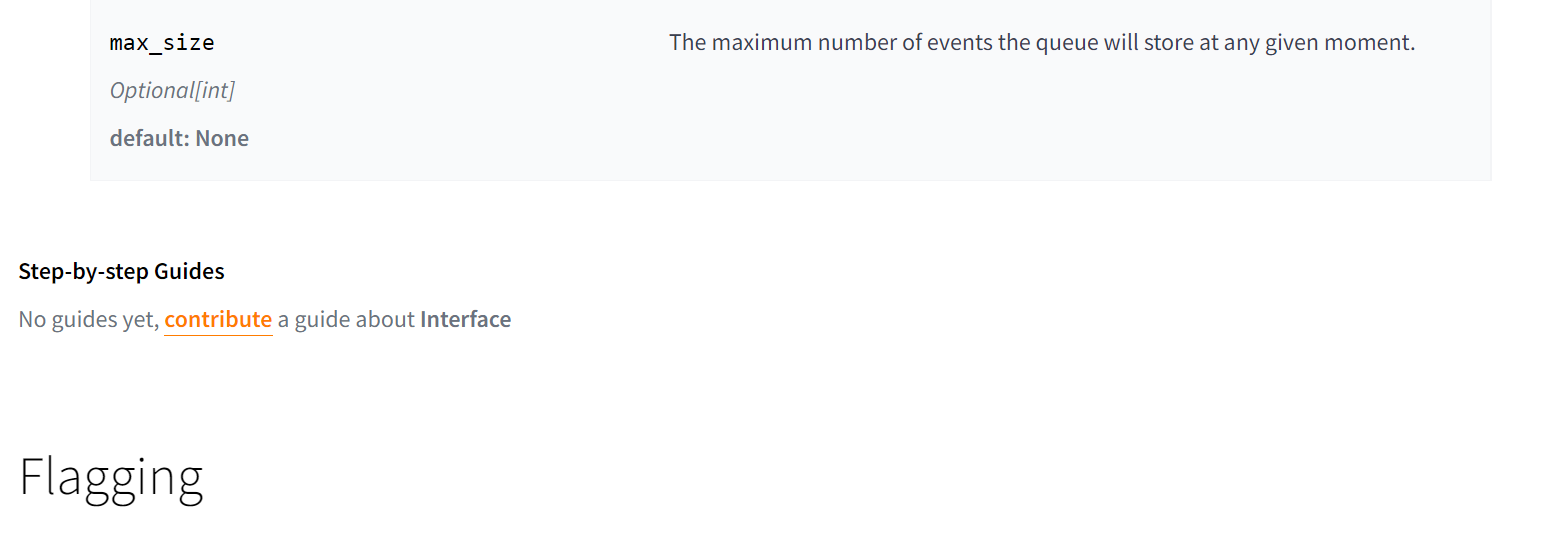
|
|
||
| So why not set this parameter much higher? Keep in mind that since requests are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the the `concurrency_count` too high. | ||
|
|
||
| **Recommendation**: Increase the `concurrency_count` parameter as high as you can until you hit memory limits on your machine. You can [read about Hugging Face Spaces machine specs here](https://huggingface.co/docs/hub/spaces-overview). |
There was a problem hiding this comment.
Hello @abidlabs, a beautiful guide as always, good work!
IMO this recommendation is not a good one, because increasing concurrency does not directly translate into performance due to various reasons as costs associated with context switching and GIL limitations. So I would suggest to change it to smt like,
'Increase concurrency as long as you see improvement in the throughput.'
There was a problem hiding this comment.
Ah I see, thanks for the suggestion @farukozderim! I'll update the Guide to reflect that
Uh oh!
There was an error while loading. Please reload this page.